







切换用户执行命令
su - jhdcp -c "bash -c /jhmk/jhdcp/dolphinscheduler-3.2.1-bin/1.sh"
shell
<< EOF 追加
export OCP_CONFIG_PROPERTIES=`cat << EOF
server.port:8080
ocp.site.url:http://xxx.xxx.xxx.xxx:8080
obsdk.ob.connection.mode:direct
EOF
`

tar -zxvf
time stamp xxx in the future
tar: fe/spark-dpp/spark-dpp-1.0.0-jar-with-dependencies.jar: time stamp 2024-01-03 21:12:08 is 23413.694397417 s in the future

md5sum 判断文件是否正确上传
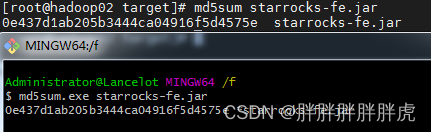
ulimit: open files: cannot modify limit: Operation not permitted
[hadoop@hadoop03 bin]$ cat /etc/security/limit.conf
cat: /etc/security/limit.conf: No such file or directory
[hadoop@hadoop03 bin]$ vim /etc/security/limit.conf
[hadoop@hadoop03 bin]$ echo ulimit -n 65536
ulimit -n 65536
[hadoop@hadoop03 bin]$ sudo vim /etc/security/limit.conf
[hadoop@hadoop03 bin]$ sudo vim /etc/security/limits.d/20-nproc.conf
[hadoop@hadoop03 bin]$ pwd
/opt/module/StarRocks-3.2.0-rc01/be/bin
[hadoop@hadoop03 bin]$ ./start_be.sh --daemon
/opt/module/StarRocks-3.2.0-rc01/be/bin/start_backend.sh: line 184: ulimit: open files: cannot modify limit: Operation not permitted
[hadoop@hadoop03 bin]$ ulimit -n 65536
-bash: ulimit: open files: cannot modify limit: Operation not permitted
[hadoop@hadoop03 bin]$ sudo ulimit -n 65536
sudo: ulimit: command not found
[hadoop@hadoop03 bin]$ sudo echo ulimit -n 65536
ulimit -n 65536
[hadoop@hadoop03 bin]$ ./start_be.sh --daemon
/opt/module/StarRocks-3.2.0-rc01/be/bin/start_backend.sh: line 184: ulimit: open files: cannot modify limit: Operation not permitted
[hadoop@hadoop03 bin]$ ulimit -a | grep "open files"
open files (-n) 1024
[hadoop@hadoop03 bin]$ su
Password:
[root@hadoop03 bin]# ulimit -a | grep "open files"
open files (-n) 65536
[root@hadoop03 bin]# su hadoop
[hadoop@hadoop03 bin]$ ulimit -n 65536
[hadoop@hadoop03 bin]$ pwd
/opt/module/StarRocks-3.2.0-rc01/be/bin
[hadoop@hadoop03 bin]$ ./start_be.sh --daemon
[hadoop@hadoop03 bin]$ ulimit -a | grep "open files"
open files (-n) 65536
[hadoop@hadoop03 bin]$ cat /etc/security/limit.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
[hadoop@hadoop03 bin]$ cat /etc/security/limits.d/20-nproc.conf
# Default limit for number of user's processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning.
* soft nproc 4096
root soft nproc unlimited
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
expect 交互
expect <<EOF
# start kafka cluster
spawn su - hadoop -c "/usr/local/bin/kf.sh start"
expect {
"Password:" { send "123456\n";exp_continue}
}
expect eof
EOF
expect <<EOF
spawn ssh-keygen -t rsa
expect {
"*id_rsa):" {
send "\n";
exp_continue;
}
"*(y/n)?" {
send "y\n";
}
"*passphrase):" {
send "\n";
exp_continue;
}
"*again:" {
send "\n";
exp_continue;
}
eof
}
expect eof
EOF
while
while true
do
hcount=`ps aux | grep HMaster | wc -l`
if [ $hcount == 2 ];then
echo "hbase service start..."
break
else
bash -c "nohup /opt/module/hbase/bin/hbase-daemon.sh --config /opt/module/hbase/conf foreground_start master &"
bash -c "/opt/module/hbase/bin/hbase-daemons.sh start regionserver"
sleep 10
continue
fi
done
awk
- xargs
- if “abcd”
kubectl get po | grep mysql-server-deployment-dbapi | awk '{if($3 != "Running"){print $1 }}' | xargs kubectl delete po
### if 正则匹配
[root@bigdata-master-01 ~]# hdfs dfs -ls /v2xRTData | awk '{if($8 ~ ".*2023-06.*")print $8}'
/v2xRTData/day=2023-06-01
/v2xRTData/day=2023-06-02
...
/v2xRTData/day=2023-06-29
/v2xRTData/day=2023-06-30
- 求和 / 行数
[root@bigdata-master-01 ~]# hdfs dfs -du -h /v2xRTData | awk '{if($3 ~ ".*2023-06.*")print $1}' | awk '{sum+=$1}END {print "Sum = " sum ", NR = " NR}'
Sum = 130.3, NR = 30
shell 正则符号表达式
Shell的正则表达式入门、常规匹配、特殊字符:^、$、.、*、字符区间(中括号):[ ]、特殊字符:\、匹配手机号
系统版本
[hadoop@hadoop01 ~]$ cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
[hadoop@hadoop01 ~]$ uname -r
3.10.0-1160.49.1.el7.x86_64
lsof -i:8040
[hadoop@hadoop03 starrocks]$ lsof -i:8040
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 25573 jhdcp 484u IPv4 2607978710 0t0 TCP *:ampify (LISTEN)
sed 替换
sed -i "s/fs.defaultFS=.*$/fs.defaultFS=hdfs:\/\/hdfs-namenode-service:9000/g" /opt/dolphinscheduler/conf/common.properties
### 在 yaml 中需要用到反斜杠
sed -i \"s/fs.defaultFS=.*$/fs.defaultFS=hdfs:\\/\\/hdfs-namenode-service:9000/g\" /opt/dolphinscheduler/conf/common.properties
变量命令
###
变量名必须是以字母或下划线字符“_”开头,后面跟字母、数字或下划线字符。不要使用?、*或其他特殊字符命名你的变量。
注意:
变量名和等号之间不能有空格;
首个字符必须为字母(a-z A-Z)
中间不能有空格,可以是下划线
不能使用标点符号
不能使用bash里的关键字
去除首尾
cat | head -n -1 | tail -n +2
0、字符串转数字
# echo "1672179040"| awk '{print int($0)}'
1672179040
##############################
# a="024"
# echo $a | bc -l
24
1、替换迭代目录字符串
find k8s -type f -name '*.yaml' -print |xargs sed -i "s/k8s.node.master.01/sealos-k8s-node-01/g"
find 命令栗子:https://blog.csdn.net/weixin_35266799/article/details/116580662
-type TYPE:
f: 普通文件
d: 目录文件
l:符号链接文件
b:块设备 文件
c:字符设备文件
p:管道文件
s:套接字文件
组合测试:
与:-a, 默认组合逻辑;
或:-o,满足条件其中之一
非:-not, !
!A -a !B = !(A -o B)
!A -o !B = !(A -a B)
find demo
查找/usr目录下不属于root, bin或hadoop的所有文件或目录
find /usr -not -user root -a -not -user bin -a -not -user hadoop -ls
2、获取网卡名称
# cat /proc/net/dev | awk '{i++; if(i>2){print $1}}' | sed 's/^[\t]*//g' | sed 's/[:]*$//g'
lo
virbr0-nic
virbr0
ens33
docker0
###
解释:
(1) /proc/net/dev是给用户读取或更改网络适配器及统计信息的方法;
(2) awk '{i++; if(i>2){print $1}}'命令是从第二行开始循环获取第一列数据;
(3) sed 's/^[\t]*//g'命令为去除行首的空格;
(4) sed 's/[:]*$//g'命令为去除行尾的":"字符.
3、获取主机名
ping $HOSTNAME -c 1 | grep PING | awk '{print $2}'
4、Linux 环境下删除文件 ^M 符号
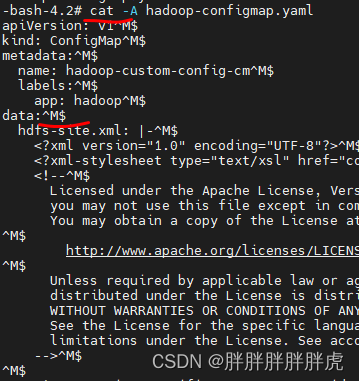
cat hadoop-configmap.yaml | tr -s "\r" "\n" > new_file
5、grep 过滤
# grep -vE '^#|^$' sql-client-defaults.yaml | grep -v '^ #'
tables: [] # empty list
functions: [] # empty list
catalogs: # empty list
- name: hive_catalog
type: hive
hive-conf-dir: /etc/hive/conf/
default-database: default
execution:
planner: blink
type: streaming
time-characteristic: event-time
periodic-watermarks-interval: 200
result-mode: table
max-table-result-rows: 1000000
parallelism: 1
max-parallelism: 128
min-idle-state-retention: 0
max-idle-state-retention: 0
current-catalog: hive_catalog
current-database: default
restart-strategy:
# strategy type
# possible values are "fixed-delay", "failure-rate", "none", or "fallback" (default)
type: fallback
deployment:
response-timeout: 5000
gateway-address: ""
gateway-port: 0
‘^#’ 表示 #开头,
‘^ #’ 表示 ’ #‘ 开头
‘^$’ 表示空行
-E表示或
- grep 过滤掉注释行与空行
cat atlas-application.properties | grep -Ev '^$|#'
-v 反向查询
-E 或
grep -vE '^#|$' xxx.properties
# 不区分大小写
grep -i xxx
grep 递归查询目录下所有文件内容
[root@k8s-master-01 k8s]# pwd
/opt/module/k8s
[root@k8s-master-01 k8s]# grep -rnR "zookeeper" *
Binary file dlink/dlink-admin-0.6.5-SNAPSHOT.jar matches
dolphinscheduler/config.env.sh:41:REGISTRY_PLUGIN_NAME=zookeeper
dolphinscheduler/dolphinscheduler-configmap.yaml:15: ZOOKEEPER_QUORUM: "kafka-zookeeper-headless:2181"
dolphinscheduler/dolphinscheduler-configmap.yaml:16: REGISTRY_PLUGIN_NAME: "zookeeper"
dolphinscheduler/dolphinscheduler-configmap.yaml:17: REGISTRY_SERVERS: "kafka-zookeeper-headless:2181"
flink/flink-configuration-configmap.yaml:20: #high-availability: zookeeper
flink/flink-configuration-configmap.yaml:21: #high-availability.zookeeper.quorum: zk-service.flink.svc.cluster.local:2181
flink/flink-configuration-configmap.yaml:22: #high-availability.zookeeper.path.root: /flink
flink/flink-configuration-configmap.yaml:24: #high-availability.zookeeper.storageDir: file:///opt/flink/data/ha
flink/flink-configuration-configmap.yaml:46: logger.zookeeper.name = org.apache.zookeeper
flink/flink-configuration-configmap.yaml:47: logger.zookeeper.level = INFO
flink/flink-configuration-configmap.yaml:123: logger.zookeeper.name = org.apache.zookeeper
flink/flink-configuration-configmap.yaml:125: logger.zookeeper.level = INFO
6、/bin/bash^M: bad interpreter: No such file or directory
:set ff=unix
7、sheep 无限休眠
sleep infinity
8、切分字符串
https://www.jb51.net/article/186276.htm
#!/bin/bash
string="one,two,three,four,five"
array=(`echo $string | tr ',' ' '` )
for var in ${array[@]}
do
echo $var
done
#!/bin/bash
string="hello,shell,haha"
OLD_IFS="$IFS"
IFS=","
array=($string)
IFS="$OLD_IFS"
for var in ${array[@]}
do
echo $var
done
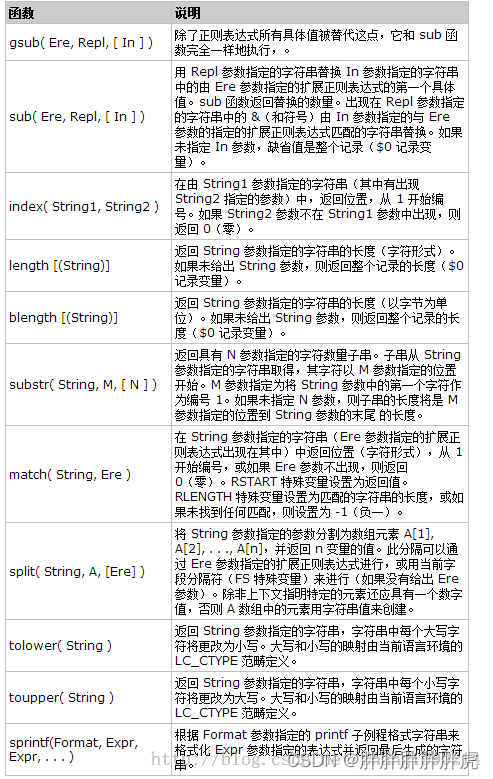
9、awk
awk 字符串函数
sudo docker ps -a | awk '$1!="CONTAINER" {print $1}' | xargs sudo docker rm
# 替换行 AAA 为 BBB
awk '{ sub(/AAAA/,"BBBB"); print $0 }' t.txt
### 替换m 为 1
### 替换h 为 10
### 替换d 为 100
### 替换y 为 1000
[root@k8s-master-01 module]# kubectl get po | grep glusterfs | awk '{if($5 ~ /^\(/) print $1","$3","$4","substr($5,2,length($5)) "," length(substr($5,2,length($5)))}' | awk -F, '{print $1 "," $2 "," $3 "," gsub(/m/,1,$4) "," $4}' |awk -F, '{print $1 "," $2 "," $3 "," gsub(/h/,10,$5) "," $5}' | awk -F, '{print $1 "," $2 "," $3 ","gsub(/d/,100,$5)","$5}' | awk -F, '{print $1 "," $2 "," $3 ","gsub(/y/,1000,$5)","$5}' | awk -F, '{print $1 "," $2 "," $3 ","$5}' | sort -n -k 4 -t ,
glusterfs-grbng,Running,2,2100110
glusterfs-b5t77,Running,1,7100910
# kubectl get po | grep glusterfs | awk '{if($5 ~ /^\(/) print substr($5,2,length($5))}'|uniq
6d11h
28h
# kubectl get po | grep glusterfs | awk '{if($5 ~ /^\(/) print substr($5,2,length($5))}'|uniq | sort | awk 'NR == 1 {print $1}'
28h
### 按照glusterfs pod 重启时长升序排列
# kubectl get po | grep glusterfs | awk '{if($5 ~ /^\(/) print substr($5,2,length($5)) "|" length(substr($5,2,length($5)))}' | sort -t \| -k 2 | awk '{split($1, a, "|"); print a[1]}'
29h
6d12h
- NR==1 第一行
# kubectl get po | grep glusterfs | awk '{if($5 ~ /^\(/) print substr($5,2,length($5)) "|" length(substr($5,2,length($5)))}' | sort -t \| -k 2 | awk 'NR==1 {split($1, a, "|"); print a[1]}'
29h
sort
ps aux | sort -k4nr | head -n 5
-k 按指定的列进行排序
-n 按数值大小排序
-r 降序排序
cut
截取字符串
[root@k8s-master-01 module]# a="aaa,bbb,ccc"
[root@k8s-master-01 module]# echo $a | cut -d, -f1,3
aaa,ccc
[root@k8s-master-01 module]# echo $a | cut -d, -f2
bbb
10、文件头添加内容
### i 添加
### d 删除
sed -i "1i create database dbapi;use dbapi;" ddl_mysql.sql
sed -i "1d" ddl_mysql.sql
11、grep 过滤掉内容注释行与空行
cat log4j.properties | grep -v '^#' | grep -v ^$
12、修改文件句柄 too many open files
修改文件句柄数
1)查看并修改当前交互终端的limit值 (临时修改)
#查询当前终端的文件句柄数:
ulimit -n
#修改文件句柄数为65535
ulimit -n 65535
2)将ulimit 值添加到/etc/profile文件中(适用于有root权限登录的系统,永久修改)
为了每次系统重新启动时,都可以获取更大的ulimit值,将ulimit 加入到/etc/profile 文件底部。
echo ulimit -n 65535 >>/etc/profile
source /etc/profile #加载修改后的profile
ulimit -a #显示65535
13)去除字符串最后一个字段
https://blog.51cto.com/u_15127702/3374982?abTest=51cto
# head -5 customer_address.dat |sed 's/.$//'
1|AAAAAAAABAAAAAAA|18|Jackson |Parkway|Suite 280|Fairfield|Maricopa County|AZ|86192|United States|-7|condo
2|AAAAAAAACAAAAAAA|362|Washington 6th|RD|Suite 80|Fairview|Taos County|NM|85709|United States|-7|condo
3|AAAAAAAADAAAAAAA|585|Dogwood Washington|Circle|Suite Q|Pleasant Valley|York County|PA|12477|United States|-5|single family
4|AAAAAAAAEAAAAAAA|111|Smith |Wy|Suite A|Oak Ridge|Kit Carson County|CO|88371|United States|-7|condo
5|AAAAAAAAFAAAAAAA|31|College |Blvd|Suite 180|Glendale|Barry County|MO|63951|United States|-6|single family
14)curl 管道
-T -
# cat customer_address.dat | sed 's/.$//' | curl --location-trusted -u root:123456 -H "label:customer_address2" -H "timeout:1200" -H "column_separator:|" -T - http://172.16.34.127:32030/api/test_db/customer_address/_stream_load
{
"TxnId": 58492,
"Label": "customer_address2",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 50000,
"NumberLoadedRows": 50000,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 5452165,
"LoadTimeMs": 706,
"BeginTxnTimeMs": 2,
"StreamLoadPutTimeMs": 3,
"ReadDataTimeMs": 15,
"WriteDataTimeMs": 686,
"CommitAndPublishTimeMs": 13
}
15)查看十六进制文件
hexdum -C pool_content
###
#vim 查看
:%!xxd
16、Linux 搭建CA证书服务器
https://blog.csdn.net/kaml200626/article/details/125533948
17、删除 jar 指定内容
例子: 删除 flink-shaded-hadoop 中 servlet 及子内容
[root@k8s-master-01 module]# zip -d flink-shaded-hadoop-2-uber-2.7.5-9.0.jar javax/servlet/\*
deleting: javax/servlet/
deleting: javax/servlet/Filter.class
deleting: javax/servlet/FilterChain.class
deleting: javax/servlet/FilterConfig.class
deleting: javax/servlet/GenericServlet.class
deleting: javax/servlet/LocalStrings.properties
deleting: javax/servlet/LocalStrings_fr.properties
deleting: javax/servlet/LocalStrings_ja.properties
deleting: javax/servlet/RequestDispatcher.class
...
18、配置 Linux 时区
rm -f /etc/localtime && ln -sv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone
19、字符串截取
https://blog.csdn.net/nansen0324/article/details/124661903
a1="yarn-resourcemanager-0|Running"
### 从左边开始截取
[root@k8s-master-01 module]# echo ${a1%%|*}
yarn-resourcemanager-0
### 从右边开始截取
[root@k8s-master-01 module]# echo ${a1##*|}
Running
#/bin/bash
glusterfs_pods_status=$(kubectl get po | grep glusterfs | awk '{print $3}' | uniq)
other_pods_status=$(kubectl get po | grep -v glusterfs | awk 'NR !=1 {print $1 "|" $3}')
###gluterfs pod状态done
for i in $glusterfs_pods_status;
do
if [ "$i" = "Running" ];
then
glusterfs_pod_restart_flag="true"
break
fi
done
### glusterfs 某个pod发生重启
if [ "$glusterfs_pod_restart_flag" = "true" ];then
for i in $other_pods_status;
do
if [ ${i##*|} = "Running" ];
then
echo "==================="
echo "重启pod:" ${i%%|*}
else
echo $i
fi
done
fi
20、空格
https://blog.csdn.net/sum_tw/article/details/52134864
- 1.定义变量时,
=号的两边不可以留空格.
gender=femal————right
gender =femal———–wrong
gender= femal———–wrong
gender= test————right ###左边是命令的话=号的右边有空格是正确的=左边不能有空格
gender = test ———wrong 等号=左边必须要有空格
- 2.条件测试语句 [ 符号的两边都要留空格.
if [ $gender = femal ]; then——-right.
echo "you are femal";
fi
if[ $gender...-----------------------wrong
if [$gender...----------------------wrong.
- 3.条件测试的内容,如果是字符串比较的话, 比较符号两边要留空格!
if [ $gender = femal ]; then——-right.
if [ $gender= femal ]; then——–wrong.
if [ $gender=femal ]; then———wrong.
- 4.如果if 和 then写在同一行, 那么,注意, then的前面要跟上 ; 号.如果 then 换行写, 那么也没问题.
if [ $gender = femal ]; then——-right.
###
if [ $gender = femal ]
then——————————-right.
###
if [ $gender = femal ] then——-wrong. then前面少了 ; 号.
提示出错信息:syntax error near unexpected token then
同理,还有很多出错信息 比如
syntax error near unexpected token fi 等都是这样引起的。
- 5.
if后面一定要跟上then. 同理
elif后面一定要跟上then.
不然提示出错信息:syntax error near unexpected token else
if语句后面需要跟着then,同时前面要有分号;- 空格非常重要,shell 会认为空格前的为一个命令,如果a=3 认为是赋值操作,如果写成a = 3,那么就会认为a为一个命令 this=
ls -l |grep ‘^-' | wc -l - 操作符之间要用空格分开 ,如
test ! -d $1,其中的!和-d就要用空格分开
空格是命令解析中的重要分隔符
-
- 命令和其后的参数或对象之间一定要有空格
if [ -x"~/Workspace/shell/a.sh" ];then
只有 -x 后有空格才表示紧跟其后的字符串是否指向一个可执行的文件名,否则就成了测试 -x"~/Workspace/shell/a.sh" 这个字符串是不是空。
- 7.取变量值的符号’$'和后边的变量或括号不能有空格
21、引号
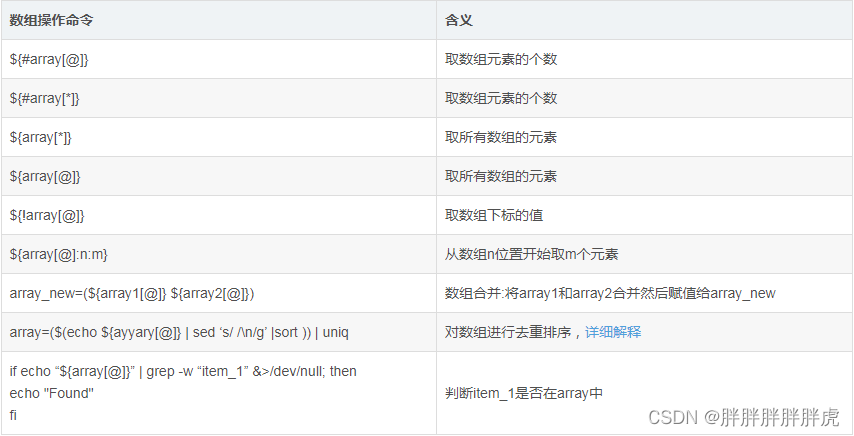
22、map
https://www.cnblogs.com/qq931399960/p/10786362.html
#/bin/bash
declare -A map
while true
do
glusterfs_pods_status=$(kubectl get po | grep glusterfs | awk '{if($5 ~ /^\(/) print $1","$3","$4","substr($5,2,length($5)) "," length(substr($5,2,length($5)))}' | sort -t , -k 5 | awk 'NR==1 {print $0}')
other_pods_status=$(kubectl get po | grep -v glusterfs | awk 'NR !=1 {print $1 "|" $3}')
for i in $glusterfs_pods_status; ###监控gluterfs pod状态变化
do
status=`echo $i|cut -d, -f2 `
if [ $status != "Running" ];
then
#echo ${map[@]}
glusterfs_pod_restart_flag="true"
break
else
echo `date`
#echo ${map[`echo $i |cut -d, -f1`]}
if [ ${map[`echo $i |cut -d, -f1`]}"" != `echo $i |cut -d, -f3`"" ];
then
echo "数量不一致..."${map[`echo $i |cut -d, -f1`]}
map[`echo $i |cut -d, -f1`]=`echo $i |cut -d, -f3`
glusterfs_pod_restart_flag="true"
break
fi
fi
done
sleep 5
done
#!/bin/bash
declare -A map
map["key1"]="value1"
map["key2"]="value2"
map["key3"]="value3"
# 遍历map,此map其实就是数组,其相关操作同上面数组的操作
for key in ${!map[@]};do
echo "key: "${key}" value:"${map[${key}]}
done
mpstat 命令——系统调优
https://blog.csdn.net/weixin_51099370/article/details/124987347
[hadoop@hadoop03 bin]$ mpstat 1 10
Linux 3.10.0-514.el7.x86_64 (hadoop03) 02/22/2024 _x86_64_ (2 CPU)
11:14:12 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:14:13 AM all 78.57 0.00 13.78 2.55 0.00 1.02 0.00 0.00 0.00 4.08
11:14:14 AM all 72.87 0.00 15.43 0.53 0.00 0.53 0.00 0.00 0.00 10.64
11:14:15 AM all 71.68 0.00 17.34 0.00 0.00 0.58 0.00 0.00 0.00 10.40
11:14:16 AM all 68.75 0.00 9.09 0.57 0.00 1.14 0.00 0.00 0.00 20.45
11:14:17 AM all 78.77 0.00 12.85 0.56 0.00 0.00 0.00 0.00 0.00 7.82
11:14:18 AM all 44.94 0.00 19.62 3.80 0.00 1.90 0.00 0.00 0.00 29.75
11:14:19 AM all 69.41 0.00 15.88 1.18 0.00 1.76 0.00 0.00 0.00 11.76
11:14:20 AM all 55.13 0.00 12.18 0.00 0.00 1.92 0.00 0.00 0.00 30.77
11:14:21 AM all 49.18 0.00 8.20 0.55 0.00 1.09 0.00 0.00 0.00 40.98
11:14:22 AM all 88.27 0.00 6.63 1.02 0.00 0.00 0.00 0.00 0.00 4.08
Average: all 68.45 0.00 12.96 1.07 0.00 0.96 0.00 0.00 0.00 16.56
最占用内存的进程
[root@k8s-compute-01 ~]# ps aux | sort -k4nr | head -n 5
root 14103 0.6 5.2 6969560 853364 ? Sl Oct14 101:50 /usr/local/openjdk-8/bin/java -Dlogging.config=classpath:logback-master.xml -Xms4g -Xmx4g -Xmn2g -server -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+PrintGCDetails -Xloggc:/opt/dolphinscheduler/logs/gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dump.hprof -XshowSettings:vm -Xms1g -Xmx1g -Xmn512m -XX:-UseContainerSupport -classpath /opt/dolphinscheduler/sql:/opt/dolphinscheduler/conf:/opt/dolphinscheduler/lib/* org.apache.dolphinscheduler.server.master.MasterServer
root 14216 0.1 4.9 6897896 805492 ? Sl Oct14 26:35 /usr/local/openjdk-8/bin/java -Dlogging.config=classpath:logback-worker.xml -Xms2g -Xmx2g -Xmn1g -server -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+PrintGCDetails -Xloggc:/opt/dolphinscheduler/logs/gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dump.hprof -XshowSettings:vm -Xms1g -Xmx1g -Xmn512m -XX:-UseContainerSupport -classpath /opt/dolphinscheduler/sql:/opt/dolphinscheduler/conf:/opt/dolphinscheduler/lib/* org.apache.dolphinscheduler.server.worker.WorkerServer
root 14168 0.1 4.8 6896348 793580 ? Sl Oct14 27:24 /usr/local/openjdk-8/bin/java -Dlogging.config=classpath:logback-worker.xml -Xms2g -Xmx2g -Xmn1g -server -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+PrintGCDetails -Xloggc:/opt/dolphinscheduler/logs/gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dump.hprof -XshowSettings:vm -Xms1g -Xmx1g -Xmn512m -XX:-UseContainerSupport -classpath /opt/dolphinscheduler/sql:/opt/dolphinscheduler/conf:/opt/dolphinscheduler/lib/* org.apache.dolphinscheduler.server.worker.WorkerServer
9999 107753 0.7 3.3 2631420 539324 ? Ssl Oct12 126:25 /usr/local/openjdk-8/bin/java -Xmx697932173 -Xms697932173 -XX:MaxDirectMemorySize=300647712 -XX:MaxMetaspaceSize=268435456 -Dfile.encoding=UTF-8 -Dlog.file=/opt/flink/log/flink--taskexecutor-0-flink-taskmanager-2.log -Dlog4j.configuration=file:/opt/flink/conf/log4j-console.properties -Dlog4j.configurationFile=file:/opt/flink/conf/log4j-console.properties -Dlogback.configurationFile=file:/opt/flink/conf/logback-console.xml -classpath /opt/flink/lib/antlr-runtime-3.5.2.jar:/opt/flink/lib/commons-codec-1.4.jar:/opt/flink/lib/commons-pool2-2.4.3.jar:/opt/flink/lib/dlink-connector-phoenix-1.13-0.6.1-SNAPSHOT.jar:/opt/flink/lib/druid-1.1.9.jar:/opt/flink/lib/fastjson-1.2.51.jar:/opt/flink/lib/flink-connector-hbase-2.2_2.11-1.13.5.jar:/opt/flink/lib/flink-connector-hbase-base_2.11-1.13.6.jar:/opt/flink/lib/flink-connector-hive_2.11-1.13.5.jar:/opt/flink/lib/flink-connector-jdbc_2.11-1.13.5.jar:/opt/flink/lib/flink-csv-1.13.5.jar:/opt/flink/lib/flink-doris-connector-1.13_2.11-1.0.3.jar:/opt/flink/lib/flink-format-changelog-json-2.1.1.jar:/opt/flink/lib/flink-json-1.13.5.jar:/opt/flink/lib/flink-metrics-prometheus_2.11-1.13.5.jar:/opt/flink/lib/flink-shaded-zookeeper-3.4.14.jar:/opt/flink/lib/flink-sql-connector-elasticsearch6_2.11-1.13.6.jar:/opt/flink/lib/flink-sql-connector-kafka_2.11-1.13.5.jar:/opt/flink/lib/flink-sql-connector-mongodb-cdc-2.1.1.jar:/opt/flink/lib/flink-sql-connector-mysql-cdc-2.1.1.jar:/opt/flink/lib/flink-statebackend-rocksdb_2.11-1.13.5.jar:/opt/flink/lib/flink-table-blink_2.11-1.13.5.jar:/opt/flink/lib/flink-table_2.11-1.13.5.jar:/opt/flink/lib/hive-exec-2.3.4.jar:/opt/flink/lib/hutool-all-5.7.14.jar:/opt/flink/lib/jedis-3.0.1.jar:/opt/flink/lib/kafka-clients-2.2.1.jar:/opt/flink/lib/libfb303-0.9.3.jar:/opt/flink/lib/log4j-1.2-api-2.16.0.jar:/opt/flink/lib/log4j-api-2.16.0.jar:/opt/flink/lib/log4j-core-2.16.0.jar:/opt/flink/lib/log4j-slf4j-impl-2.16.0.jar:/opt/flink/lib/mysql-connector-java-5.1.47.jar:/opt/flink/lib/phoenix-5.0.0-HBase-2.0-client.jar:/opt/flink/lib/phoenix-core-5.0.0-HBase-2.0-jar-with-dependencies-with-hbase-site.jar:/opt/flink/lib/flink-dist_2.11-1.13.5.jar:/etc/hadoop:/opt/hadoop-2.7.2/share/hadoop/common/lib/*:/opt/hadoop-2.7.2/share/hadoop/common/*:/opt/hadoop-2.7.2/share/hadoop/hdfs:/opt/hadoop-2.7.2/share/hadoop/hdfs/lib/*:/opt/hadoop-2.7.2/share/hadoop/hdfs/*:/opt/hadoop-2.7.2/share/hadoop/yarn/lib/*:/opt/hadoop-2.7.2/share/hadoop/yarn/*:/opt/hadoop-2.7.2/share/hadoop/mapreduce/lib/*:/opt/hadoop-2.7.2/share/hadoop/mapreduce/*:/opt/hadoop-2.7.2/contrib/capacity-scheduler/*.jar:/opt/hadoop-2.7.2/etc/hadoop: org.apache.flink.runtime.taskexecutor.TaskManagerRunner --configDir /opt/flink/conf -D taskmanager.memory.network.min=166429984b -D taskmanager.cpu.cores=4.0 -D taskmanager.memory.task.off-heap.size=0b -D taskmanager.memory.jvm-metaspace.size=268435456b -D external-resources=none -D taskmanager.memory.jvm-overhead.min=214748368b -D taskmanager.memory.framework.off-heap.size=134217728b -D taskmanager.memory.network.max=166429984b -D taskmanager.memory.framework.heap.size=134217728b -D taskmanager.memory.managed.size=665719939b -D taskmanager.memory.task.heap.size=563714445b -D taskmanager.numberOfTaskSlots=4 -D taskmanager.memory.jvm-overhead.max=214748368b
root 26941 0.1 3.2 9450364 524264 ? Sl Aug22 109:36 java -Dlogging.file=/opt/DBApi-2.3.2/bin/../logs/dbApi.log -classpath /opt/DBApi-2.3.2/bin/../conf:/opt/DBApi-2.3.2/bin/../lib/* com.gitee.freakchicken.dbapi.DBApiApplication
tr 命令
-C 反选
-s 去重
-t 替代
-d 删除
# echo "Linux 2015.9" | tr -C "[a-z][A-Z]" "#" | tr -s "#" | tr -t "#" "\n"
Linux
[root@prometheus-prometheus-server-57d46b46bf-txtwd wal]# echo "Linux 2015.9" | tr -d "[a-z][A-Z]"
2015.9
[root@prometheus-prometheus-server-57d46b46bf-txtwd wal]# echo "Linux 2015.9" | tr -d "[a-z][A-Z] "
2015.9
[root@prometheus-prometheus-server-57d46b46bf-txtwd wal]# echo "Linux 2015.9" | tr -d "[a-z][A-Z] [0-9]"
.
[root@prometheus-prometheus-server-57d46b46bf-txtwd wal]# echo "Linux 2015.9" | tr -d "[inux]"
L 2015.9
[root@prometheus-prometheus-server-57d46b46bf-txtwd wal]# echo "Linux 2015.9" | tr -d "[:lower:]"
L 2015.9
[root@prometheus-prometheus-server-57d46b46bf-txtwd wal]# echo "Linux 2015.9" | tr -d "[:upper:]"
inux 2015.9

进制转换
({0..1}{0..1}{0..1}{0..1}{0..1}{0..1}{0..1}{0..1})
参考:https://qa.1r1g.com/sf/ask/719495941/
### 这将创建一个00000000 00000001 00000010 ... 11111101 11111110 11111111带有bash 大括号扩展的数组.数组D2B中的位置表示其十进制值.
[root@k8s-master-01 ~]# D2B=({0..1}{0..1}{0..1}{0..1}{0..1}{0..1}{0..1}{0..1})
[root@k8s-master-01 ~]# echo ${D2B[7]}
00000111
[root@k8s-master-01 ~]# echo ${D2B[8]}
00001000
[root@k8s-master-01 ~]# echo ${D2B[1]}
00000001
[root@k8s-master-01 ~]# echo ${D2B[10]}
00001010
[root@k8s-master-01 ~]# echo ${D2B[255]}
11111111
[root@k8s-master-01 ~]# echo ${D2B[254]}
11111110
bc命令十进制转二进制
[root@k8s-master-01 ~]# echo "obase=2;ibase=10;254" | bc
11111110
[root@k8s-master-01 ~]# echo "obase=2;ibase=10;11" | bc -l
1011
[root@k8s-master-01 ~]# echo "obase=2;ibase=10;1000" | bc -l
1111101000
[root@k8s-master-01 ~]# echo "obase=2;ibase=10;10000000000000" | bc -l
10010001100001001110011100101010000000000000
sed
### sed正则替换
sed -i "s|tracker_server=.*$|tracker_server=${TRACKER_SERVER}|g" /etc/fdfs/storage.conf
nohup
###
nohup java -jar dataserver-2.0.5.RELEASE.jar > dataserver.log 2>&1 &
### 上面的2 和 1 的意思如下:
0 标准输入(一般是键盘)
1 标准输出(一般是显示屏,是用户终端控制台)
2 标准错误(错误信息输出)
创建hive时间范围分区
#/bin/bash
startDay="2022-12-05"
endDay="2023-02-10"
while [ $startDay != $endDay ]
do
for hour in $(seq 00 23)
do
hour01="0"$hour
if [ ${#hour01} == 2 ];then
echo ${startDay} $hour01
else
echo ${startDay} $hour
fi
done
startDay=`date -d "+1 day ${startDay}" +%Y-%m-%d` #关键步骤,获取第二天的时间
done
createrepo 离线yum源
yum install -y createrepo
createrepo /var/www/html/ceph
###
[ceph]
name=ceph-repo
baseurl=http://10.0.2.37:80/ceph/
gpgcheck=0
enabled=1 #很重要,1为启用。
shell read 命令

- read -a
# 获取字段值列表并检查字段类型是否正确
field_values=$(hive -e "SELECT my_field1, my_field2, my_field3 FROM ads_table")
regex='^[0-9]+$'
while read -a fields; do
if [[ ! ${fields[0]} =~ $regex ]]; then
echo "Invalid field type for my_field1: ${fields[0]}"
exit 1
elif [[ ! ${fields[1]} =~ $regex ]]; then
echo "Invalid field type for my_field2: ${fields[1]}"
exit 1
elif [[ ! ${fields[2]} =~ ^[a-zA-Z]+$ ]]; then
echo "Invalid field type for my_field3: ${fields[2]}"
exit 1
fi
done < <(echo "$field_values")
#!/bin/bash
# 获取字段值列表并检查字段类型是否正确
field_values="my_field1, my_field2, my_field3"
while read -a fields; do
echo ${fields[0]} ${fields[1]} ${fields[2]}
done < <(echo "$field_values")
Linux 创建 server
https://blog.csdn.net/weixin_46178937/article/details/126455240















 2857
2857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









