







数据结构

表结构
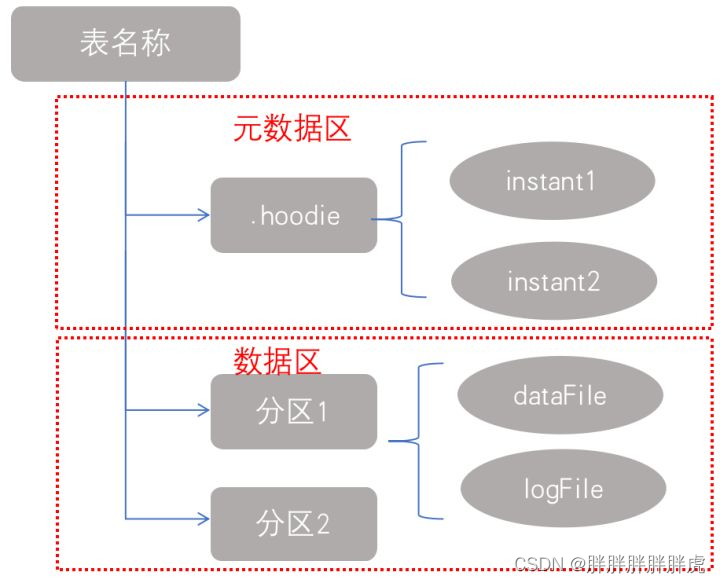
Hudi存储分为两个部分:
-
元数据:
.hoodie目录对应着表的元数据信息,包括表的版本管理(Timeline)、归档目录(存放过时的instant也就是版本),一个instant记录了一次提交(commit)的行为、时间戳和状态,hudi以时间轴的形式维护了在数据集上执行的所有操作的元数据; -
数据:
和hive一样,以分区方式存放数据;分区里面存放着Base File(.parquet)和Log File(.log.*);
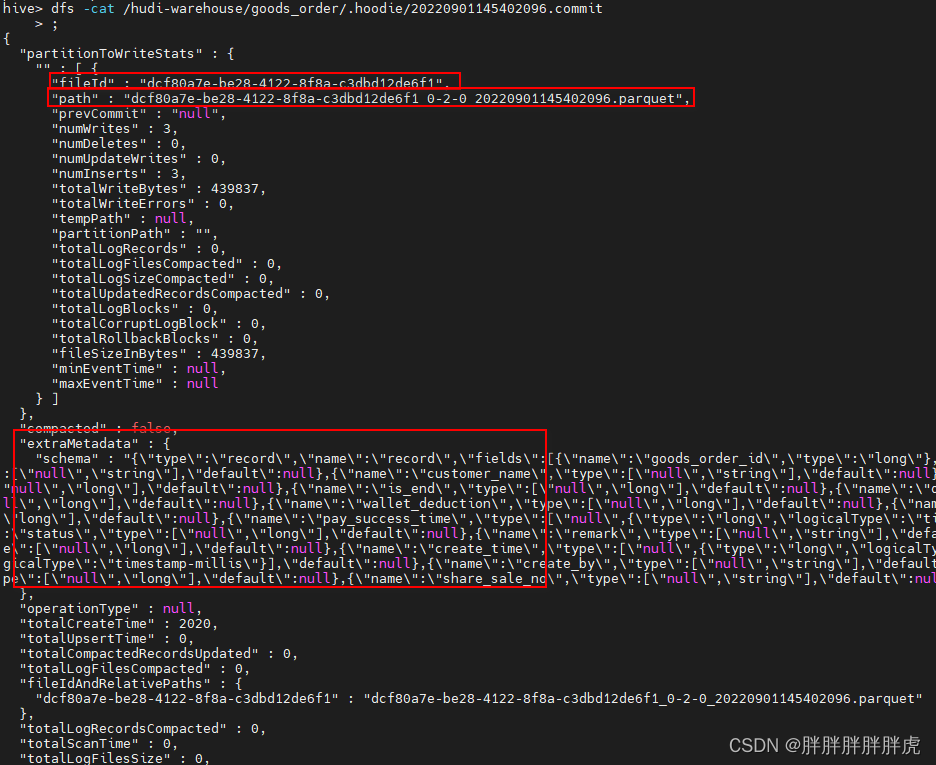
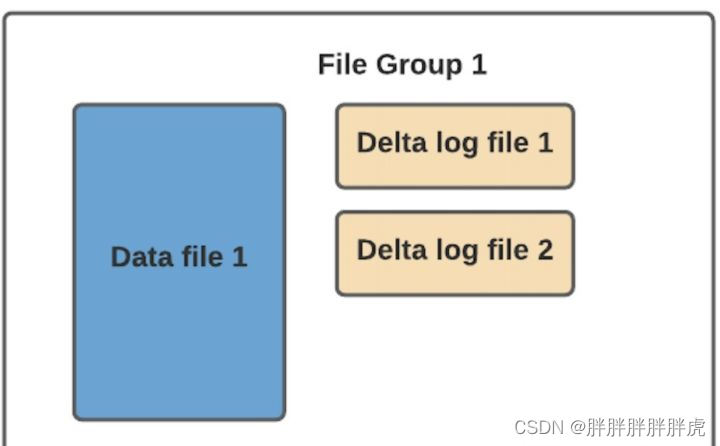
fileId:在每个分区内,文件被组织为File Group,由文件Id唯一标识。每个File Group包含多个File Slice,其中每个Slice包含在某个Commit或Compcation Instant时间生成的Base File(*.parquet)以及Log Files(*.log*),该文件包含自生成基本文件以来对基本文件的插入和更新;
path:对应着本次写入的文件路径,因为是MOR的表,所以写入的是日志文件;
prevCommit:上一次的成功Commit;
baseFile:基本文件,经过上一次Compaction后的文件,对于MOR表来说,每次读取的时候,通过将baseFile和logFiles合并,就会读取到实时的数据;
logFiles:日志文件,MOR表写数据时,数据首先写进日志文件,之后会通过一次Compaction进行合并;
compacted:本次操作是否为合并;
extraMetadata:元数据信息,如表Schema信息;
表类型
—>>> 一文彻底弄懂Apache Hudi不同表类型
hudi支持两种表类型:Copy On Write(COW) & Merge On Read(MOR)。
1.COW表:在数据写入的时候,通过复制旧文件数据并且与新写入的数据进行合并,对 Hudi 的每一个新批次写入都将创建相应数据文件的新版本。
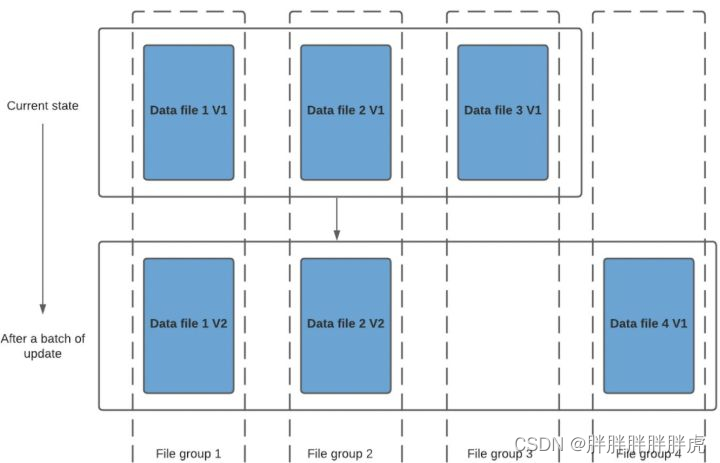
data_file1 和 data_file2 都将创建更新的版本,data file 1 V2 是数据文件 data file 1 V1 的内容与数据文件data file 1 中传入批次匹配记录的记录合并。
由于在写入期间进行合并,COW 会产生一些写入延迟。 但是COW 的优势在于它的简单性,不需要其他表服务(如压缩)
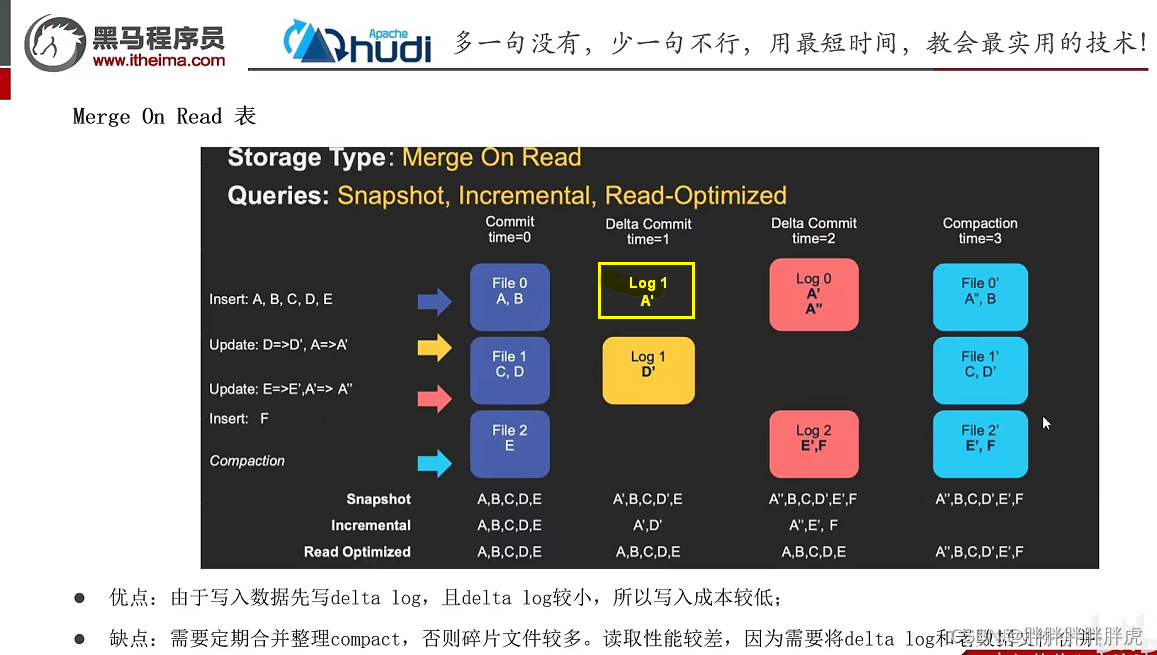
2.MOR表:对于具有要更新记录的现有数据文件,Hudi 创建增量日志文件记录更新数据。此在写入期间不会合并或创建较新的数据文件版本;在进行数据读取的时候,将本批次读取到的数据进行Merge。
Hudi 使用压缩机制来将数据文件和日志文件合并在一起并创建更新版本的数据文件。

hudi 表读写
https://blog.csdn.net/czmacd/category_11942229.html
hudi 数据写入
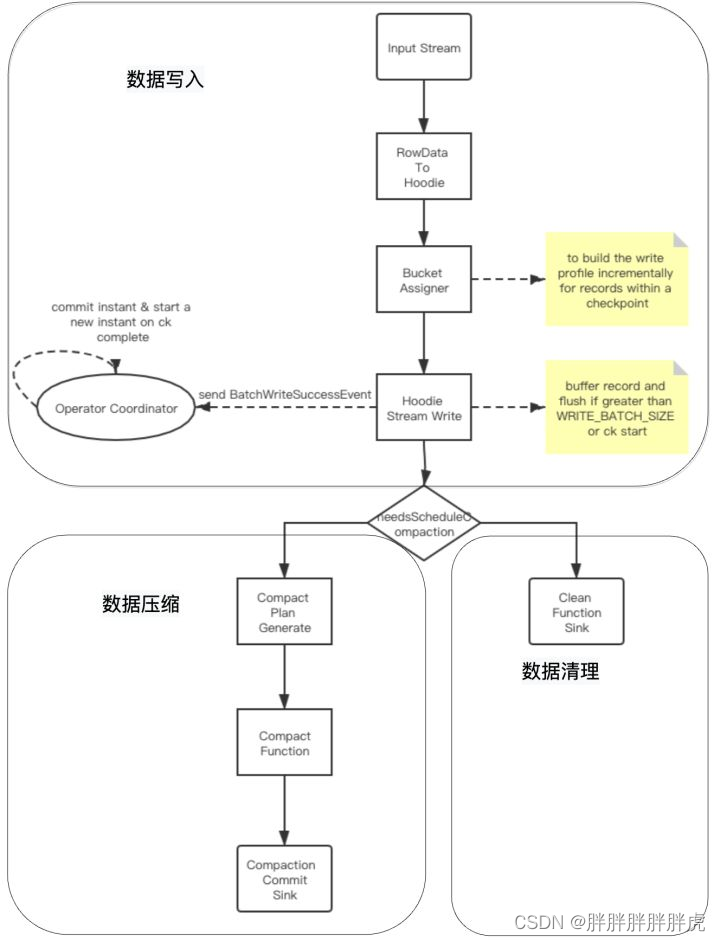
hudi与flink集成时流式数据写入过程分为三个模块:数据写入、数据压缩,数据清理
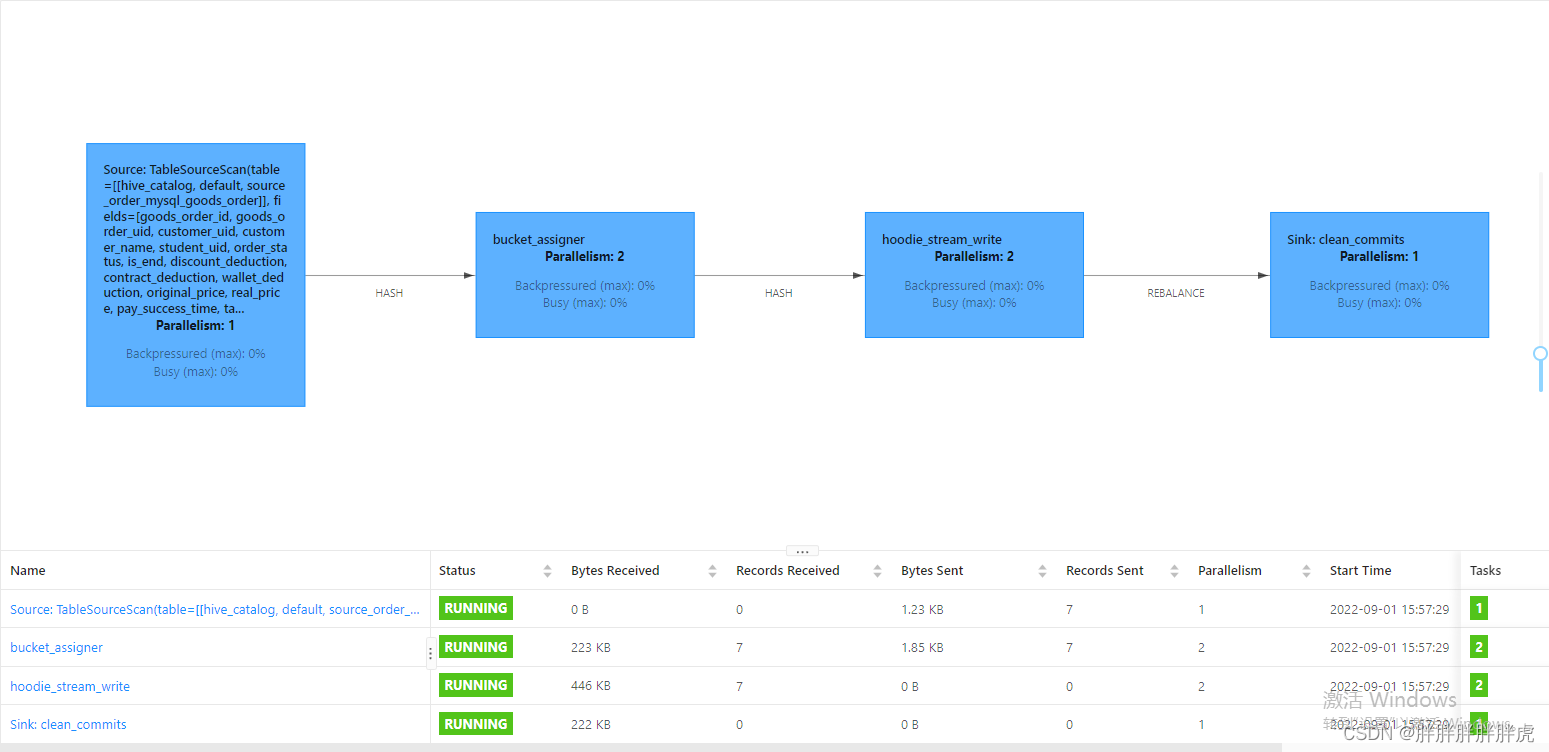
- 数据写入分析
(1)基础数据封装:将数据流中flink的RowData封装成Hoodie实体;
(2)BucketAssigner:桶分配器,主要是给数据分配写入的文件地址:
若为插入操作,则取大小最小的FileGroup对应的FileId文件内进行插入;在此文件的后续写入中文件 ID 保持不变,并且提交时间会更新以显示最新版本。这也意味着记录的任何特定版本,给定其分区路径,都可以使用文件 ID 和 instantTime进行唯一定位;
若为更新操作,则直接在当前location进行数据更新;
(3)Hoodie Stream Writer: 数据写入,将数据缓存起来,在超过设置的最大flushSize或是做checkpoint时进行刷新到文件中;
(4)Oprator Coordinator:主要与Hoodie Stream Writer进行交互,处理checkpoint等事件,在做checkpoint时,提交instant到timeLine上,并生成下一个instant的时间,算法为取当前最新的commi时间,比对当前时间与commit时间,若当前时间大于commit时间,则返回,否则一直循环等待生成。
- 2、数据压缩
压缩( compaction)用于在 MergeOnRead存储类型时将基于行的log日志文件转化为parquet列式数据文件,用于加快记录的查找。
compaction首先会遍历各分区下最新的parquet数据文件和其对应的log日志文件进行合并,并生成新的FileSlice,在TimeLine 上提交新的Instant:
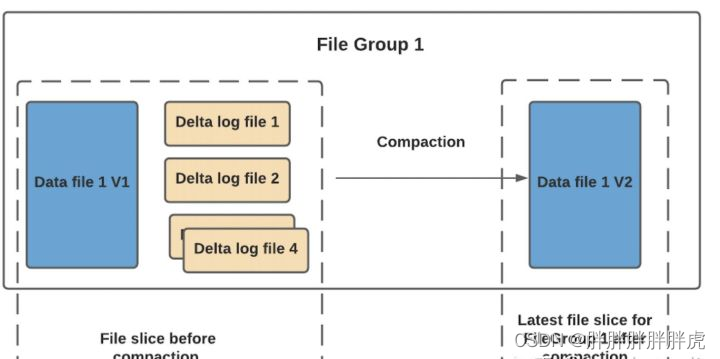
具体策略分为4种,具体见官网说明:
compaction.trigger.strategy:Strategy to trigger compaction, options
are 1.‘num_commits’: trigger compaction when reach N delta commits;
2.‘time_elapsed’: trigger compaction when time elapsed > N seconds since last compaction; 3.‘num_and_time’: trigger compaction when both
NUM_COMMITS and TIME_ELAPSED are satisfied; 4.‘num_or_time’: trigger
compaction when NUM_COMMITS or TIME_ELAPSED is satisfied. Default is
'num_commits’Default Value: num_commits (Optional)
在项目实践中需要注意参数’read.streaming.skip_compaction’ 参数的配置,其表示在流式读取该表是否跳过压缩后的数据,若该表用于后续聚合操作表的输入表,则需要配置值为true,表示聚合操作表不再消费读取压缩数据。若不配置或配置为false,则该表中的数据在未被压缩之前被聚合操作表读取了一次,在压缩后数据又被读取一次,会导致聚合表的sum、count等算子结果出现双倍情况。
- 3.数据清理
随着用户向表中写入更多数据,对于每次更新,Hudi会生成一个新版本的数据文件用于保存更新后的记录(COPY_ON_WRITE) 或将这些增量更新写入日志文件以避免重写更新版本的数据文件 (MERGE_ON_READ)。 在这种情况下,根据更新频率,文件版本数可能会无限增长,但如果不需要保留无限的历史记录,则必须有一个流程(服务)来回收旧版本的数据,这就是 Hudi 的清理服务。
具体清理策略可参考官网,一般使用的清理策略为:
KEEP_LATEST_FILE_VERSIONS:此策略具有保持 N 个文件版本而不受时间限制的效果。会删除N之外的FileSlice。
表读取原理
1)数据读取种类
Hudi支持如下三种查询类型:
-
Snapshot Queries 快照查询:可以查询最新COMMIT的快照数据。针对Merge On Read类型的表,查询时需要在线合并列存中的Base数据和日志中的实时数据;针对Copy On Write表,可以查询最新版本的Parquet数据。Copy On Write和Merge On Read表支持该类型的查询。 -
Incremental Queries 增量查询:支持增量查询的能力,可以查询给定COMMIT之后的最新数据。Copy On Write和Merge On Read表支持该类型的查询。 -
Read Optimized Queries 读优化查询:只能查询到给定COMMIT之前所限定范围的最新数据。Read Optimized Queries是对Merge On Read表类型快照查询的优化,仅限于 MergeOnRead 表,可以查询到列存文件的数据,其原理是通过牺牲查询数据的时效性,来减少在线合并日志数据产生的查询延迟。

2.读取过程分析
如下为Hudi数据流式读取Job图:
其过程为:
1.开启split_monitor算子,每隔N秒(可配置)监听TimeLine上变化,并将变更的Instant封装为FileSlice 采用Rebanlance下发给split_reader task;
2.split_reader task根据FileSlice信息进行数据读取;
---->>> Flink on hudi
https://www.jianshu.com/p/f509429c2f20
基于 Flink Hudi 的流批一体数据仓库
https://zhuanlan.zhihu.com/p/523028640
flinksql hudi 配置参数
https://hudi.apache.org/cn/docs/configurations/#FLINK_SQL
hudi 同步 hive
https://blog.csdn.net/hjl18309163914/article/details/107844269
hudi 表有两种模式,如果Hudi表是COPY_ON_WRITE类型,那么映射成的Hive表对应是指定的Hive表名,此表中存储着Hudi所有数据。
如果Hudi表类型是MERGE_ON_READ模式,那么映射的Hive表将会有2张,一张后缀为_rt ,另一张表后缀为_ro。后缀 _rt 对应的Hive表中存储的是Base文件Parquet格式数据+log Avro格式数据,也就是全量数据。后缀为 _ro Hive表中存储的是存储的是Base文件对应的数据。
建表语句 demo
CREATE TABLE sink_order_mysql_goods_order(
`goods_order_id` bigint COMMENT '自增主键id'
, `goods_order_uid` string COMMENT '订单uid'
, `customer_uid` string COMMENT '客户uid'
, `customer_name` string COMMENT '客户name'
, `student_uid` string COMMENT '学生uid'
, `order_status` bigint COMMENT '订单状态 1:待付款 2:部分付款 3:付款审核 4:已付款 5:已取消'
, `is_end` bigint COMMENT '订单是否完结 1.未完结 2.已完结'
, `discount_deduction` bigint COMMENT '优惠总金额(单位:分)'
, `contract_deduction` bigint COMMENT '老合同抵扣金额(单位:分)'
, `wallet_deduction` bigint COMMENT '钱包抵扣金额(单位:分)'
, `original_price` bigint COMMENT '订单原价(单位:分)'
, `real_price` bigint COMMENT '实付金额(单位:分)'
, `pay_success_time` timestamp(3) COMMENT '完全支付时间'
, `tags` string COMMENT '订单标签(1新签 2续费 3扩科 4报名-合新 5转班-合新 6续费-合新 7试听-合新)'
, `status` bigint COMMENT '是否有效(1.生效 2.失效 3.超时未付款)'
, `remark` string COMMENT '订单备注'
, `delete_flag` bigint COMMENT '是否删除(1.否,2.是)'
, `test_flag` bigint COMMENT '是否测试数据(1.否,2.是)'
, `create_time` timestamp(3) COMMENT '创建时间'
, `update_time` timestamp(3) COMMENT '更新时间'
, `create_by` string COMMENT '创建人uid(唯一标识)'
, `update_by` string COMMENT '更新人uid(唯一标识)'
, `belong_school` bigint COMMENT '归属校区'
, `share_sale_no` string COMMENT '共享销售工号'
,PRIMARY KEY (goods_order_id) NOT ENFORCED
) COMMENT '订单表'
WITH (
'connector' = 'hudi'
, 'path' = 'hdfs://hdfs-namenode-service:9000/hudi-warehouse/goods_order' ---路径会自动创建
, 'hoodie.datasource.write.recordkey.field' = 'goods_order_id' -- 主键
, 'write.precombine.field' = 'update_time' -- 相同的键值时,取此字段最大值,默认ts字段
, 'read.streaming.skip_compaction' = 'true' -- 避免重复消费问题
, 'write.bucket_assign.tasks' = '2' --并发写的 bucekt 数
, 'write.tasks' = '2'
, 'compaction.tasks' = '1'
, 'write.operation' = 'upsert' --UPSERT(插入更新)\INSERT(插入)\BULK_INSERT(批插入)(upsert性能会低些,不适合埋点上报)
, 'write.rate.limit' = '20000' -- 限制每秒多少条
, 'table.type' = 'COPY_ON_WRITE'
, 'compaction.async.enabled' = 'true' -- 在线压缩
, 'compaction.trigger.strategy' = 'num_or_time' -- 按次数压缩
, 'compaction.delta_commits' = '20' -- 默认为5
, 'compaction.delta_seconds' = '60' -- 默认为1小时
, 'hive_sync.enable' = 'true' -- 启用hive同步
, 'hive_sync.mode' = 'hms' -- 启用hive hms同步,默认jdbc
, 'hive_sync.metastore.uris' = 'thrift://hive-metastore-svc:9083' -- required, metastore的端口
, 'hive_sync.jdbc_url' = 'jdbc:hive2://hive-service-svc:10000' -- required, hiveServer地址
, 'hive_sync.table' = 'order_mysql_goods_order' -- required, hive 新建的表名 会自动同步hudi的表结构和数据到hive
, 'hive_sync.db' = 'cdc_ods' -- required, hive 新建的数据库名
, 'hive_sync.username' = 'root' -- required, HMS 用户名
, 'hive_sync.password' = '123456' -- required, HMS 密码
, 'hive_sync.skip_ro_suffix' = 'true' -- 去除ro后缀
);
Flink写数据到 hudi中,hive读取
hudi hive配置参数:https://hudi.apache.org/docs/syncing_metastore
https://blog.csdn.net/weixin_44131414/article/details/122983339
流式查询hudi表
- 主键
CREATE TABLE order_hudi(
`orderId` STRING PRIMARY KEY NOT ENFORCED,
`userId` STRING,
`orderTime` STRING,
`ip` STRING,
`orderMoney` DOUBLE,
`orderStatus` INT,
`ts` STRING,
`partition_day` STRING
)
PARTITIONED BY (partition_day)
WITH(
'connector' = 'hudi',
'path'='hdfs://hdfs-namenode-service:9000/hudi-warehouse/flink_hudi_order',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '4'
)
### https://blog.csdn.net/czmacd/article/details/126059726
CREATE TABLE tb_person_hudi (
id BIGINT,
age INT,
name STRING,
create_time TIMESTAMP ( 3 ),
time_stamp TIMESTAMP(3),
PRIMARY KEY ( id ) NOT ENFORCED
) WITH (
'connector' = 'hudi',
'table.type' = 'MERGE_ON_READ',
'path' = 'file:///D:/data/hadoop3.2.1/warehouse/tb_person_hudi',
'read.start-commit' = '20220722103000',
'read.task' = '1',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '30'
)
- 分区
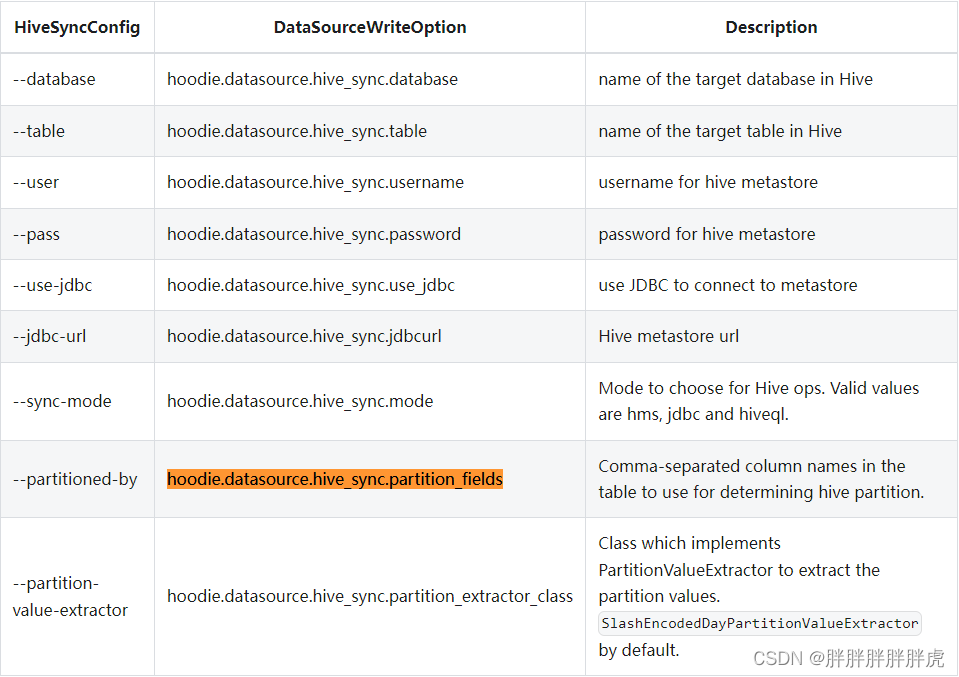
hoodie.datasource.hive_sync.partition_fields
if (conf.getBoolean(FlinkOptions.READ_AS_STREAMING)) {
StreamReadMonitoringFunction monitoringFunction = new StreamReadMonitoringFunction(
conf, FilePathUtils.toFlinkPath(path), maxCompactionMemoryInBytes, getRequiredPartitionPaths());
InputFormat<RowData, ?> inputFormat = getInputFormat(true);
OneInputStreamOperatorFactory<MergeOnReadInputSplit, RowData> factory = StreamReadOperator.factory((MergeOnReadInputFormat) inputFormat);
SingleOutputStreamOperator<RowData> source = execEnv.addSource(monitoringFunction, getSourceOperatorName("split_monitor"))
.setParallelism(1)
.transform("split_reader", typeInfo, factory)
.setParallelism(conf.getInteger(FlinkOptions.READ_TASKS));
return new DataStreamSource<>(source);
}
/**
* FlinkOptions.READ_AS_STREAMING
* org.apache.hudi.configuration.FlinkOptions#READ_AS_STREAMING
*/
public static final ConfigOption<Boolean> READ_AS_STREAMING = ConfigOptions
.key("read.streaming.enabled")
.booleanType()
.defaultValue(false)// default read as batch
.withDescription("Whether to read as streaming source, default false");
hudi hive同步模式
https://hudi.apache.org/docs/syncing_metastore#sync-modes
Flink SQL Kafka写入Hudi详解 hudi cow mor
https://www.233tw.com/database/117599
—>> 雨雀 hudi flink 答疑解惑
https://www.yuque.com/docs/share/01c98494-a980-414c-9c45-152023bf3c17?#IsoNU
问题记录
hive 同步 hudi 任务报错
CREATE TABLE flink_cdc_sink_hudi_hive(
uuid varchar(20),
name varchar(10),
age int,
ts timestamp(3),
dt varchar(20)
)
PARTITIONED BY (dt)
with(
'connector'='hudi',
'path'= 'hdfs://hdfs-namenode-service:9000/flink_cdc_sink_hudi_hive',
'table.type'= 'MERGE_ON_READ',
'hoodie.datasource.write.recordkey.field'= 'uuid',
'write.precombine.field'= 'ts',
'write.tasks'= '1',
'write.rate.limit'= '2000',
'compaction.tasks'= '1',
'compaction.async.enabled'= 'true',
'compaction.trigger.strategy'= 'num_commits',
'compaction.delta_commits'= '1',
'changelog.enabled'= 'true',
'read.streaming.enabled'= 'true',
'read.streaming.check-interval'= '3',
'hive_sync.enable'= 'true',
'hive_sync.mode'= 'hms',
'hive_sync.metastore.uris'= 'thrift://hive-metastore-svc:9083',
'hive_sync.jdbc_url'= 'jdbc:hive2://hive-service-svc:10000',
'hive_sync.table'= 'flink_cdc_sink_hudi_hive',
'hive_sync.db'= 'default',
'hive_sync.username'= 'root',
'hive_sync.password'= '123456',
'hive_sync.support_timestamp'= 'true'
);
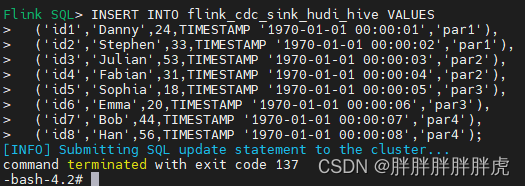
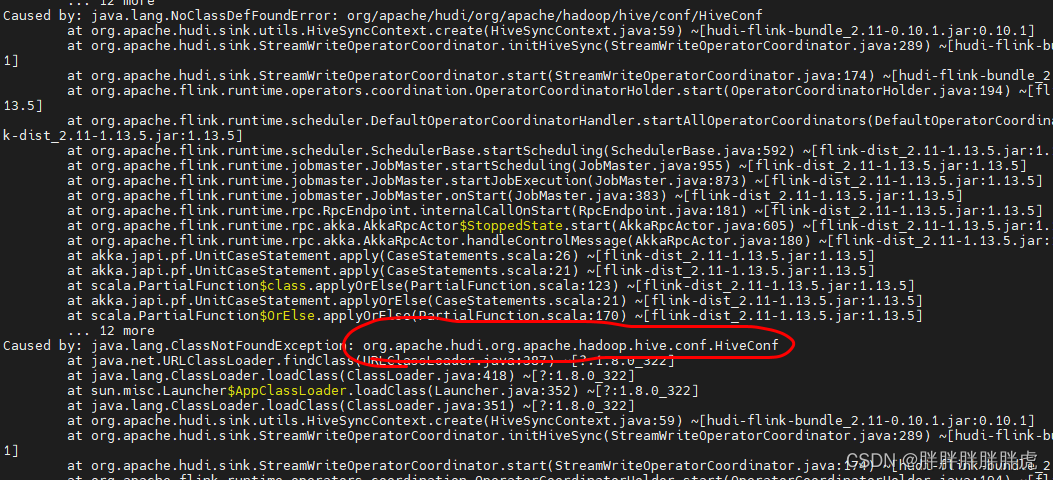
报错如下:java.lang.ClassNotFoundException: org.apache.hudi.org.apache.hadoop.hive.conf.HiveConf
docker logs
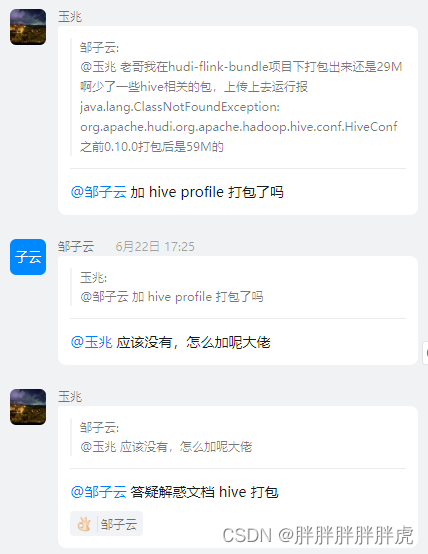
https://www.yuque.com/docs/share/01c98494-a980-414c-9c45-152023bf3c17?#IsoNU
https://www.yuque.com/yuzhao-my9fz/kb/vs4odt
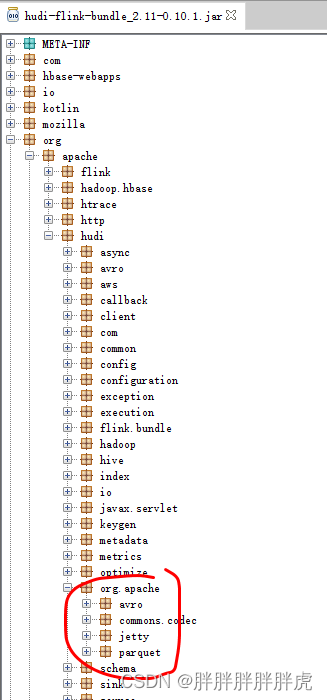
mvn package -DskipTests -Drat.skip=true -Pflink-bundle-shade-hive2
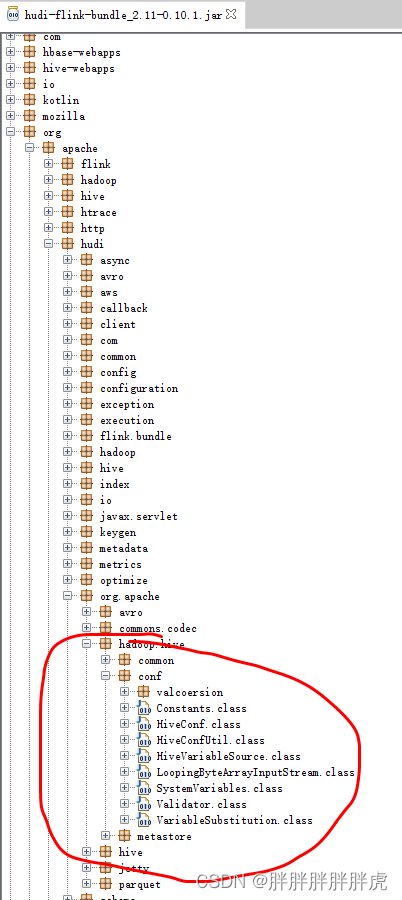
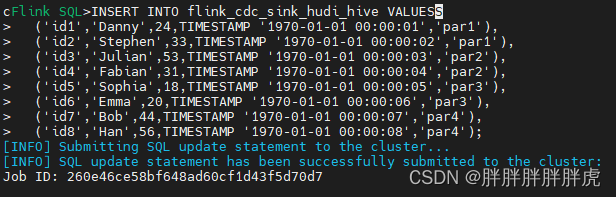
接上面 hive 并未同步的到报错如下:

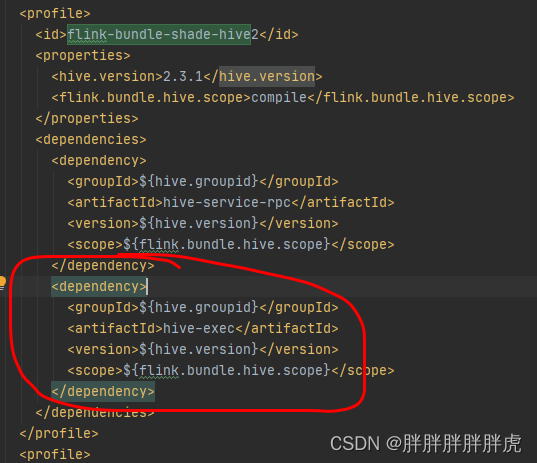

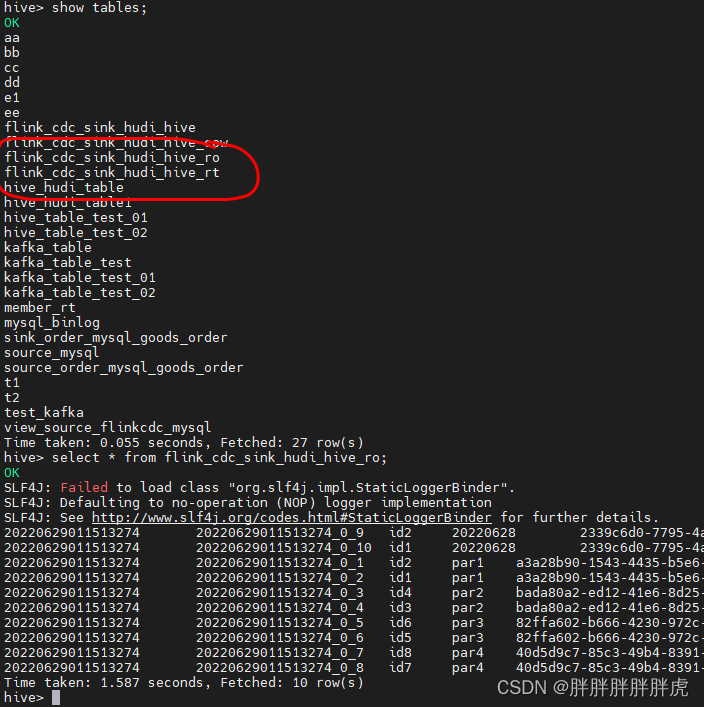
注意:
- xxx_ro 中存储的只是Base文件中数据(parquet列式存储结果)
- xxx_rt 中存储的是Base文件(Parquet列式存储结果)+log(Avro行式存储结果)
博客记录
1、Hudi查询&写入&常见问题汇总
https://blog.51cto.com/u_9928699/5307085
2、hudi的索引机制以及使用场景
https://blog.csdn.net/weixin_39636364/article/details/120600202
系列博客
—>>> https://blog.csdn.net/yang_shibiao/category_11973566.html















 1630
1630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









