







在Doris表中,字段被人为的分为2种:Key和Value. Key也就是俗称的维度,Value是指标。 建表时 Key 列必须在 Value 列前面。
AGGREGATE KEY
表中的列按照是否设置了AggregationType,分为Key(维度列)和Value(指标列)。没有设置AggregationType的称为Key,设置了AggregationType 的称为Value
当我们导入数据时,对于key列相同的行会聚合成一行,而Value列会按照设置的AggregationType进行聚合。AggregationType目前有一下四种聚合方式:
-
SUM:求和,多行的Value进行累加
-
REPLACE:替代,下一批数据中Value 会替代之前导入过行中的Value
-
REPLCACE_IF_NOT_NULL:当遇到Null值则不更新
-
Max:保留最大值
-
Min:保留最小值
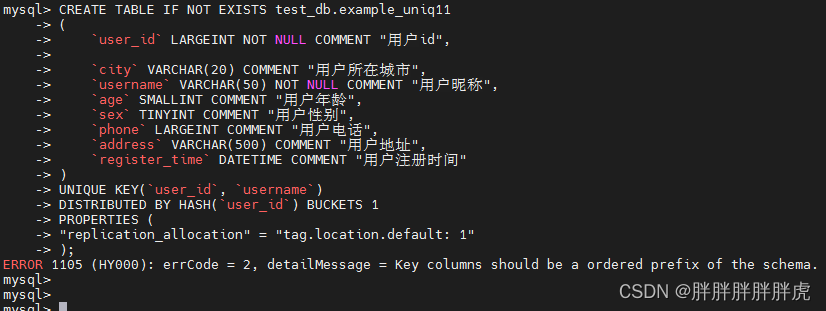
CREATE TABLE IF NOT EXISTS test_db.example_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1" -- 设置副本数
);
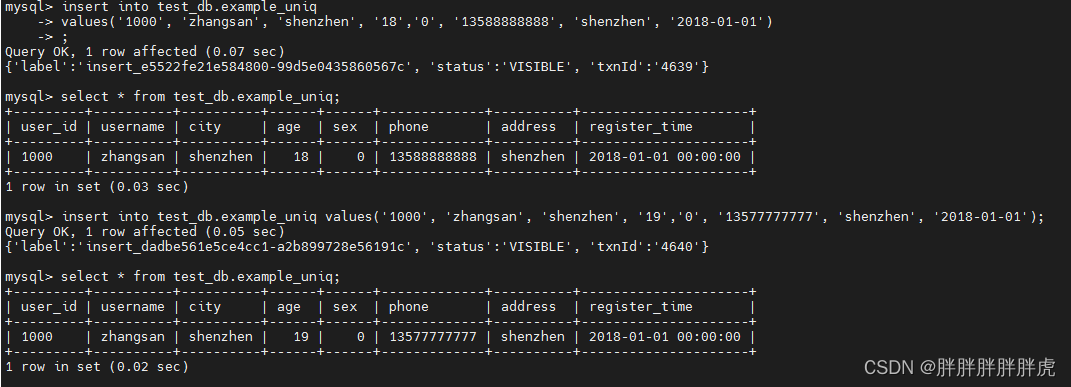
UNIQUE KEY
在某些多维分析场景下,用户更关注的是如何保证 key 的唯一性(如何保证Primary key 唯一约束),uniq 模型完全可以用聚合模型中的 replace 方式替代;
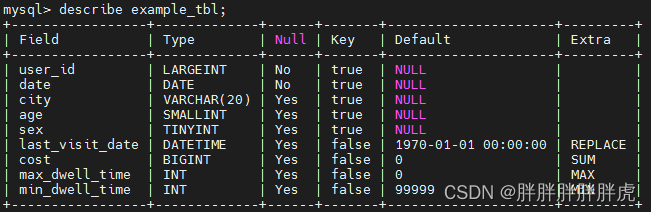
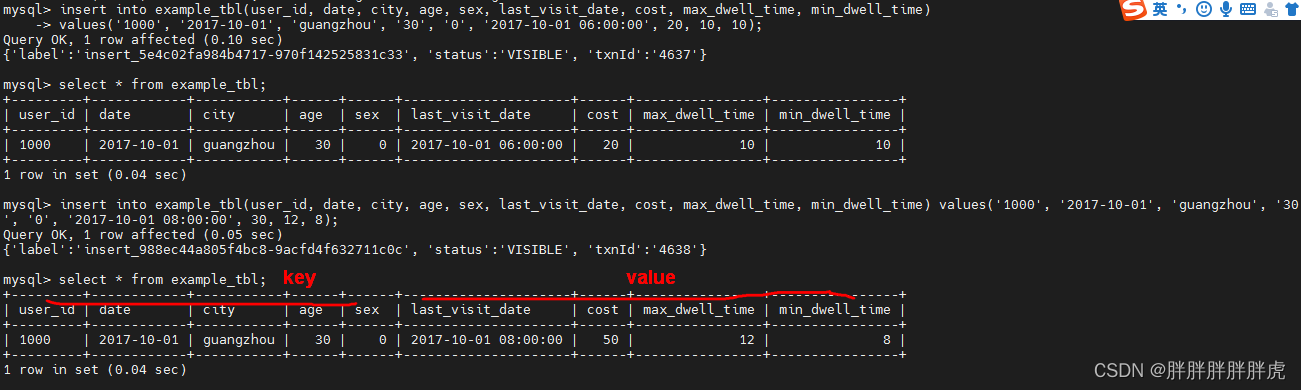
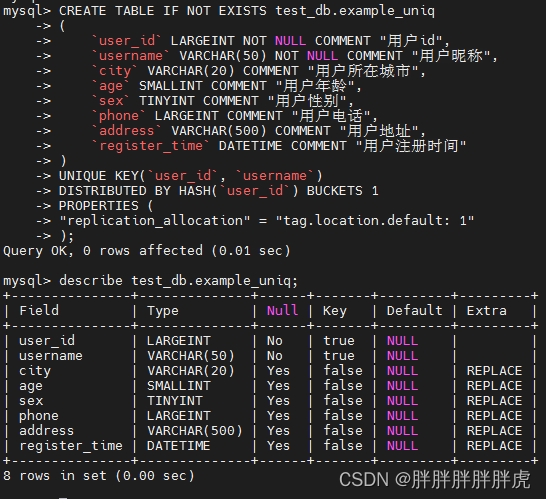
CREATE TABLE IF NOT EXISTS test_db.example_uniq
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
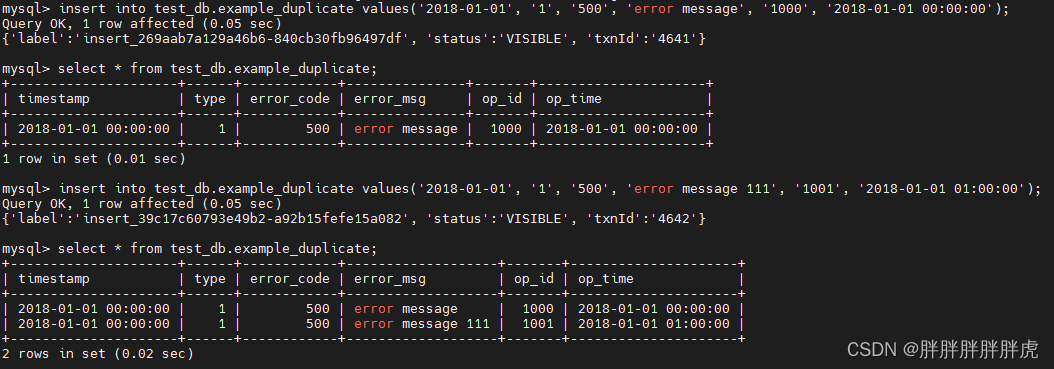
DUPLICATE KEY
在某些多维分析场景下,数据既没有主键,也没有聚合需求。duplicate 模型满足这类需求,数据完全安装导入文件中的数据进行存储,不会有任何聚合。即使两条数据完全相同,也都会保留。
CREATE TABLE IF NOT EXISTS test_db.example_duplicate
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`, `error_code`)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);

转自:https://doris.apache.org/zh-CN/docs/data-table/data-model#duplicate-%E6%A8%A1%E5%9E%8B














 1801
1801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









