







1. kafka简介
Kafka是一个分布式的消息队列系统(Message Queue)。官网:https://kafka.apache.org/

kafka集群有多个Broker服务器组成,每个类型的消息被定义为topic。同一topic内部的消息按照一定的key和算法被分区(partition)存储在不同的Broker上。消息生产者producer和消费者consumer可以在多个Broker上生产/消费topic。
1.1 概念理解:
Topics and Logs:
Topic即为每条发布到Kafka集群的消息都有一个类别,topic在Kafka中可以由多个消费者订阅、消费。每个topic包含一个或多个partition(分区),partition数量可以在创建topic时指定,每个分区日志中记录了该分区的数据以及索引信息。如下图:

**Kafka只保证一个分区内的消息有序,不能保证一个主题的不同分区之间的消息有序。**如果你想要保证所有的消息都绝对有序可以只为一个主题分配一个分区。
分区会给每个消息记录分配一个顺序ID号(偏移量), 能够唯一地标识该分区中的每个记录。Kafka集群保留所有发布的记录,不管这个记录有没有被消费过,Kafka提供相应策略通过配置从而对旧数据处理。

实际上,每个消费者唯一保存的元数据信息就是消费者当前消费日志的位移位置。位移位置是由消费者控制,即、消费者可以通过修改偏移量读取任何位置的数据。
Distribution – 分布式
Producers – 生产者:指定topic来发送消息到Kafka Broker
Consumers – 消费者:根据topic消费相应的消息
1.2 kafka集群部署
修改配置文件:kafka目下下的config/server.properties
1.修改编号,加上对应zookeeper对应节点地址和端口

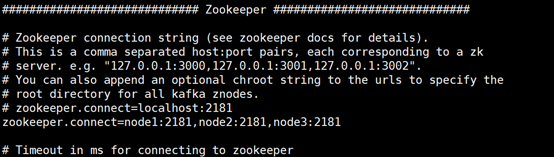
核心配置参数说明:
broker.id: broker集群中唯一标识id,0、1、2、3依次增长(broker即Kafka集群中的一台服务器)
当前Kafka集群共三台节点,分别为:node1、node2、node3。对应的broker.id分别为0、1、2。zookeeper.connect: zk集群地址列表(用来联系其它节点)。
2.分发到其他节点上,并修改对应的broker编号
将当前node1服务器上的Kafka目录同步到其他node2、node3服务器上:
scp -r /opt/kafka/ node2:/opt
scp -r /opt/kafka/ node3:/opt
修改node2、node3上Kafka配置文件中的broker.id(分别在node2、3服务器上执行以下命令修改broker.id)
sed -i -e ‘s/broker.id=./broker.id=1/’ /opt/kafka/config/server.properties
sed -i -e 's/broker.id=./broker.id=2/’ /opt/kafka/config/server.properties
或者去配置文件通过vim修改。
1.3 启动Kafka集群
A、启动Zookeeper集群。
B、启动Kafka集群。
分别在三台服务器上执行以下命令启动:
bin/kafka-server-start.sh config/server.properties
如果没配环境变量,要去对应的目录下执行。
启动后是:

测试:
kafka-topics.sh --help查看帮助手册)
创建topic(test):
bin/kafka-topics.sh --zookeeper hadoop01:2181, hadoop02:2181, hadoop03:2181 --create --replication-factor 2 --partitions 3 --topic test
参数说明:
–replication-factor:指定每个分区的复制因子个数,默认1个
–partitions:指定当前创建的kafka分区数量,默认为1个
–topic:指定新建topic的名称)
查看topic列表:
bin/kafka-topics.sh --zookeeper hadoop01:2181, hadoop02:2181, hadoop03:2181 --list
查看“test”topic描述:
bin/kafka-topics.sh --zookeeper hadoop01:2181, hadoop02:2181, hadoop03:2181 --describe --topic test
创建生产者:
bin/kafka-console-producer.sh --broker-list hadoop01:9092, hadoop02:9092, hadoop03:9092 --topic test
创建后就在等待输入,键盘输入什么就生产什么数据。
创建消费者:
bin/kafka-console-consumer.sh --zookeeper hadoop01:2181, hadoop02:2181, hadoop03:2181 --from-beginning --topic test
beginning表示从头开始消费;输出结果在分区内是有序的,不同分区是无法保证的,所以三个一组是一个分区有序,整体无序。但是,如果生产者和消费者都启动后,只要生产者产生一个,则消费者一定会消费一个,一定是顺序输出的。
注:kafka是一个消息存储和消费的容器,而storm是一个实时处理机制,如果两个融合,则storm的spout即为kafka的消费者即可。
查看帮助手册:
bin/kafka-console-consumer.sh help
2. Flume安装
1 ftp 上传linux: apache-flume-1.6.0-bin.tar.gz
2 解压到 /opt/sxt目录下
3 进入conf/ 目录,直接把flume-env.sh.template 文件改为flume-env.sh
4 修改flume-env.sh 文件中的export_java ,变为 export JAVA_HOME=/home/hadoop/app/jdk1.8.0_112
#可以使用pwd快速定位jdk的位置
5 配置flume环境变量在profile中
6. 在./conf/ 目录下创建(新建): fk.conf
##在fk.conf 中将下列复制粘贴过去。
#输入源 输出 管道
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source ## 连接协议 flume运行节点 运行端口号
a1.sources.r1.type = avro
a1.sources.r1.bind = node06
a1.sources.r1.port = 41414
# Describe the sink ##记得改主机和端口号
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = testflume
a1.sinks.k1.brokerList = node06:9092,node07:9092,node08:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 10000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
7.启动: 先启动zookeeper(zkServer.sh start),再启动flume:
bin/flume-ng agent -n a1 -c conf -f conf/fk.conf -Dflume.root.logger=DEBUG,console
##以代理模式启动,读取配置文件为fk.conf ,错误信息使用debug模式,在控制台输出。















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









