







本文主要是在Windows平台下配置caffe后,记录自己训练第一个模型的全部过程。
首先,我们要做的工作是:
1、自己收集好训练集和测试集样本图并定义好类标
2、将上面得到的两类图像“归一化”,转化成能被caffe操作的数据
3、操作得到新数据的均值(即得到mean.binaryproto文件)
4、利用均值来进行训练和测试(即编写 'train_val.prototxt' 文件)
5、为训练文件设置参数(即编写 'solver.prototxt' 文件)
6、运行train.sh文件,使整个模型运作并得出accuracy结果
以上6个步骤过程很多博客都有详细记录,我的参阅,但是自己操作过程中遇到很多问题,问题和解决方法记录如下:
一、关于上面第一步文件重命名问题
在给下载好的图片批量重命名时,rename.bat文件最后几行的编写:

因为只要文件名中含有空格,文件就无法正常运行。
二、第二步图片样本的归一化
将 examples->imagenet 中的create_imagenet.sh复制到自己Demo目录下后,重新编写。
尽量都用绝对路径,以后直接复制过去后便更容易修改。(例:DATA=E:/Program_Files/Caffe......)
定义的两个常量TRAIN_DATA_ROOT和VAL_DATA_ROOT的路径最后一级目录train或val文件中必须只包含要训练或测试所用的样本图片,不能有其他任何形式的文件存在,不然会报错。
三、求样本图像的均值
将 examples->imagenet 中的make_imagenet_mean.sh复制到自己Demo目录下后,重新编写。

这里要加上 ' -backend=lmdb' 标示图像存储方式是lmdb。
还有一点要说明:两个相同的路径名不能用不同的常量来表示,我后期忽略了这点,导致调了很久。
(这么愚蠢的说明竟然还要提。。 因为没人能体会学渣入门之难堪比上青天的痛苦TT)
三、利用均值文件进行训练和测试
将 examples->imagenet 中相应的solver.prototxt和train_val.prototxt和train_imagenet.sh复制过来,相应路径都改一下。
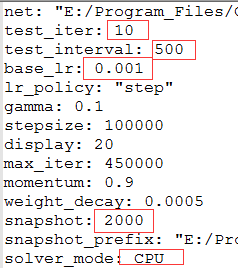
最后修改一下solver.prototxt文件的参数,测试图片10张,所以test-iter设置小一点,后面大约自己看着办。
最后的结果还在跑,听说这个过程很慢。
原来真的很慢。















 1022
1022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









