






本次抓取的网站是http://www.umeituku.com/katongdongman/dongmantupian/这个菜单下的图片
网站结构进行介绍下:
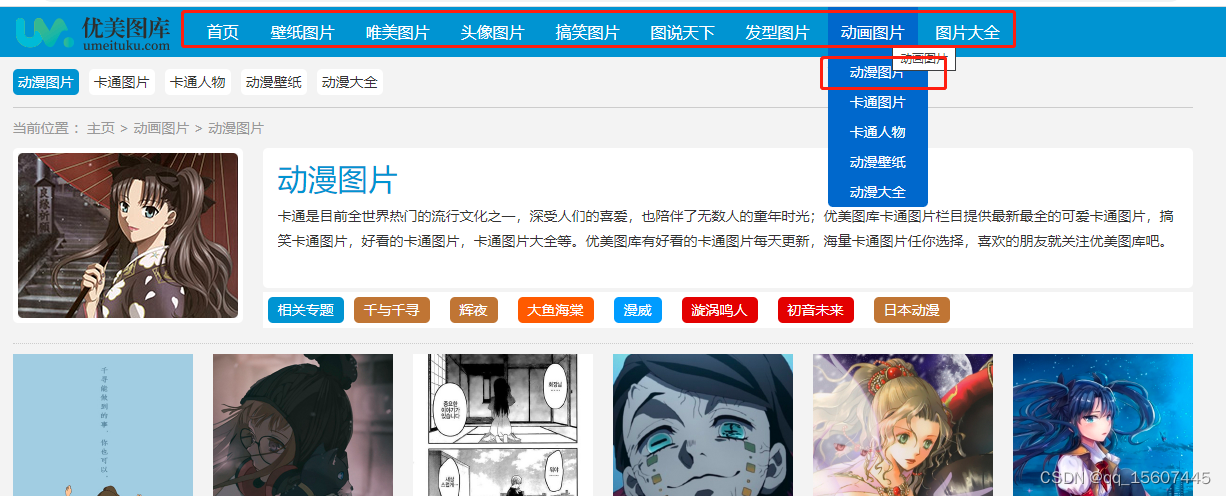
首级加二级菜单,展示的是image的列表,分页显示
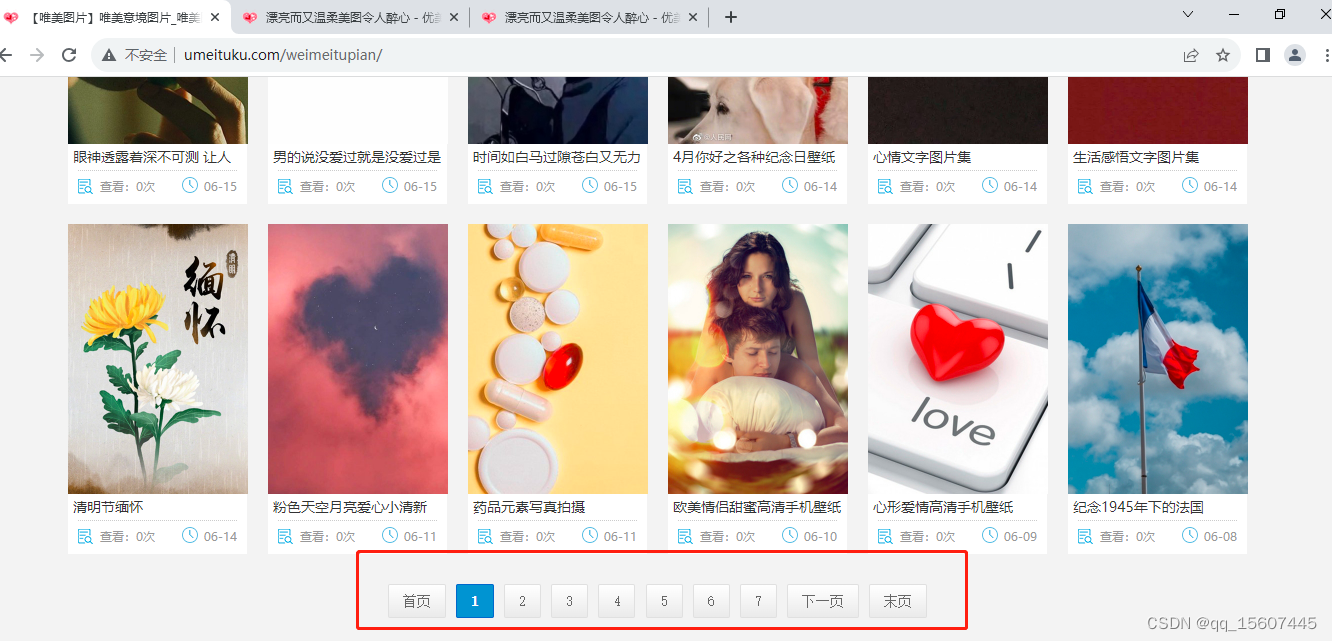
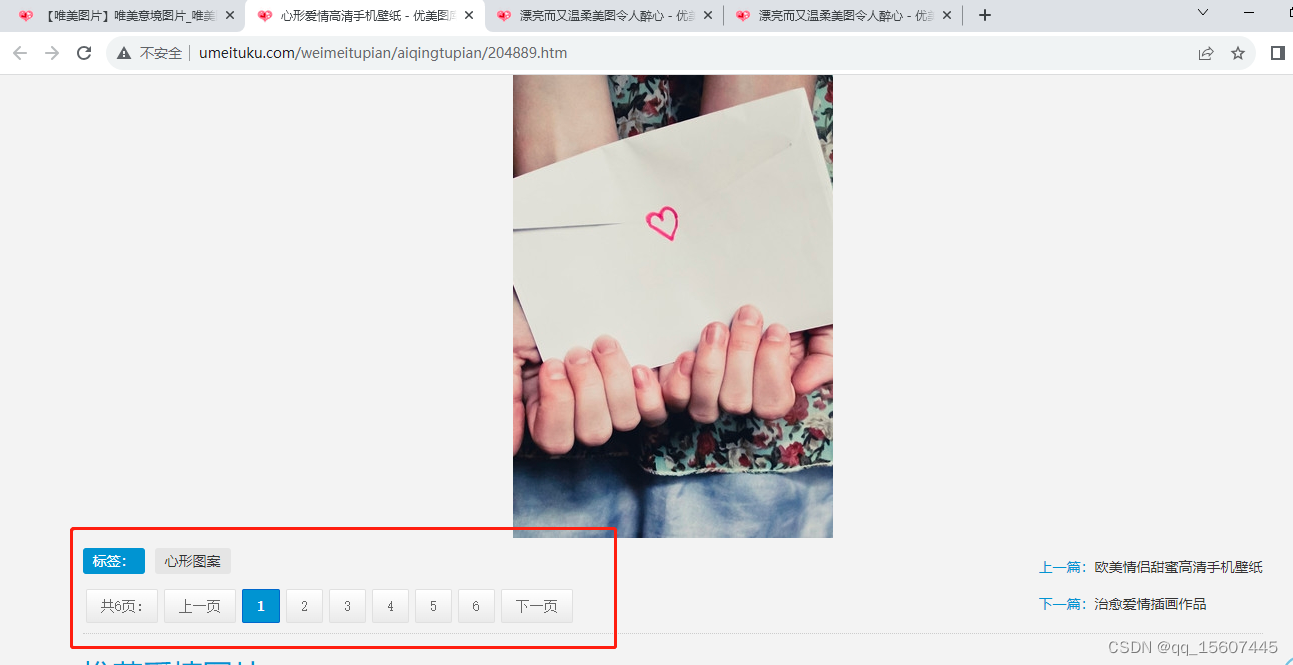
点击图片可查看大图,且每页一张大图
页面源码介绍:
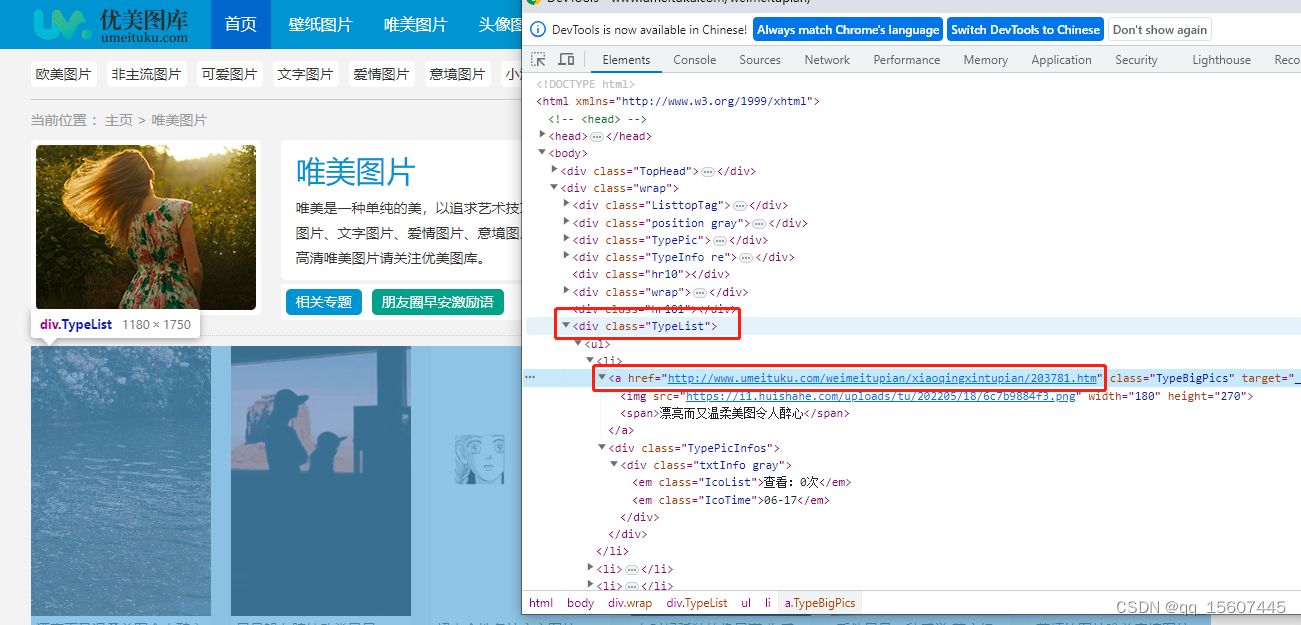
可以看出TypeList下面列出的是图片页的数据。a标签的href的值是大图显示页面的地址
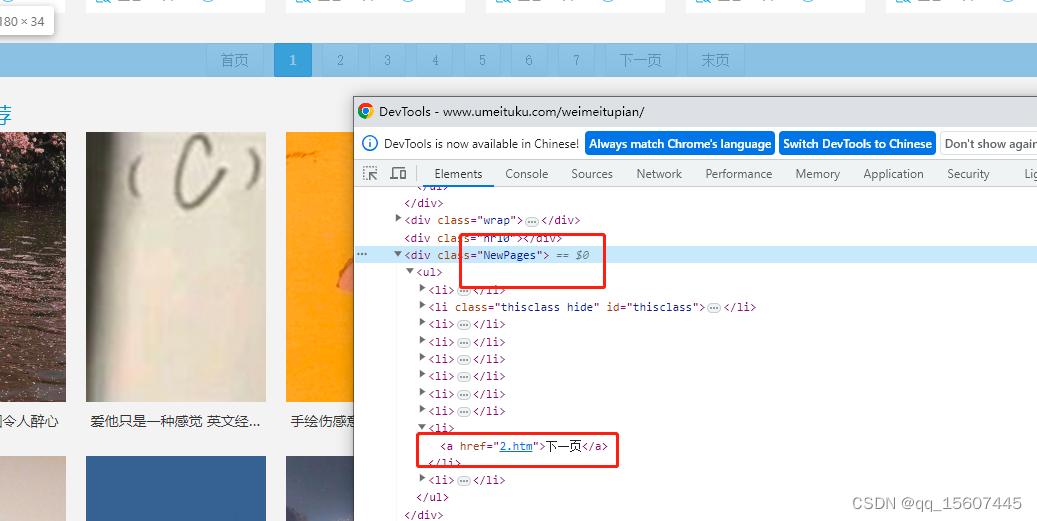
页码这个地方可以看出NewPages这个标签下有下一页的链接 ,可以使用下一页标签进行自动抓取下一页。
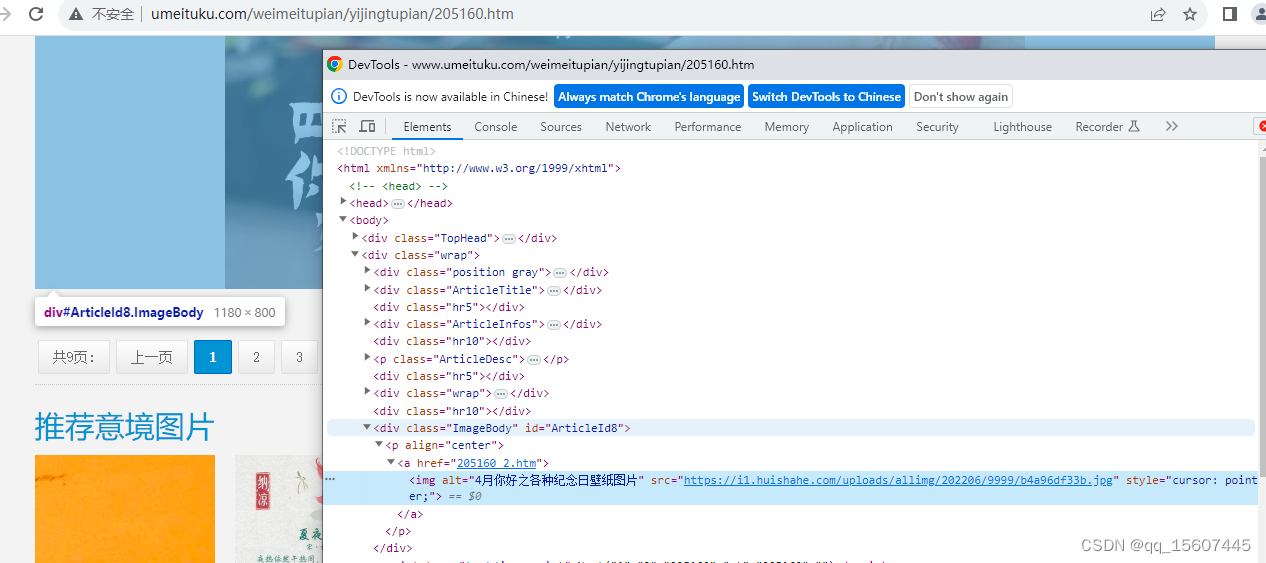
大图页面可以看出ImageBody这个div下有图片的地址,可以根据这个地址进行数据下载。
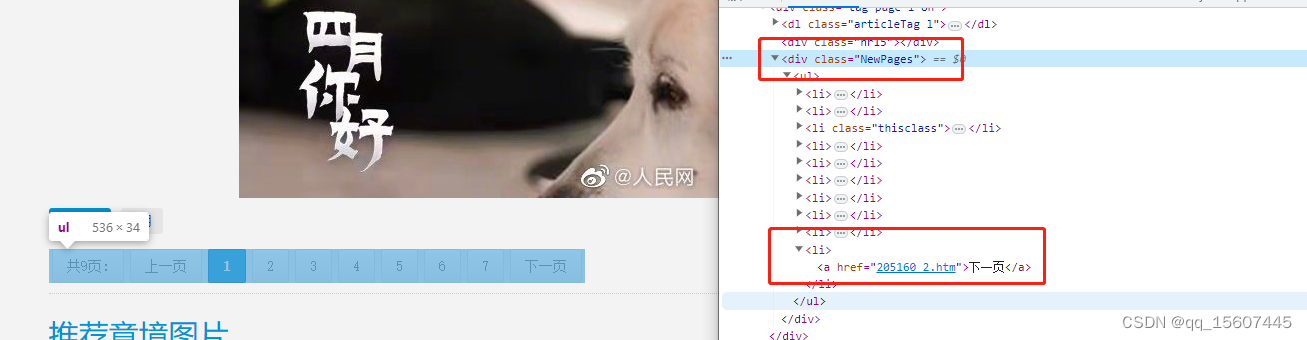
NewPages这个页签下有下一页的链接,可以根据这个进行自动抓取下一页。
import requests
from bs4 import BeautifulSoup
import asyncio
import os
from multiprocessing import Pool
# 保存图片文件
def downpic(picpath,pic_url):
f = open(picpath,mode="wb")
f.write(requests.get(pic_url).content)
f.close()
#大图页面获取大图,根据页签进行下一个的嵌套循环
def getpic(url,flor_name):
print(url)
respa=requests.get(url)
respa.encoding="utf-8"
pics_page=BeautifulSoup(respa.text,"html.parser")
#保存图片
pic_url = pics_page.find("div",attrs={"class":"ImageBody"}).find("img").get("src")
# 文件夹名称
path = os.path.join("D:\pics",flor_name)
if not os.path.exists(path):
os.mkdir(path)
picname=pic_url.split('/')[-1]
picpath = os.path.join(path,picname)
# 保存图片文件
downpic(picpath,pic_url)
try:
li_page = pics_page.find("div" ,attrs={"class":"NewPages"}).find('li', text="下一页")
next_page_url="http://www.umeituku.com/katongdongman/dongmantupian/"+li_page.find('a')['href']
getpic(next_page_url,flor_name)
except:
print("this page is over!")
#列表页,获取大图页的地址,根据页签进行嵌套循环
def getlistPic(basicurl):
resp=requests.get(basicurl)
resp.encoding='utf-8'
main_page =BeautifulSoup(resp.text,"html.parser")
alsts = main_page.find("div",attrs={"class":"TypeList"}).find_all("a",attrs={"class":"TypeBigPics"})
for alst in alsts:
href=alst.get("href")
flor_name =alst.find('span').text
try:
getpic(href,flor_name)
except:
print('this page is wrong!!!')
# 判断是否存在下一页
try:
nextpage = main_page.find("div" ,attrs={"class":"NewPages"}).find('li', text="下一页")
next_page_url="http://www.umeituku.com/katongdongman/dongmantupian/"+nextpage.find('a')['href']
getlistPic(next_page_url)
except:
print('this chapt is over!')直接调用该方法运行,效率低下
baseurl = "http://www.umeituku.com/katongdongman/dongmantupian/5.htm"
getlistPic(baseurl)使用进程池效率较高
if __name__ == '__main__':
baseurl = "http://www.umeituku.com/katongdongman/dongmantupian/5.htm"
# 创建进程池
pool = Pool()
pool.apply_async(getlistPic, args=(baseurl,))
pool.close()
pool.join()进程池没有限制进程的限制值,会产生很多的进程,导致进程阻塞,建议修改
if __name__ == '__main__':
baseurl = "http://www.umeituku.com/katongdongman/dongmantupian/5.htm"
# 创建进程池
pool = Pool(processes=20)
pool.apply_async(getlistPic, args=(baseurl,))
pool.close()
pool.join()
或者使用asyncio进行协程,代码如下
import requests
from bs4 import BeautifulSoup
import os
import asyncio
# 保存图片文件
async def downpic(picpath,pic_url):
f = open(picpath, mode="wb")
f.write(requests.get(pic_url).content)
f.close()
#大图页面获取大图,根据页签进行下一个的嵌套循环
async def getpic(url, flor_name):
print(url)
respa = requests.get(url)
respa.encoding = "utf-8"
pics_page = BeautifulSoup(respa.text, "html.parser")
# 保存图片
pic_url = pics_page.find("div", attrs={"class": "ImageBody"}).find("img").get("src")
# 文件夹名称
path = os.path.join("D:\pics", flor_name)
if not os.path.exists(path):
os.mkdir(path)
picname = pic_url.split('/')[-1]
picpath = os.path.join(path, picname)
# 保存图片文件
await downpic(picpath, pic_url)
try:
li_page = pics_page.find("div", attrs={"class": "NewPages"}).find('li', text="下一页")
next_page_url = "http://www.umeituku.com/weimeitupian/oumeitupian/" + li_page.find('a')['href']
# 使用递归调用getpic()函数
await getpic(next_page_url, flor_name)
except:
print("this page is over!")
#列表页,获取大图页的地址,根据页签进行嵌套循环
async def getlistPic(basicurl):
resp = requests.get(basicurl)
resp.encoding = 'utf-8'
main_page = BeautifulSoup(resp.text, "html.parser")
alsts = main_page.find("div", attrs={"class": "TypeList"}).find_all("a", attrs={"class": "TypeBigPics"})
for alst in alsts:
href = alst.get("href")
flor_name = alst.find('span').text
await getpic(href, flor_name)
# 判断是否存在下一页
try:
nextpage = main_page.find("div", attrs={"class": "NewPages"}).find('li', text="下一页")
next_page_url = "http://www.umeituku.com/weimeitupian/oumeitupian/" + nextpage.find('a')['href']
# 使用递归调用getlistPic()函数
await getlistPic(next_page_url)
except:
print('this chapt is over!')
async def main():
baseurl = "http://www.umeituku.com/weimeitupian/oumeitupian/"
await getlistPic(baseurl)
# 运行协程
asyncio.run(main())













 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









