







传送门:基于神经网络的手写数字识别(上)
上一篇文章讲述了BP神经网络的基本思想以及反向传导,梯度下降法等概念。
在本篇文章中,将给出用c++实现BPnet,以及将应用到手写数字识别中去。
一:神经节点的抽象、数据的组织形式
struct neuron
{
vector<double>weight; //对下一层的权重
vector<double>update_w; //权重更新值
vector<double>ave_update_w; //平均权重更新值
double output; //输出
double threshold; //阈值
neuron()
:output(0),
update_w(0),
ave_update_w(0)
{}
};这里有两个权重更新值,在使用BPnet完成不同训练时将使用不同的更新值,具体用法在下文中解释。
数据的组织形式是这样的:

可以看出,b1.output=a1.weight[0]*a1.output+a2.weight[0]*a2.output+a3.weight[0]*a3.output+b1.threshold;
然后将这个结果放入压缩函数
将神经节点放入一个数组,看作一个神经层。
再用一个数组存储所有层。
struct neuron
{
vector<double>weight;
vector<double>update_w;
vector<double>ave_update_w;
double output;
double threshold;
neuron()
:output(0),
update_w(0),
ave_update_w(0)
{}
};
typedef vector<neuron>layer;
struct read_type
{
vector<double> weight;
double threshold;
};
typedef vector<read_type> read_ly;
class bpNet
{
int train_num;//训练次数
static double eta;//步长
vector<layer>network;//所有神经层
}二:初始化、数据输入
初始化过程的主要工作有两个:创建神经网络,初始化权重与阈值。
void bpNet::set(const vector<int> & network_)
{
int layer_num = network_.size();
for (int i = 0; i < layer_num; i++)
{
network.push_back(layer());
for (int j = 0; j < network_[i]; j++)
{
network.back().push_back(neuron());
if (i > 0)
{
network[i][j].threshold = 0.5;
}
if (i < layer_num - 1)
{
for (int k = 0; k < network_[i + 1]; k++)
{
network[i][j].weight.push_back(rand()*(rand() % 2 ? 1 : -1)*1.0 / RAND_MAX);
network[i][j].update_w.push_back(0);
network[i][j].ave_update_w.push_back(0);
}
}
}
}
}数据输入即由输入数据进行一次计算。
void bpNet::putdata(vector<double> &in, const vector<int> & size)
{
for (int t = 0; t < size[0]; t++)
{
network[0][t].output = in[t];
}
for (int i = 1; i < size.size(); i++)
{
for (int j = 0; j < size[i]; j++)
{
network[i][j].output = 0;
for (int k = 0; k < size[i - 1]; k++)
{
network[i][j].output += network[i - 1][k].output * network[i - 1][k].weight[j];
}
network[i][j].output += network[i][j].threshold;
network[i][j].output = sig(network[i][j].output);
}
}
} double sig(double &x)
{
return 1.0 / (1.0 + exp(-x));
}三:计算权重更新、反向传导
由上期计算得出的公式,只实现了有三次网络的权重更新函数。
void bpNet::backchange(const vector<double> & predict, double & error)
{
double delta_total = 0.0;
double delta = 0.0;
double sum;
for (int i = 0; i < network[1].size(); i++)
{
for (int j = 0; j < network[2].size(); j++)
{
delta = -(predict[j] - network[2][j].output)*network[2][j].output*(1 - network[2][j].output)*network[1][i].output;//一阶偏导数
network[1][i].update_w[j] = /*network[1][i].weight[j] */- eta * delta;
if (train_num == 1 || train_num == 0)
{
network[1][i].ave_update_w[j] = 0;
}
network[1][i].ave_update_w[j] += network[1][i].update_w[j];
}
}
delta = 0.0;
for (int i = 0; i < network[0].size(); i++)
{
for (int j = 0; j < network[1].size(); j++)
{
sum = 0.0;
delta = network[1][j].output*(1 - network[1][j].output)*network[0][i].output;
for (int k = 0; k < network[2].size(); k++)
{
sum += -(predict[k] - network[2][k].output)*network[2][k].output*(1 - network[2][k].output)*network[1][j].weight[k];//神经网络第一层的偏导数
}
delta *= sum;
network[0][i].update_w[j] = /*network[0][i].weight[j]*/ - eta * delta;
if (train_num == 0||train_num==1)
{
network[0][i].ave_update_w[j] = 0;
}
network[0][i].ave_update_w[j] += network[0][i].update_w[j] /*+ network[0][i].ave_update_w[j]) / 2*/;
}
}
train_num++;
}
void bpNet::upweight()
{
for (int i = 0; i < network.size() - 1; i++)
{
for (int j = 0; j < network[i].size(); j++)
{
for(int k=0;k < network[i][j].weight.size();k++)
network[i][j].weight[k] += network[i][j].update_w[k];
}
}
}
void bpNet::upweight_ave()
{
for (int i = 0; i < network.size() - 1; i++)
{
for (int j = 0; j < network[i].size(); j++)
{
for (int k = 0;k < network[i][j].weight.size(); k++)
network[i][j].weight[k] += network[i][j].ave_update_w[k]/train_num;
}
}
train_num = 0;
}四:完整代码 包含存储,读取等
#pragma once
#include<vector>
#include<iostream>
#include<cstdlib>
using namespace std;
struct neuron
{
vector<double>weight;
vector<double>update_w;
vector<double>ave_update_w;
double output;
double threshold;
neuron()
:output(0),
update_w(0),
ave_update_w(0)
{}
};
typedef vector<neuron>layer;
struct read_type
{
vector<double> weight;
double threshold;
};
typedef vector<read_type> read_ly;
class bpNet
{
int train_num;
static double eta;
vector<layer>network;
public:
bpNet()
:train_num(0)
{};
void set(const vector<int> & network_);
~bpNet()
{};
static double sig(double &x)
{
return 1.0 / (1.0 + exp(-x));
}
void putdata(vector<double> &input_, const vector<int> & size);
void backchange(const vector<double> & predict, double &error);
void upweight();
void show() const;
void reset_ave_update_w(const vector<double> & network_);
void upweight_ave();
void save_network(const string& filename);
void load_file(const string& filename);
void read_set(vector<int>& line_num, vector<read_ly>& read_table);
};
double bpNet::eta = 1;
void bpNet::save_network(const string& filename)
{
FILE* fout = fopen(filename.c_str(),"wb");
int ly_size[3] = { network[0].size(),network[1].size(),network[2].size() };
fwrite(ly_size, sizeof(int), 3, fout);
for (int i = 0; i < 3; i++)
{
if (i != 2)
{
for (int j = 0; j < ly_size[i]; j++)
{
int weight_num = network[i][j].weight.size();
fwrite(&weight_num, sizeof(int), 1, fout);
for (int k = 0; k < weight_num; k++)
{
double put_weight = network[i][j].weight[k];
fwrite(&put_weight, sizeof(double), 1, fout);
}
double threshold = network[i][j].threshold;
fwrite(&threshold, sizeof(double), 1, fout);
}
}
if (i == 2)
{
for (int j = 0; j < 10; j++)
{
double threshold = network[i][j].threshold;
fwrite(&threshold, sizeof(int), 1, fout);
}
}
}
cout << "save finished!" << endl;
fclose(fout);
}
void bpNet::load_file(const string& filename)
{
FILE* fin = fopen(filename.c_str(), "rb");
int ly_num[3];
vector<int> network_;
network_.resize(3);
fread(ly_num, sizeof(int), 3, fin);
for (int i = 0; i < 3; i++)
{
network_[i]= ly_num[i];
}
vector<read_ly> ly_line;//line
ly_line.resize(3);
double read_wight=0;
for (int i = 0; i < 3; i++)
{
ly_line[i].resize(ly_num[i]);
if (i != 2)
{
for (int j = 0; j < ly_num[i]; j++)
{
int enu_num;
fread(&enu_num, sizeof(int), 1, fin);
ly_line[i][j].weight.resize(enu_num);
for (int k = 0; k < enu_num; k++)
{
fread(&read_wight, sizeof(double), 1, fin);
ly_line[i][j].weight[k] = read_wight;
}
double threshold;
fread(&threshold, sizeof(double), 1, fin);
ly_line[i][j].threshold = threshold;
}
}
if (i == 2)
{
for (int j = 0; j < 10; j++)
{
double threshold;
fread(&threshold, sizeof(double), 1, fin);
ly_line[i][j].threshold = threshold;
}
}
}
read_set(network_, ly_line);
}
void bpNet::read_set(vector<int>& network_, vector<read_ly>& read_table)
{
int layer_num = network_.size();
for (int i = 0; i < layer_num; i++)
{
network.push_back(layer());
for (int j = 0; j < network_[i]; j++)
{
network.back().push_back(neuron());
if (i > 0)
{
network[i][j].threshold = read_table[i][j].threshold;
}
if (i < layer_num - 1)
{
for (int k = 0; k < network_[i + 1]; k++)
{
network[i][j].weight.push_back(read_table[i][j].weight[k]);
network[i][j].update_w.push_back(0);
network[i][j].ave_update_w.push_back(0);
}
}
}
}
}
void bpNet::set(const vector<int> & network_)
{
int layer_num = network_.size();
for (int i = 0; i < layer_num; i++)
{
network.push_back(layer());
for (int j = 0; j < network_[i]; j++)
{
network.back().push_back(neuron());
if (i > 0)
{
network[i][j].threshold = 0.5;
}
if (i < layer_num - 1)
{
for (int k = 0; k < network_[i + 1]; k++)
{
network[i][j].weight.push_back(rand()*(rand() % 2 ? 1 : -1)*1.0 / RAND_MAX);
network[i][j].update_w.push_back(0);
network[i][j].ave_update_w.push_back(0);
}
}
}
}
}
void bpNet::putdata(vector<double> &in, const vector<int> & size)
{
for (int t = 0; t < size[0]; t++)
{
network[0][t].output = in[t];
}
for (int i = 1; i < size.size(); i++)
{
for (int j = 0; j < size[i]; j++)
{
network[i][j].output = 0;
for (int k = 0; k < size[i - 1]; k++)
{
network[i][j].output += network[i - 1][k].output * network[i - 1][k].weight[j];
}
network[i][j].output += network[i][j].threshold;
network[i][j].output = sig(network[i][j].output);
}
}
}
void bpNet::reset_ave_update_w(const vector<double> & network_)
{
int layer_num = network_.size();
for (int i = 0; i < layer_num; i++)
{
for (int j = 0; j < network_[i]; j++)
{
if (i < layer_num - 1)
{
for (int k = 0; k < network_[i + 1]; k++)
{
network[i][j].ave_update_w[k] = 0;
}
}
}
}
}
void bpNet::backchange(const vector<double> & predict, double & error)
{
double delta_total = 0.0;
double delta = 0.0;
double sum;
for (int i = 0; i < network[1].size(); i++)
{
for (int j = 0; j < network[2].size(); j++)
{
delta = -(predict[j] - network[2][j].output)*network[2][j].output*(1 - network[2][j].output)*network[1][i].output;//一阶偏导数
network[1][i].update_w[j] = /*network[1][i].weight[j] */- eta * delta;
if (train_num == 1 || train_num == 0)
{
network[1][i].ave_update_w[j] = 0;
}
network[1][i].ave_update_w[j] += network[1][i].update_w[j];
}
}
delta = 0.0;
for (int i = 0; i < network[0].size(); i++)
{
for (int j = 0; j < network[1].size(); j++)
{
sum = 0.0;
delta = network[1][j].output*(1 - network[1][j].output)*network[0][i].output;
for (int k = 0; k < network[2].size(); k++)
{
sum += -(predict[k] - network[2][k].output)*network[2][k].output*(1 - network[2][k].output)*network[1][j].weight[k];//神经网络第一层的偏导数
}
delta *= sum;
network[0][i].update_w[j] = /*network[0][i].weight[j]*/ - eta * delta;
if (train_num == 0||train_num==1)
{
network[0][i].ave_update_w[j] = 0;
}
network[0][i].ave_update_w[j] += network[0][i].update_w[j] /*+ network[0][i].ave_update_w[j]) / 2*/;
}
}
train_num++;
}
void bpNet::upweight()
{
for (int i = 0; i < network.size() - 1; i++)
{
for (int j = 0; j < network[i].size(); j++)
{
for(int k=0;k < network[i][j].weight.size();k++)
network[i][j].weight[k] += network[i][j].update_w[k];
}
}
}
void bpNet::upweight_ave()
{
for (int i = 0; i < network.size() - 1; i++)
{
for (int j = 0; j < network[i].size(); j++)
{
for (int k = 0;k < network[i][j].weight.size(); k++)
network[i][j].weight[k] += network[i][j].ave_update_w[k]/train_num;
}
}
train_num = 0;
}
void bpNet::show() const
{
for (int i = 0; i < network[2].size(); i++)
{
std::cout << "output" << i + 1 << "=" << network[2][i].output << std::endl;
}
}
到这里,BPnet的搭建就结束了,其中预留了两种权重更新方式,分别对应单输入源单结果,多输入源多结果的训练过程。
实际上,如果只实现单输入源的训练,神经网络最终只能做类似线性拟合的工作,并不能完成一些稍微高级的例如图像识别之类的功能。
手写数字识别的实现
问题简化:给定一张白底黑字的手写数字图片,由BPnet神经网络给出识别结果。
训练方法(重要):(给出一个合理的训练方法和原理,是本博客最想完成的任务。)
希望读者可以回想一下,在上一篇中我们对于训练原理的介绍:将神经网络看成是一个拟合函数,训练神经网络的目的是让偏差
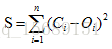
看起来没有问题,那么直接将这种思路应用到数字识别的神经网络训练中去可以吗?
一定不可以。(这是我在学习过程中感觉最坑的地方,训练方式的错误使得我一直无法得到拟合结果)
来看看为什么:
1.数字识别的功能是针对手写数字0~9,给出对应的结果。不可以将单个的数字看作一个输入,应该将一组数字看作一次输入,而他们各自的输出综合起来,看作一次输出。why?试想,如果每一次给神经网络一张图片作为输入,接着马上对其求梯度,更新权重,根据我们的计算思路,这样做其实是将神经网络看作了对单一图片的拟合函数。你可能会问,我们可以不断地更换输入图片来完成这件事啊?但是,更换图片只不过将函数的拟合目标更换了,大概相当于:让BPnet对函数1做一次拟合,再对函数2做一次拟合,再对函数3做一次拟合......这样一定得不到预期结果,得到的只不过是一个几乎不合任何一个目标函数拟合的结果。
2.要怎样抽象手写数字的识别过程。请读者展开想象,这里不需要较强的数学思维。假设我们收集了全世界的手写数字图片,并且给他们进行的编码,那么把这些全部的图片看作一个输入,将已知的结果看作一个输出,那么这将是一个无穷输入,无穷输出的BPnet网络。然后计算梯度,改变权重,更新阈值,重新输入上述权重,重复更新过程。这样是不是就得出了一个与全世界手写数字拟合的神经网络了呢?再来任意的一张手写数字,它一定接近于我们训练用输入中的某个数,由连续函数的性质,极限值等于函数值,神经网络一定可以给出一个合理的识别结果。
3.上述方法天马行空的,理论正确,无法操作。实际上,我们只要有足够多的训练数据就够了,不需要全世界的手写数字。假设我们获得了10000个训练数据,然后将这10000个数据作为输入,求梯度。这样可以吗?还是不行,因为我们的BPnet要求每次只输入一张图,得到一个识别结果。所以给出以下训练方法:一次输入10000张图中的各张图,分别记录权重的修改(也就是梯度),求其平均值,更新权重。这样就可以得到正确的拟合。
4.然而,10000的数据作为输入,进行一次调整,计算量太大了,训练时间太长,还会因为计算机的截断误差之类的原因造成十分巨大的误差。所以,实际操作中,将10000个数据打乱,分成若干组,例如分为500组,这样每组只有个20个数据,再依次输入,调整。这样可以吗?似乎还是有些问题:这样不就回到了(1)中提到的:让BPnet对函数1做一次拟合,再对函数2做一次拟合,再对函数3做一次拟合...... 了吗?确实如此,但是,因为数字识别的目标函数可以认为是确定了,我们将若干个数据分为一组,这样得出的函数并不一定就是数字识别函数真正的样子,但是已经和接近了。也就是说,尽管每次训练都让BPnet拟合了不同和函数,但因为这些函数长得都差不多,很接近,可以认为是同一个函数,所以我们得到的拟合结果,可以认为是正确的。
给出代码:
对BPnet封装:
#pragma once
#include "bpnet.h"
#define SIZE 15
#include "stdafx.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include "cv.h"
#include <vector>
#include "bpnet.h"
#define TOUTLE 100
using namespace std;
using namespace cv;
class Train
{
public:
void train();
void read();
void save();
void get_train_data();
void read_num();
void load_train();
private:
bpNet bpnet;
vector<vector<double>> data_in;
vector<vector<double>> data_out;
};
void Train::get_train_data()
{
char group;
group = '2';
string filename;
for (int i = 0; i < 10; i++)
{
filename = "C:\\Users\\Administrator\\source\\repos\\ConsoleApplication2\\ConsoleApplication2\\train_data\\";
filename += i + '0';
filename += ".";
filename += group;
filename += ".bmp";
vector<double> table;
table.resize(SIZE*SIZE);
Mat image = imread(filename.c_str(), 0);
Mat newima;
resize(image, newima, Size(SIZE, SIZE));
imwrite("tmp.bmp", newima);
int count = 0;
IplImage* src = cvLoadImage("tmp.bmp", 0);//导入图片
int width = src->width;//图片宽度
int height = src->height;//图片高度
for (size_t row = 0; row<height; row++)
{
uchar* ptr = (uchar*)src->imageData + row * src->width;//获得灰度值数据指针
for (size_t cols = 0; cols<width; cols++)
{
int intensity = ptr[cols];
table[count] = intensity;
count++;
}
}
data_in.push_back(table);
vector<double> out_data;
out_data.resize(10);
for (int j= 0; j < 10; j++)
{
out_data[j] = 0;
}
out_data[i] = 1;
data_out.push_back(out_data);
}
}
void Train::read_num()
{
string filename;
filename = "read_num\\read.bmp";
vector<double> table;
table.resize(SIZE*SIZE);
Mat image = imread(filename.c_str(), 0);
Mat newima;
resize(image, newima, Size(SIZE, SIZE));
imwrite("tmp.bmp", newima);
int count = 0;
IplImage* src = cvLoadImage("tmp.bmp", 0);//导入图片
int width = src->width;//图片宽度
int height = src->height;//图片高度
for (size_t row = 0; row<height; row++)
{
uchar* ptr = (uchar*)src->imageData + row * src->width;//获得灰度值数据指针
for (size_t cols = 0; cols<width; cols++)
{
int intensity = ptr[cols];
table[count] = intensity;
count++;
}
}
vector<int>ly{ SIZE*SIZE,50,10 };
bpnet.putdata(table, ly);
bpnet.show();
}
void Train::read()
{
string filename;
filename = "netdata.save";
bpnet.load_file(filename);
}
void Train::save()
{
string filename;
filename = "netdata.save";
bpnet.save_network(filename);
}
void Train::train()
{
int input_num = data_in.size();
int output_num = data_out.size();
if (input_num != output_num)
{
cout << "参数错误" << endl;
return;
}
double error = 1;
vector<int>ly{ SIZE*SIZE,50,10 };
bpnet.set(ly);
int toutle = TOUTLE;
for (int times = 0; times < toutle; times++)
{
for (int i = 0; i < input_num; i++)
{
bpnet.putdata(data_in[i], ly);
bpnet.backchange(data_out[i], error);
bpnet.upweight_ave();
//upweight();
}
//bpnet.upweight_ave();
cout << (times + 1)*100/toutle<< "%" << endl;
if( ((times + 1) * 100 / toutle)%5==0 )
{
for (int i = 0; i < input_num; i++)
{
cout << "======================================" << endl;
cout << "for" << i << endl;
bpnet.putdata(data_in[i], ly);
bpnet.show();
cout << endl;
}
this->save();
}
}
for (int i = 0; i < input_num; i++)
{
cout << "======================================" << endl;
cout << "for" << i << endl;
bpnet.putdata(data_in[i], ly);
bpnet.show();
cout << endl;
}
this->save();
}
void Train::load_train()
{
int input_num = data_in.size();
int output_num = data_out.size();
if (input_num != output_num)
{
cout << "参数错误" << endl;
return;
}
double error = 1;
vector<int>ly{ SIZE*SIZE,50,10 };
//bpnet.set(ly);
this->read();
int toutle = TOUTLE;
for (int times = 0; times < toutle; times++)
{
for (int i = 0; i < input_num; i++)
{
bpnet.putdata(data_in[i], ly);
bpnet.backchange(data_out[i], error);
bpnet.upweight();
}
//bpnet.upweight_ave();
cout << (times + 1) * 100 / toutle << "%" << endl;
if (((times + 1) * 100 / toutle) % 5 == 0)
{
for (int i = 0; i < input_num; i++)
{
cout << "======================================" << endl;
cout << "for" << i << endl;
bpnet.putdata(data_in[i], ly);
bpnet.show();
cout << endl;
}
this->save();
}
}
for (int i = 0; i < input_num; i++)
{
cout << "======================================" << endl;
cout << "for" << i << endl;
bpnet.putdata(data_in[i], ly);
bpnet.show();
cout << endl;
}
this->save();
}测试:
#include "stdafx.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include"highgui.h"
#include"cv.h"
#include <vector>
#include "bpnet.h"
#include "training.h"
#define SIZE 15
using namespace std;
using namespace cv;
void test()
{
Train train;
train.get_train_data();
train.train();
train.save();
}
int main()
{
test();
system("pause");
return 0;
}如有错误,或者建议,请在评论区评论,再次感谢您的阅读。
END。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









