









💗博主介绍:✌全网粉丝15W+,CSDN全栈领域优质创作者,博客之星、掘金/知乎/b站/华为云/阿里云等平台优质作者、专注于Java、小程序/APP、python、大数据等技术领域和毕业项目实战,以及程序定制化开发、文档编写、答疑辅导等。
👇🏻 精彩专栏 推荐订阅👇🏻
计算机毕业设计精品项目案例(持续更新)
🌟文末获取源码+数据库+文档🌟
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以和学长沟通,希望帮助更多的人
一.前言
越来越多的学生选择通过考研来提升自己的学术水平和职业竞争力。然而,考研信息的分散性和动态性给考生带来了极大的信息搜集成本和决策困难。针对这一问题,本文设计并实现了一个基于网络爬虫技术和数据分析的考研信息集成系统,旨在高效、准确地收集、整合和分析考研相关信息,辅助考生做出更明智的选择。系统的功能模块,主要包括院校信息爬取、专业信息汇总、考试资料整理、资料类型以及用户个性化推荐等。
该系统通过对大量考研数据进行挖掘和分析,实现了对考研信息的多维度、多层次的可视化展示,从而帮助用户快速了解考研市场的整体态势和细节特征。考研信息大数据分析和可视化展示二者是相辅相成的,考研大数据环境具有信息分散、数据结构不统一的特点,难以将大数据调入应用系统中进行数据价值的体现,而数据可视化分析是有效适应考研大数据的复杂环境和满足大数据分析有效执行的客观方法。因此,本文利用Echarts通过借助图形化的手段,准确分析大数据和可视化之间的关系,进而有效地分析考研信息变化的情况,发现大数据背景下所隐藏的丰富信息,增强大数据价值。
二.技术环境
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
爬虫框架:Scrapy
大数据框架:Hadoop
开发软件:PyCharm/vs code
前端框架:vue.js
三.功能设计
(1)系统前台模块功能
首页、考研资料(下载及上传等)、考研论坛、考研资讯、考研招录信息、报考咨询等
(2)系统后台模块功能
用户管理、考研资料管理、考研论坛管理、考研资讯管理、报考咨询与回复管理、以及数据可视化大屏展示
系统总体功能结构图如下所示:

四.数据设计
考研信息爬虫与分析需要数据库存储系统中的信息,MySQL数据库能够处理系统的信息,当考研信息爬虫与分析需要数据的时候,MySQL数据库能够取得数据交给服务端处理。MySQL数据库能够使用可视化软件操作,管理员可以在可视化软件对数据库的信息机芯管理。
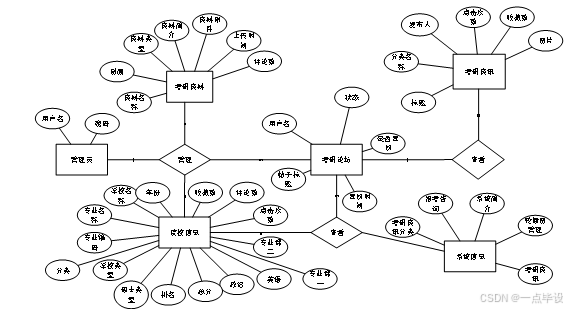
系统数据层设计包括了E-R设计,系统数据实体的设计依赖于E-R的分析和设计,通过E-R能够得到数据库表的设计,E-R能够描述系统所涉及到的实体,还能够描述系统中不同实体的联系和关系。系统总体E-R图如下所示:
五.部分效果展示
5.1前台用户功能实现效果
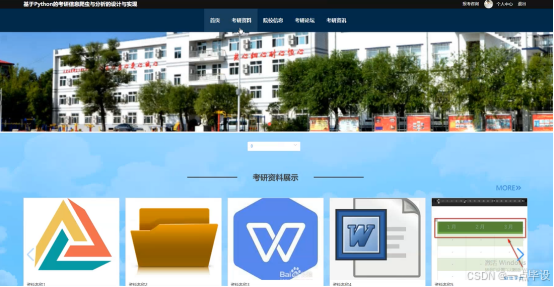
系统的首页,如果没有登录情况下首页可以查看首页、考研资料、院校信息、考研论坛、考研资讯、报考咨询、个人中心,首页如图所示。
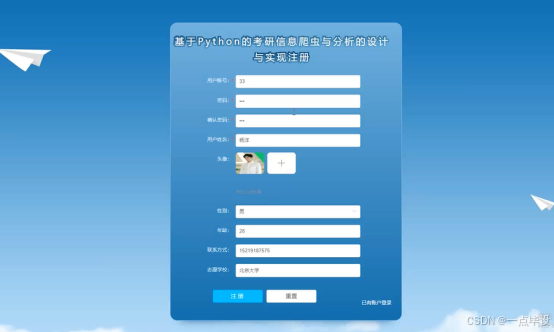
在注册流程中,用户在Vue前端填写必要信息(如用户账号、密码等)并提交。前端将这些信息通过HTTP请求发送到Python后端。后端处理这些信息,检查用户名是否唯一,并将新用户数据存入MySQL数据库。完成后,后端向前端发送注册成功的确认,前端随后通知用户完成注册。这个过程实现了新用户的数据收集、验证和存储。如图所示。
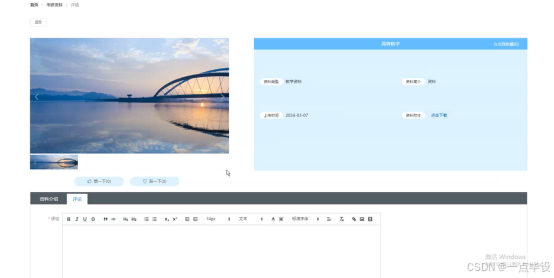
用户点击考研资料,在考研资料页面的搜索栏输入资料名称、资料简介,进行查询,可以查看资料名称、封面、用户、资料简介、资料附件、上传时间、评论数等信息;如有需要可以点击下载、收藏、赞踩一下或评论,如图所示:
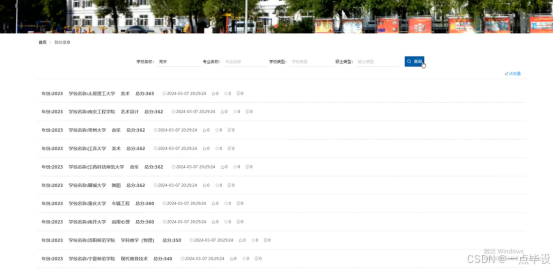
用户点击院校信息,在院校信息页面的搜索栏输入学校名称、专业名称、学校类型、硕士类型,进行查询,可以查看年份、学校名称、 专业名称、专业编码、分类、学校类型、硕士类型、排名、总分、政治、英语、专业课一、专业课二、点击次数、评论数、收藏数等信息,如有需要还可以关注等操作。如图所示:
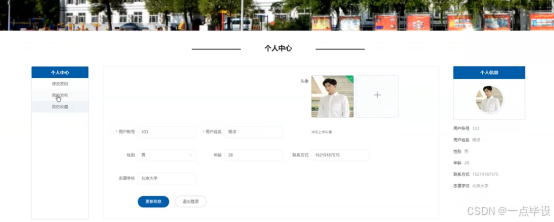
用户点击个人中心,在个人中心页面用户可以修改个人信息,也可以对修改密码、我的发布、我的收藏进行详细操作,如图所示:
5.2后台管理员功能实现效果
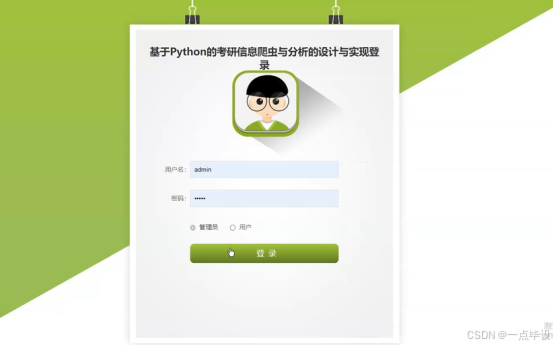
在登录界面中需要使用el-input标签实现输入框供管理员输入用户名和密码,需要使用name标签表示不同的信息。在登录界面中还需要包括角色的按钮,使用el-radio表示按钮,管理员可以点击按钮从而选择不同的角色,如图所示。
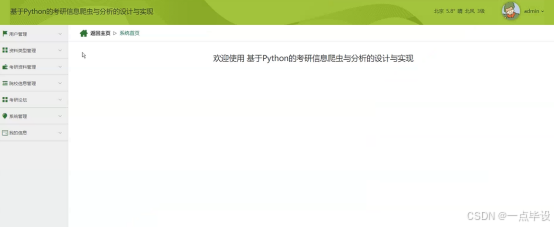
管理员登录进入考研信息爬虫与分析可以查看系统首页、用户管理、资料类型管理、考研资料管理、院校信息管理、考研论坛、系统管理、我的信息等功能,进行详细操作,如图所示。
管理员点考研资料管理;在考研资料管理页面输入资料名称、封面、资料类型、资料简介、资料附件、上传时间、评论数等信息,进行搜索,新增删除或考研资料类信息等操作;如图所示。
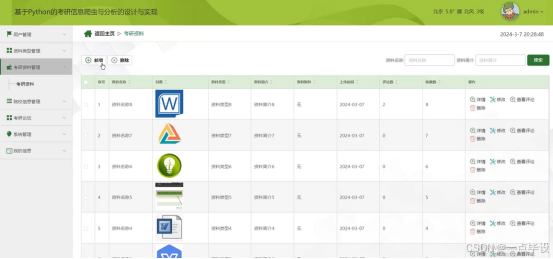
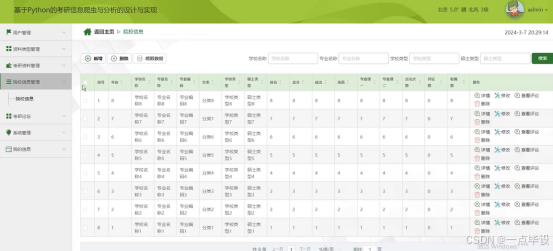
管理员点击院校信息管理;在院校信息管理页面输入年份、学校名称、 专业名称、专业编码、分类、学校类型、硕士类型、排名、总分、政治、英语、专业课一、专业课二、点击次数、评论数、收藏数 规模等信息,进行新增或删除院校信息,还可以爬取数等操作;如图所示。
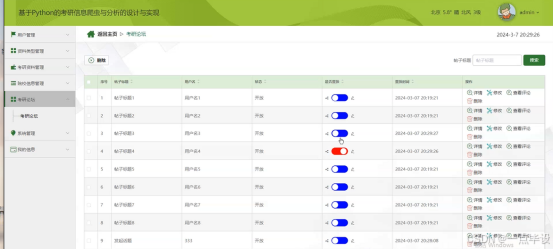
管理员点击考研论坛;在考研论坛页面输入帖子标题、用户名、状态、是否置顶、置顶时间等信息,进行查询或删除考研论坛等操作;如图所示。
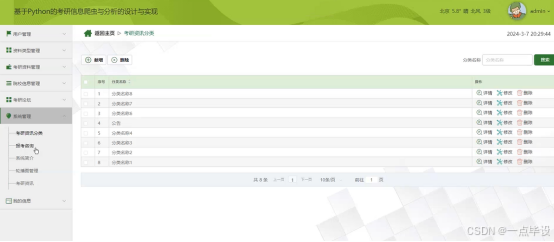
管理员点击系统管理;在系统管理页面输入考研资讯分类、报考咨询、系统简介、轮播图管理、考研资讯等信息,进行新增或删系统信息等操作;如图所示。
管理员点击考研资讯;在考研资讯页面对标题、分类名称、发布人、点击次数、收藏数、图片等信息,进行修改或删考研资讯等操作;如图所示。
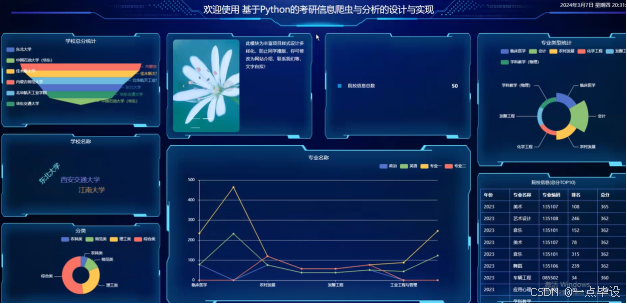
5.3可视化大屏展示功能实现效果
考研信息爬虫与分析的设计与实现基本情况分析展示,如图所示。
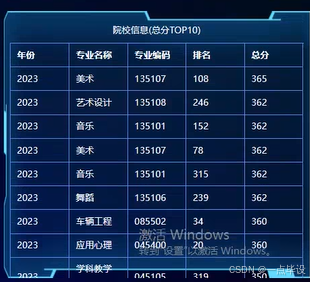
对于院校信息(总分top10)获取之后,开始对这些数据进行可视化分析,首先是院校信息(总分top10)的基本情况,通过信息表的形式展示,如图所示。
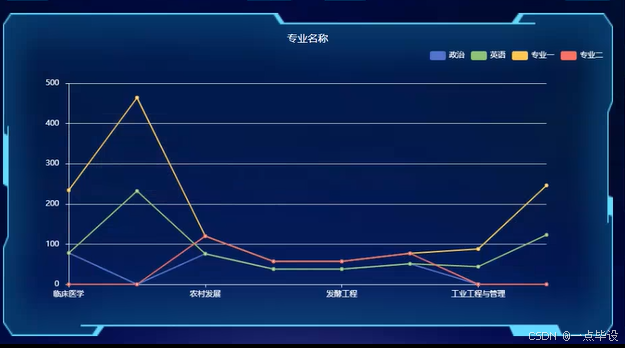
下图是专业名称,通过python爬取清洗后以折线图展示,如图所示:
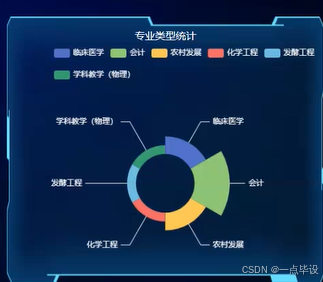
下面是专业类型统计用玫瑰图形式展示,如图所示:
六.部分功能代码
# # -*- coding: utf-8 -*-
# 数据爬取文件
import scrapy
import pymysql
import pymssql
from ..items import YuanxiaoxinxiItem
import time
from datetime import datetime,timedelta
import datetime as formattime
import re
import random
import platform
import json
import os
import urllib
from urllib.parse import urlparse
import requests
import emoji
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from selenium.webdriver import ChromeOptions, ActionChains
from scrapy.http import TextResponse
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
# 院校信息
class YuanxiaoxinxiSpider(scrapy.Spider):
name = 'yuanxiaoxinxiSpider'
spiderUrl = 'https://api.kaoyan.cn/pc/school/schoolList'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
realtime = False
def __init__(self,realtime=False,*args, **kwargs):
super().__init__(*args, **kwargs)
self.realtime = realtime=='true'
def start_requests(self):
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'do3uy2w0_yuanxiaoxinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
pageNum = 1 + 1
for url in self.start_urls:
if '{}' in url:
for page in range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(
url=next_link,
callback=self.parse
)
else:
yield scrapy.Request(
url=url,
callback=self.parse
)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'do3uy2w0_yuanxiaoxinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
data = json.loads(response.body)
try:
list = data["data"]["data"]
except:
pass
for item in list:
fields = YuanxiaoxinxiItem()
try:
fields["schoolname"] = str(emoji.demojize(self.remove_html( item["school_name"] )))
except:
pass
try:
fields["typename"] = str(emoji.demojize(self.remove_html( item["type_name"] )))
except:
pass
try:
fields["typeschool"] = str(emoji.demojize(self.remove_html( item["type_school_name"] )))
except:
pass
try:
fields["ranking"] = int( item["rk_rank"])
except:
pass
detailUrlRule = item["school_id"]
if '["school_id"]'.startswith('http'):
if '{0}' in '["school_id"]':
detailQueryCondition = []
detailUrlRule = '["school_id"]'
i = 0
while i < len(detailQueryCondition):
detailUrlRule = detailUrlRule.replace('{' + str(i) + '}', str(detailQueryCondition[i]))
i += 1
else:
detailUrlRule =item["school_id"]
detailUrlRule ='https://static.kaoyan.cn/json/score/2023/'+ detailUrlRule+'/0/1.json'
if detailUrlRule.startswith('http') or self.hostname in detailUrlRule:
pass
else:
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
fields["laiyuan"] = detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, callback=self.detail_parse)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''["degree_type_name"]''':
fields["degreename"] = str( re.findall(r'''["degree_type_name"]''', response.text, re.S)[0].strip())
else:
if 'degreename' != 'xiangqing' and 'degreename' != 'detail' and 'degreename' != 'pinglun' and 'degreename' != 'zuofa':
fields["degreename"] = str( self.remove_html(response.css('''["degree_type_name"]''').extract_first()))
else:
try:
fields["degreename"] = str( emoji.demojize(response.css('''["degree_type_name"]''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''["special_name"]''':
fields["specialname"] = str( re.findall(r'''["special_name"]''', response.text, re.S)[0].strip())
else:
if 'specialname' != 'xiangqing' and 'specialname' != 'detail' and 'specialname' != 'pinglun' and 'specialname' != 'zuofa':
fields["specialname"] = str( self.remove_html(response.css('''["special_name"]''').extract_first()))
else:
try:
fields["specialname"] = str( emoji.demojize(response.css('''["special_name"]''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''["special_code"]''':
fields["specialcode"] = str( re.findall(r'''["special_code"]''', response.text, re.S)[0].strip())
else:
if 'specialcode' != 'xiangqing' and 'specialcode' != 'detail' and 'specialcode' != 'pinglun' and 'specialcode' != 'zuofa':
fields["specialcode"] = str( self.remove_html(response.css('''["special_code"]''').extract_first()))
else:
try:
fields["specialcode"] = str( emoji.demojize(response.css('''["special_code"]''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''["year"]''':
fields["year"] = int( re.findall(r'''["year"]''', response.text, re.S)[0].strip())
else:
if 'year' != 'xiangqing' and 'year' != 'detail' and 'year' != 'pinglun' and 'year' != 'zuofa':
fields["year"] = int( self.remove_html(response.css('''["year"]''').extract_first()))
else:
try:
fields["year"] = int( emoji.demojize(response.css('''["year"]''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''["total"]''':
fields["total"] = int( re.findall(r'''["total"]''', response.text, re.S)[0].strip())
else:
if 'total' != 'xiangqing' and 'total' != 'detail' and 'total' != 'pinglun' and 'total' != 'zuofa':
fields["total"] = int( self.remove_html(response.css('''["total"]''').extract_first()))
else:
try:
fields["total"] = int( emoji.demojize(response.css('''["total"]''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''["politics"]''':
fields["politics"] = int( re.findall(r'''["politics"]''', response.text, re.S)[0].strip())
else:
if 'politics' != 'xiangqing' and 'politics' != 'detail' and 'politics' != 'pinglun' and 'politics' != 'zuofa':
fields["politics"] = int( self.remove_html(response.css('''["politics"]''').extract_first()))
else:
try:
fields["politics"] = int( emoji.demojize(response.css('''["politics"]''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''["english"]''':
fields["english"] = int( re.findall(r'''["english"]''', response.text, re.S)[0].strip())
else:
if 'english' != 'xiangqing' and 'english' != 'detail' and 'english' != 'pinglun' and 'english' != 'zuofa':
fields["english"] = int( self.remove_html(response.css('''["english"]''').extract_first()))
else:
try:
fields["english"] = int( emoji.demojize(response.css('''["english"]''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''["special_one"]''':
fields["specialone"] = int( re.findall(r'''["special_one"]''', response.text, re.S)[0].strip())
else:
if 'specialone' != 'xiangqing' and 'specialone' != 'detail' and 'specialone' != 'pinglun' and 'specialone' != 'zuofa':
fields["specialone"] = int( self.remove_html(response.css('''["special_one"]''').extract_first()))
else:
try:
fields["specialone"] = int( emoji.demojize(response.css('''["special_one"]''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''["special_two"]''':
fields["specialtwo"] = int( re.findall(r'''["special_two"]''', response.text, re.S)[0].strip())
else:
if 'specialtwo' != 'xiangqing' and 'specialtwo' != 'detail' and 'specialtwo' != 'pinglun' and 'specialtwo' != 'zuofa':
fields["specialtwo"] = int( self.remove_html(response.css('''["special_two"]''').extract_first()))
else:
try:
fields["specialtwo"] = int( emoji.demojize(response.css('''["special_two"]''').extract_first()))
except:
pass
except:
pass
return fields
# 数据清洗
def pandas_filter(self):
engine = create_engine('mysql+pymysql://root:123456@localhost/spiderdo3uy2w0?charset=UTF8MB4')
df = pd.read_sql('select * from yuanxiaoxinxi limit 50', con = engine)
# 重复数据过滤
df.duplicated()
df.drop_duplicates()
#空数据过滤
df.isnull()
df.dropna()
# 填充空数据
df.fillna(value = '暂无')
# 异常值过滤
# 滤出 大于800 和 小于 100 的
a = np.random.randint(0, 1000, size = 200)
cond = (a<=800) & (a>=100)
a[cond]
# 过滤正态分布的异常值
b = np.random.randn(100000)
# 3σ过滤异常值,σ即是标准差
cond = np.abs(b) > 3 * 1
b[cond]
# 正态分布数据
df2 = pd.DataFrame(data = np.random.randn(10000,3))
# 3σ过滤异常值,σ即是标准差
cond = (df2 > 3*df2.std()).any(axis = 1)
# 不满⾜条件的⾏索引
index = df2[cond].index
# 根据⾏索引,进⾏数据删除
df2.drop(labels=index,axis = 0)
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into `yuanxiaoxinxi`(
id
,schoolname
,typename
,typeschool
,ranking
,degreename
,specialname
,specialcode
,year
,total
,politics
,english
,specialone
,specialtwo
)
select
id
,schoolname
,typename
,typeschool
,ranking
,degreename
,specialname
,specialcode
,year
,total
,politics
,english
,specialone
,specialtwo
from `do3uy2w0_yuanxiaoxinxi`
where(not exists (select
id
,schoolname
,typename
,typeschool
,ranking
,degreename
,specialname
,specialcode
,year
,total
,politics
,english
,specialone
,specialtwo
from `yuanxiaoxinxi` where
`yuanxiaoxinxi`.id=`do3uy2w0_yuanxiaoxinxi`.id
))
order by rand()
limit 50;
'''
cursor.execute(sql)
connect.commit()
connect.close()
源码及文档获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏👇🏻
最新计算机毕业设计选题篇-选题推荐
小程序毕业设计精品项目案例-200套
Java毕业设计精品项目案例-200套
Python毕业设计精品项目案例-200套
大数据毕业设计精品项目案例-200套
💟💟如果大家有任何疑虑,欢迎在下方位置详细交流。


















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











