









参考
Label Embedding
在普通的训练过程中,只会在最后loss的计算阶段会用到label信息,是否可以在其它阶段就应用起来呢?这就是label embedding。一般我们在使用lstm时,通常会采用最后一个时刻的值来做为句子embedding然后给到分类层,对于bert类模型一般使用的cls的值。

但实际上,不同类别的样本每个token对于目标的权重可能是不同的,那如果对每个token的值做一个加权求和来表示句子embedding是否是更合理呢?如下图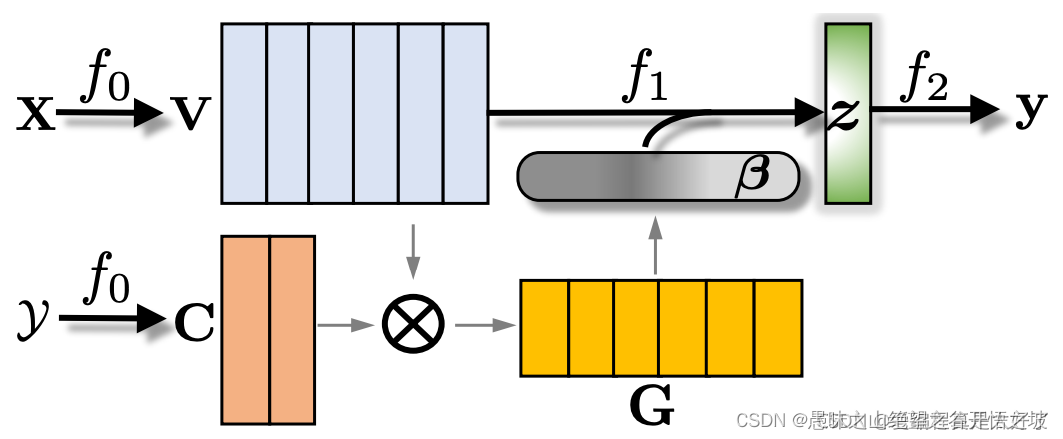
我们事先对label做一个转文本的处理,然后把文本转换成对应的embedding,如果你的类别很难表示成文本信息,那么你可以直接把类别乘一个embedding matrix得到embedding,然后把label embedding与每一个token的embedding做类attention处理得到权重,再对token embedding进行加权求和得到最终的句子embedding。
总结:同一个 embedding space 进行 label-embedding;
label-embedding 和 word-embedding建立点乘矩阵,通过maxpooling降维,softmax转为attention,再与word-embedding进行相乘
应用:两种embedding交互,直接attteion然后降维, 或者融入 maxpooling,增强信息
预测阶段和普通的方法略有不同,需要把所有label的embedding都计算一遍,最后判断哪个结果最大就属于哪一个类别。label embedding提前引入了一些label信息来加快模型的收敛,从而缓解长尾问题带来的负面影响。
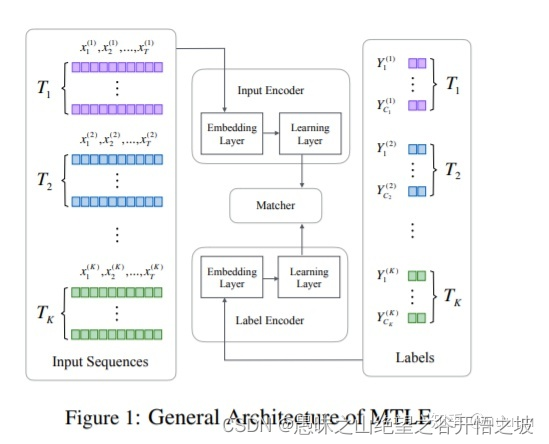
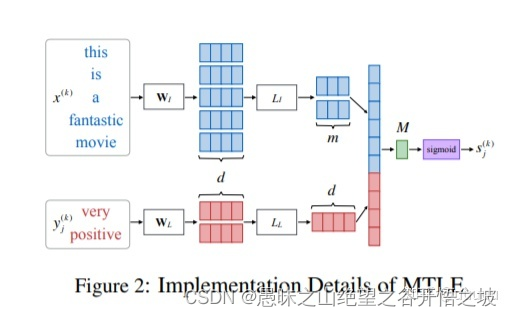
这里的label embedding, 指的是,将一个label下的样本归纳成一个向量,新的预测样本,encode之后,与这个向量去计算一个score,最后得到该样本的predict label。
Multi-Task Label Embedding for Text Classification

















 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









