








在本文中,试图通过进一步构造具有文本到标签注意的文本参与的标签表示来开发标签信息。为此,提出了一种带有标签嵌入的协同注意网络(CNLE),该网络将文本和标签共同编码到它们相互参与的表示中。通过这种方式,模型能够兼顾两者的相关部分。实验表明,在7个多分类基准和2个多标签分类基准上,我们的方法与现有的最先进的方法相比,取得了有竞争力的结果。
考虑一个包含
m
m
m个词的文本
x
x
x以及包含
c
c
c个标签的标签序列
l
l
l,目标是将二者的序列信息融合,得到标签增强的文本表示
z
x
∣
l
z_{x|l}
zx∣l以及文本增强的
z
l
∣
x
z_{l|x}
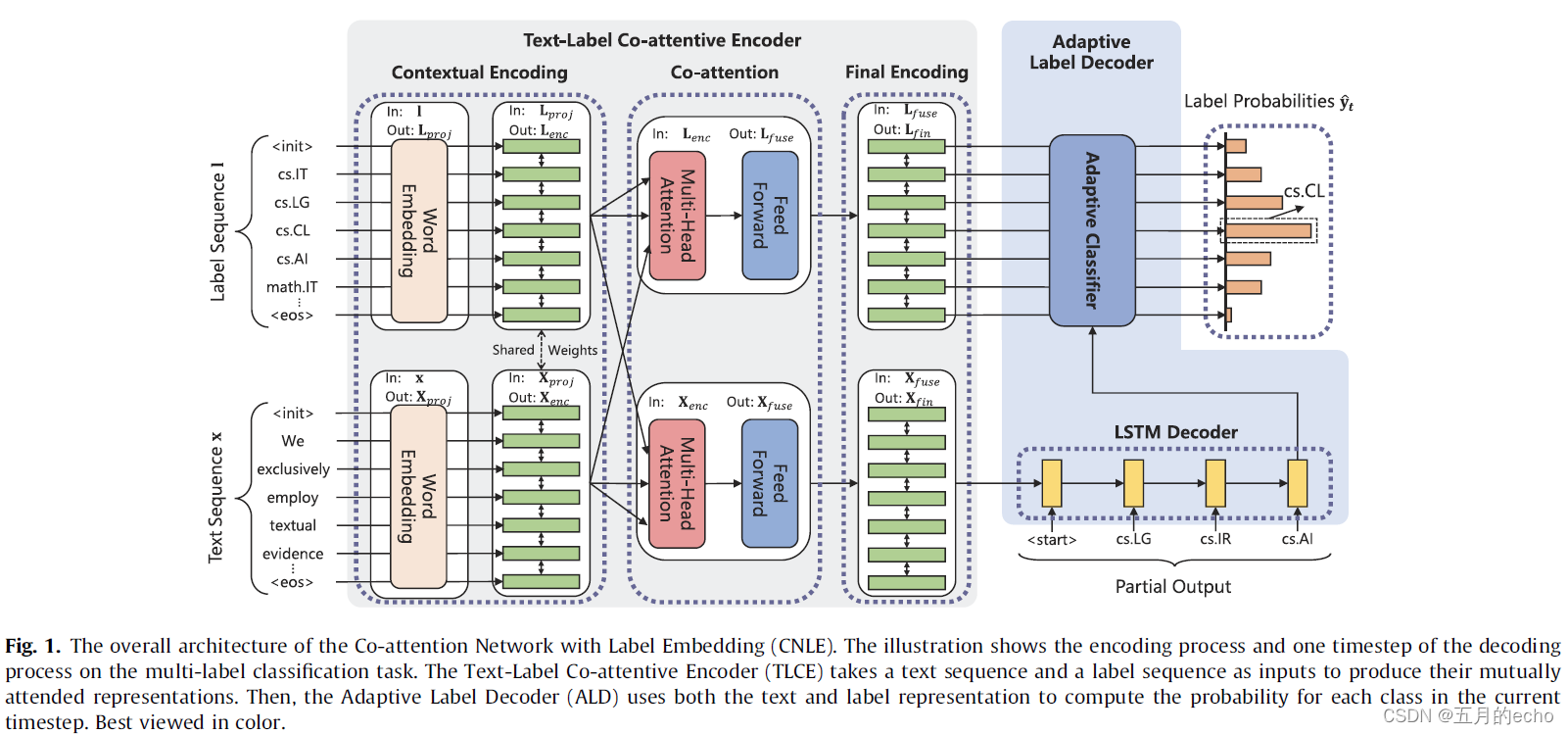
zl∣x。如图所示,模型主要分为Text-Label Co-attentive Encoder (TLCE)以及Adaptive Label Decoder (ALD)两部分。
TLCE
首先,使用预先训练好的单词向量对单词嵌入进行初始化,而对标签嵌入进行随机初始化,然后采用两个独立的线性投影层进行投影,得到
x
p
r
o
j
∈
R
m
∗
d
x_{proj}\in R^{m*d}
xproj∈Rm∗d以及
l
p
r
o
j
∈
R
c
∗
d
l_{proj}\in R^{c*d}
lproj∈Rc∗d两部分。之后,使用简单的BiLSTM进行顺序特征提取:

之后,稍微改写self-attention进行文本编码和标签编码之间的注意力相互影响:

其中MultiHead是多头的self-attention。之后,同样使用了FNN以及layer normalization:

之后,使用两个独立的bilstm分别传播融合文本编码和融合标签编码中相互参与的信息。一个BiLSTM将融合后的文本编码
X
f
u
s
e
X_{fuse}
Xfuse编码成文本最终表示形式
X
f
i
n
X_{fin}
Xfin:

同样,也对
L
f
u
s
e
L_{fuse}
Lfuse进行操作:

ALD
最终,对上述的两个分别代表标签和文本的特征执行ALD解码,ALD的解码过程分为两个步骤:1)利用LSTM解码器获得隐藏状态、单元状态和循环上下文状态;2)通过自适应分类器计算每个类的概率。
解码的过程就是使用LSTM生成标签序列,每次解码都可以表述为一个标准的LSTMCell计算:

其中
e
t
−
1
∈
R
d
∗
1
e_{t-1}\in R^{d*1}
et−1∈Rd∗1表示上一个时间步的标签的表示。对于训练过程,使用上一个ground-truth标签;在推断的时候则很明显要使用当前解码器生成(预测)的标签。
r
t
−
1
∈
R
d
∗
1
r_{t-1}\in R^{d*1}
rt−1∈Rd∗1表示当前step文本的上下文表示,
h
t
−
1
,
c
t
−
1
h_{t-1}, c_{t-1}
ht−1,ct−1分别为上一个时间步的隐状态以及cell状态。
隐藏状态与文本之间的相互影响用注意力去建模:

那么,基于当前状态的上下文信息可以表示为:

最终,自适应的分类器为:

损失函数既可以用于多标签也可以用于单标签:

其中
1
[
.
]
1[.]
1[.]表示一个指示函数,如果内部条件为真则为1,否则为0。
Experiments
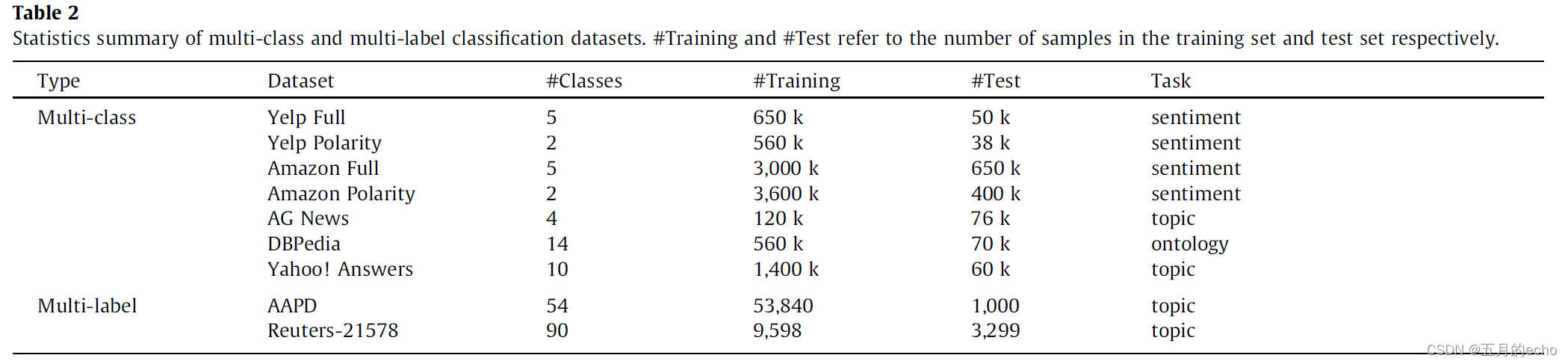
数据集是单标签和多标签常用的数据集:
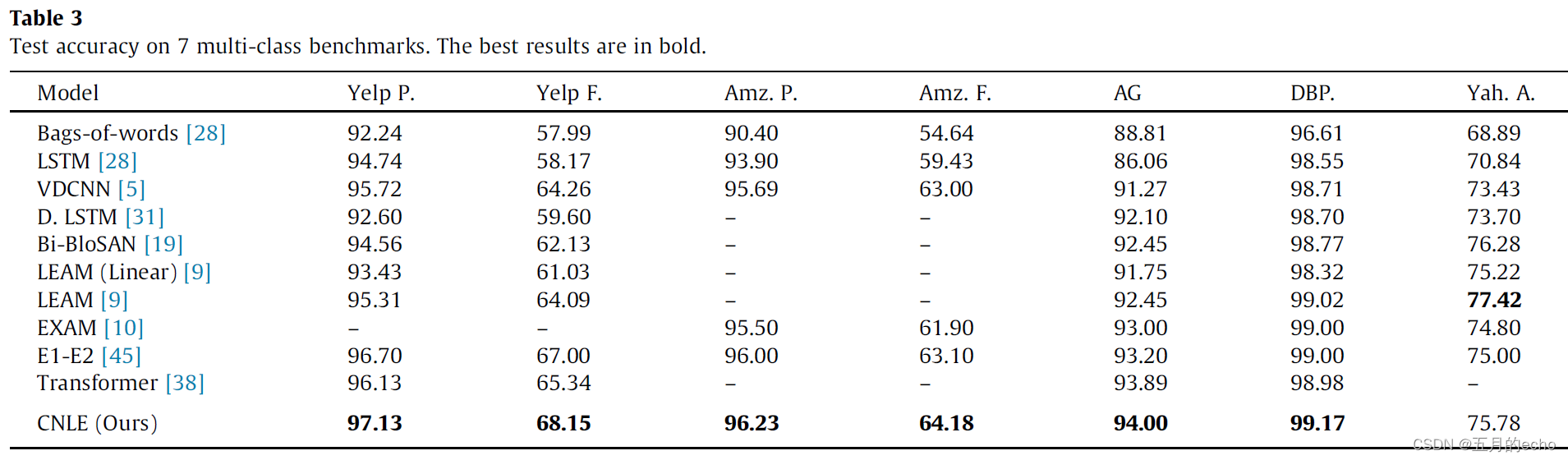
准确率:
micro-F1:

消融实验:


与预训练方法对比以及参数对比:

文档与标签之间多头注意力的可视化:
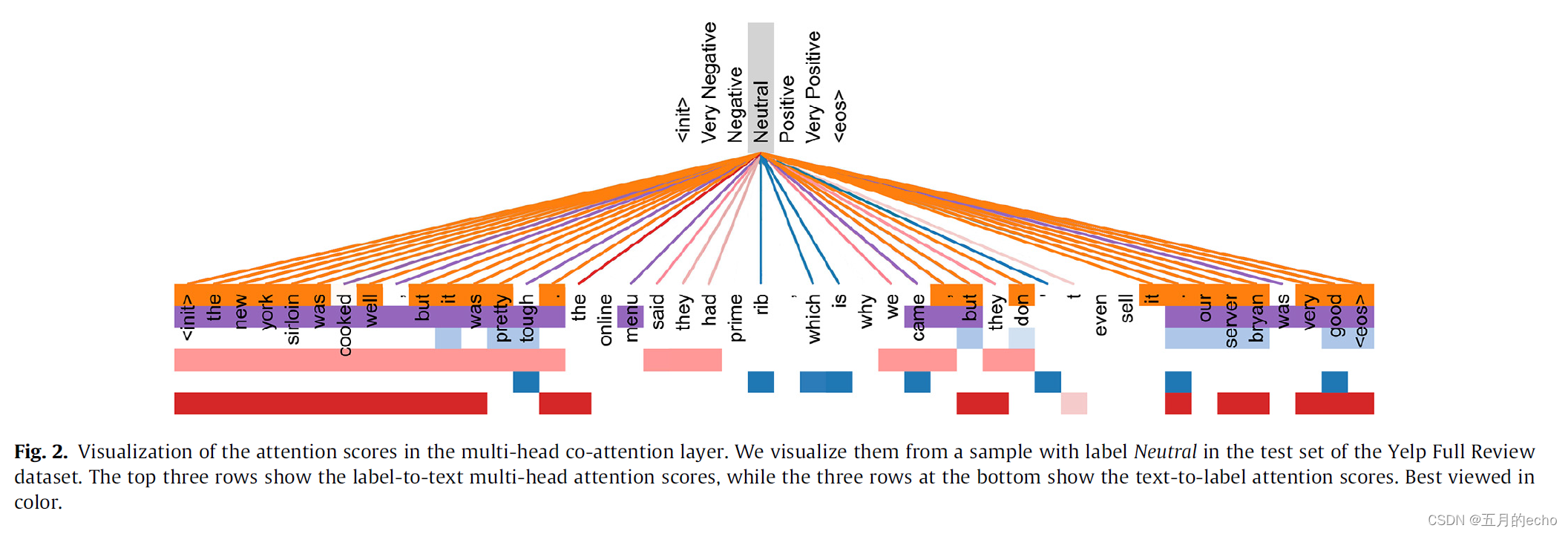
多头注意模块中的一些注意头被证明是冗余的,因此,在多余的头部上相应的注意力得分是没有区别的,使它们看起来相似。然而,有些注意头(如图2中橙色、浅蓝色和蓝色)具有足够的辨别能力,便于分类。
















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











