







概述
什么是oozie
Oozie是操作Hadoop job的工作流调度系统
Oozie工作流由一些有向无环图(DAG)的action组成
Oozie的定时器coordinator由时间或者时间和数据同时触发
Oozie的action可以是hadoop生态系的任务,比如mr,pig,hive,sqoop等,也可以是外部任务,比如java程序,shell程序等
Oozie是可扩展,可靠的工作流系统
1-2apache oozie安装和配置[24:32]
1-3apache oozie的脚本分析[17:31]
1-4cdh6 oozie安装和配置[07:51]
1-5oozie第一个例子[11:40]
第2章 cdh6 oozie基础教程
1小时58分钟18节
2-1cdh6 oozie可视化编辑器Hue的安装[05:30]
2-2在hue上编辑oozie的第一个例子[08:59]
2-3oozie ssh action的使用[05:17]
2-4oozie shell action的使用[04:47]
2-5oozie email action的使用[03:44]
2-6oozie fs action的使用[03:02]
2-7oozie pig action的使用[06:04]
2-8oozie java action的使用[03:30]
2-9oozie mapreduce action的使用[06:44]
2-10oozie spark action的使用[07:27]
2-11oozie hive action的使用[10:22]
2-12oozie hiveserver2 action的使[02:43]
2-13oozie sqoop action的使用[08:38]
2-14oozie控制action的使用[14:03]
2-15oozie subworkflow action的使[05:10]
2-16oozie 自定义action的使用[10:13]
2-17oozie transition的使用[03:49]
2-18oozie全局参数和局部参数[08:31]
第3章 cdh6 oozie高级教程
1小时8分钟10节
3-1oozie的工作原理[08:46]
3-2oozie job和action的生命周期[04:21]
3-3oozie定时器coordinator和bundle[05:41]
3-4oozie coordinator的数据依赖[14:13]
3-5oozie的EL表达式[05:23]
3-6oozie的重试机制[05:00]
3-7oozie的三种交互接口[05:19]
3-8oozie action的传参机制[11:00]
3-9oozie的sla通知机制[04:46]
3-10Hue oozie和原生oozie的应用场景[03:54]
第4章 cdh6 oozie实战
45分钟6节
4-1一个在大数据离线数仓中的oozie经典案例[02:14]
4-2经典案例-sqoop import mysql表到数[14:20]
4-3经典案例-hive etl清洗[06:30]
4-4经典案例- sqoop export数仓表到mysq[03:24]
4-5经典案例- zeppelin可视化展示回流表[04:56]
4-6经典案例改写为原生oozie项目[13:58]
EL常量
常量表示形式 含义说明
${coord:minutes(int n)} 返回日期时间:从一开始,周期执行n分钟
${coord:hours(int n)} 返回日期时间:从一开始,周期执行n * 60分钟
${coord:days(int n)} 返回日期时间:从一开始,周期执行n * 24 * 60分钟
${coord:months(int n)} 返回日期时间:从一开始,周期执行n * M * 24 * 60分钟(M表示一个月的天数)
${coord:endOfDays(int n)} 返回日期时间:从当天的最晚时间(即下一天)开始,周期执行n * 24 * 60分钟
${coord:endOfMonths(1)} 返回日期时间:从当月的最晚时间开始(即下个月初),周期执行n * 24 * 60分钟
${coord:current(int n)} 返回日期时间:从一个Coordinator动作(Action)创建时开始计算,第n个dataset实例执行时间
${coord:dataIn(String name)} 在输入事件(input-events)中,解析dataset实例包含的所有的URI
${coord:dataOut(String name)} 在输出事件(output-events)中,解析dataset实例包含的所有的URI
${coord:offset(int n, String timeUnit)} 表示时间偏移,如果一个Coordinator动作创建时间为T,n为正数表示向时刻T之后偏移,n为负数向向时刻T之前偏移,timeUnit表示时间单位(选项有MINUTE、HOUR、DAY、MONTH、YEAR)
${coord:hoursInDay(int n)} 指定的第n天的小时数,n>0表示向后数第n天的小时数,n=0表示当天小时数,n<0表示向前数第n天的小时数
${coord:daysInMonth(int n)} 指定的第n个月的天数,n>0表示向后数第n个月的天数,n=0表示当月的天数,n<0表示向前数第n个月的天数
${coord:tzOffset()} ataset对应的时区与Coordinator Job的时区所差的分钟数
${coord:latest(int n)} 最近以来,当前可以用的第n个dataset实例
${coord:future(int n, int limit)} 当前时间之后的dataset实例,n>=0,当n=0时表示立即可用的dataset实例,limit表示dataset实例的个数
c
o
o
r
d
:
n
o
m
i
n
a
l
T
i
m
e
(
)
n
o
m
i
n
a
l
时
间
等
于
C
o
o
r
d
i
n
a
t
o
r
J
o
b
启
动
时
间
,
加
上
多
个
C
o
o
r
d
i
n
a
t
o
r
J
o
b
的
频
率
所
得
到
的
日
期
时
间
。
例
如
:
s
t
a
r
t
=
”
2009
−
01
−
01
T
24
:
00
Z
”
,
e
n
d
=
”
2009
−
12
−
31
T
24
:
00
Z
”
,
f
r
e
q
u
e
n
c
y
=
”
{coord:nominalTime()} nominal时间等于Coordinator Job启动时间,加上多个Coordinator Job的频率所得到的日期时间。例如:start=”2009-01-01T24:00Z”,end=”2009-12-31T24:00Z”,frequency=”
coord:nominalTime()nominal时间等于CoordinatorJob启动时间,加上多个CoordinatorJob的频率所得到的日期时间。例如:start=”2009−01−01T24:00Z”,end=”2009−12−31T24:00Z”,frequency=”{coord:days(1)}”,frequency=”${coord:days(1)},则nominal时间为:2009-01-02T00:00Z、2009-01-03T00:00Z、2009-01-04T00:00Z、…、2010-01-01T00:00Z
c
o
o
r
d
:
a
c
t
u
a
l
T
i
m
e
(
)
C
o
o
r
d
i
n
a
t
o
r
动
作
的
实
际
创
建
时
间
。
例
如
:
s
t
a
r
t
=
”
2011
−
05
−
01
T
24
:
00
Z
”
,
e
n
d
=
”
2011
−
12
−
31
T
24
:
00
Z
”
,
f
r
e
q
u
e
n
c
y
=
”
{coord:actualTime()} Coordinator动作的实际创建时间。例如:start=”2011-05-01T24:00Z”,end=”2011-12-31T24:00Z”,frequency=”
coord:actualTime()Coordinator动作的实际创建时间。例如:start=”2011−05−01T24:00Z”,end=”2011−12−31T24:00Z”,frequency=”{coord:days(1)}”,则实际时间为:2011-05-01,2011-05-02,2011-05-03,…,2011-12-31
${coord:user()} 启动当前Coordinator Job的用户名称
${coord:dateOffset(String baseDate, int instance, String timeUnit)} 计算新的日期时间的公式:newDate = baseDate + instance * timeUnit,如:baseDate=’2009-01-01T00:00Z’,instance=’2′,timeUnit=’MONTH’,则计算得到的新的日期时间为’2009-03-01T00:00Z’。
${coord:formatTime(String timeStamp, String format)} 格式化时间字符串,format指定模式
常量表示形式 含义说明
${coord:minutes(int n)} 返回日期时间:从一开始,周期执行n分钟
${coord:hours(int n)} 返回日期时间:从一开始,周期执行n * 60分钟
${coord:days(int n)} 返回日期时间:从一开始,周期执行n * 24 * 60分钟
${coord:months(int n)} 返回日期时间:从一开始,周期执行n * M * 24 * 60分钟(M表示一个月的天数)
${coord:endOfDays(int n)} 返回日期时间:从当天的最晚时间(即下一天)开始,周期执行n * 24 * 60分钟
${coord:endOfMonths(1)} 返回日期时间:从当月的最晚时间开始(即下个月初),周期执行n * 24 * 60分钟
${coord:current(int n)} 返回日期时间:从一个Coordinator动作(Action)创建时开始计算,第n个dataset实例执行时间
${coord:dataIn(String name)} 在输入事件(input-events)中,解析dataset实例包含的所有的URI
${coord:dataOut(String name)} 在输出事件(output-events)中,解析dataset实例包含的所有的URI
${coord:offset(int n, String timeUnit)} 表示时间偏移,如果一个Coordinator动作创建时间为T,n为正数表示向时刻T之后偏移,n为负数向向时刻T之前偏移,timeUnit表示时间单位(选项有MINUTE、HOUR、DAY、MONTH、YEAR)
${coord:hoursInDay(int n)} 指定的第n天的小时数,n>0表示向后数第n天的小时数,n=0表示当天小时数,n<0表示向前数第n天的小时数
${coord:daysInMonth(int n)} 指定的第n个月的天数,n>0表示向后数第n个月的天数,n=0表示当月的天数,n<0表示向前数第n个月的天数
${coord:tzOffset()} ataset对应的时区与Coordinator Job的时区所差的分钟数
${coord:latest(int n)} 最近以来,当前可以用的第n个dataset实例
${coord:future(int n, int limit)} 当前时间之后的dataset实例,n>=0,当n=0时表示立即可用的dataset实例,limit表示dataset实例的个数
c
o
o
r
d
:
n
o
m
i
n
a
l
T
i
m
e
(
)
n
o
m
i
n
a
l
时
间
等
于
C
o
o
r
d
i
n
a
t
o
r
J
o
b
启
动
时
间
,
加
上
多
个
C
o
o
r
d
i
n
a
t
o
r
J
o
b
的
频
率
所
得
到
的
日
期
时
间
。
例
如
:
s
t
a
r
t
=
”
2009
−
01
−
01
T
24
:
00
Z
”
,
e
n
d
=
”
2009
−
12
−
31
T
24
:
00
Z
”
,
f
r
e
q
u
e
n
c
y
=
”
{coord:nominalTime()} nominal时间等于Coordinator Job启动时间,加上多个Coordinator Job的频率所得到的日期时间。例如:start=”2009-01-01T24:00Z”,end=”2009-12-31T24:00Z”,frequency=”
coord:nominalTime()nominal时间等于CoordinatorJob启动时间,加上多个CoordinatorJob的频率所得到的日期时间。例如:start=”2009−01−01T24:00Z”,end=”2009−12−31T24:00Z”,frequency=”{coord:days(1)}”,frequency=”${coord:days(1)},则nominal时间为:2009-01-02T00:00Z、2009-01-03T00:00Z、2009-01-04T00:00Z、…、2010-01-01T00:00Z
c
o
o
r
d
:
a
c
t
u
a
l
T
i
m
e
(
)
C
o
o
r
d
i
n
a
t
o
r
动
作
的
实
际
创
建
时
间
。
例
如
:
s
t
a
r
t
=
”
2011
−
05
−
01
T
24
:
00
Z
”
,
e
n
d
=
”
2011
−
12
−
31
T
24
:
00
Z
”
,
f
r
e
q
u
e
n
c
y
=
”
{coord:actualTime()} Coordinator动作的实际创建时间。例如:start=”2011-05-01T24:00Z”,end=”2011-12-31T24:00Z”,frequency=”
coord:actualTime()Coordinator动作的实际创建时间。例如:start=”2011−05−01T24:00Z”,end=”2011−12−31T24:00Z”,frequency=”{coord:days(1)}”,则实际时间为:2011-05-01,2011-05-02,2011-05-03,…,2011-12-31
${coord:user()} 启动当前Coordinator Job的用户名称
${coord:dateOffset(String baseDate, int instance, String timeUnit)} 计算新的日期时间的公式:newDate = baseDate + instance * timeUnit,如:baseDate=’2009-01-01T00:00Z’,instance=’2′,timeUnit=’MONTH’,则计算得到的新的日期时间为’2009-03-01T00:00Z’。
${coord:formatTime(String timeStamp, String format)} 格式化时间字符串,format指定模式
例如,昨天的日期就可以写为昨天日期 ${coord:formatTime(coord:dateOffset(coord:nominalTime(), -1, ‘DAY’), ‘yyyyMMdd’)}
问题与解决办法
oozie会存在时区问题,默认会与中国时间会相差8个小时,这就需要oozie的时区,我使用的是cdh,所以设置很方便,进入cm的管理界面,进入oozie的设置,添加配置:
oozie.processing.timezoneGMT+0800
命令操作
oozie4.3.0调用shell
编写workflow.xml
<!--Workflow-DEF-NAME-->
<workflow-app xmlns='uri:oozie:workflow:0.3' name='shell-wf'>
<!--shell1: node-name -->
<start to='shell1' />
<action name='shell1'>
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<!--${EXEC}是shell脚本命令,例如;mkdir-->
<exec>${EXEC}</exec>
<!--argument标签中是exec中的参数值-->
<argument>A</argument>
<argument>B</argument>
<!--file标签里面放的hdfs上写好的shell脚本,例如:test.sh -->
<file>${EXEC}#${EXEC}</file> <!--Copy the executable to compute node's current working directory -->
</shell>
<!--end和fail都是node-name -->
<ok to="end" />
<error to="fail" />
</action>
<!--fork与join成对使用的举例start-->
<fork name="[FORK-NODE-NAME]">
<path start="[NODE-NAME]" />
...
<path start="[NODE-NAME]" />
</fork>
<join name="[JOIN-NODE-NAME]" to="[NODE-NAME]" />
<!--fork与join成对使用的举例end-->
<kill name="fail">
<message>Script failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name='end' />
</workflow-app>
编写job.properties
# 这里写的是workflow.xml和job.properties在hdfs的哪个目录下
oozie.wf.application.path=hdfs://localhost:8020/user/kamrul/workflows/script#Execute is expected to be in the Workflow directory.
#Shell Script to run
EXEC=script.sh
#CPP executable. Executable should be binary compatible to the compute node OS.
#EXEC=hello
#Perl script
#EXEC=script.pl
#jobTracker实际上就是resourceManager的地址
jobTracker=localhost:8021
nameNode=hdfs://localhost:8020
queueName=default
提交job
# 注意这个job.properties是本地的
bin/oozie job -oozie http://hadoop102:11000/oozie -config oozie-apps/shell/job.properties -run
hue
Oozie是什么?
Oozie是一种Java Web应用程序,它运行在Java servlet容器——即Tomcat——中,并使用数据库来存储以下内容:
工作流定义
当前运行的工作流实例,包括实例的状态和变量
Hue是什么?
Hue是一个可快速开发和调试Hadoop生态系统各种应用的一个基于浏览器的图形化用户接口。
Hue能干什么?
1,访问HDFS和文件浏览
2,通过web调试和开发hive以及数据结果展示
3,查询solr和结果展示,报表生成
4,通过web调试和开发impala交互式SQL Query
5,spark调试和开发
6,Pig开发和调试
7,oozie任务的开发,监控,和工作流协调调度
8,Hbase数据查询和修改,数据展示
9,Hive的元数据(metastore)查询
10,MapReduce任务进度查看,日志追踪
11,创建和提交MapReduce,Streaming,Java job任务
12,Sqoop2的开发和调试
13,Zookeeper的浏览和编辑
14,数据库(MySQL,PostGres,SQlite,Oracle)的查询和展示
workflow
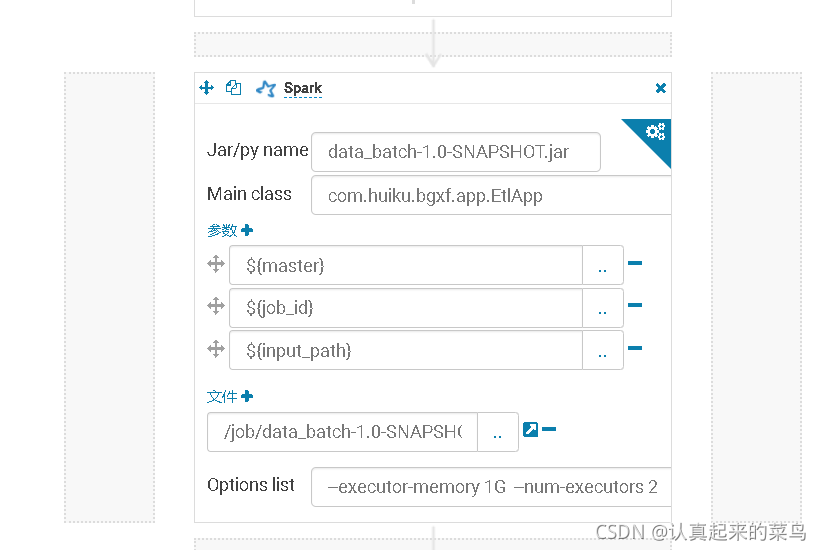
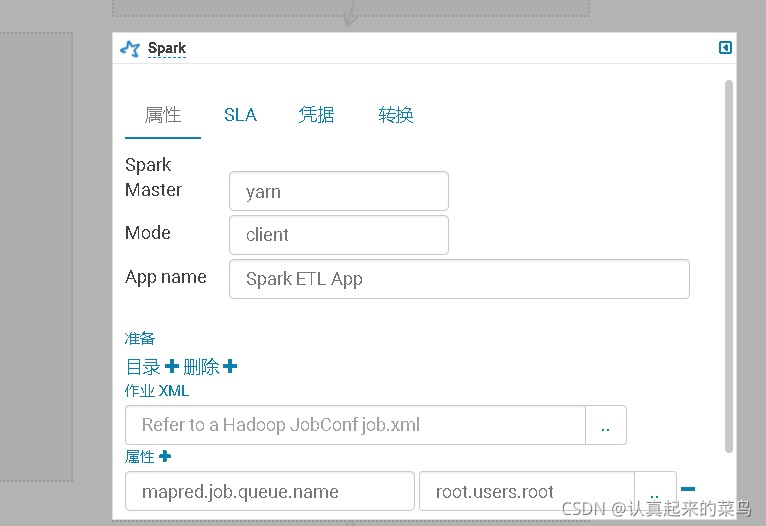
定时任务

















 1602
1602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











