







周志华《机器学习》第二章的2.3.2节中,我不理解P-R曲线的步骤,特别是“按此顺序逐个把样本作为正例进行预测”这句话。因此,上网查到了相关解答,内容如下。
作者:Yellow俊
链接:https://www.zhihu.com/question/348073311/answer/837781413
来源:知乎
首先,我们可根据学习器的 预测结果 对样本进行 排序,排在 最前面 是学习器认为 “最可能” 是正例的样本,排在 最后的 则是学习器认为 “最不可能” 是正例的样本。
按照要求排完序啰
然后,按此顺序 逐个把样本 作为 正例 进行 预测,我们把第一个样本作为正例:
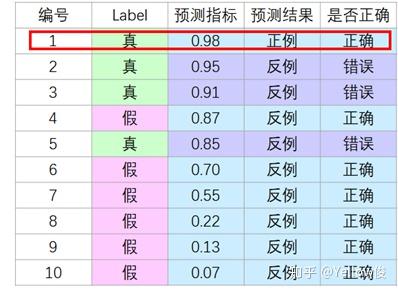
第一个为正例:预测指标 > 0.95
此时的混淆矩阵为:
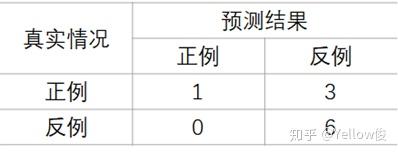
第一个为正例:预测指标 > 0.95
此时的 查准率 P 与 查全率 R 分别为:

不难看出,当我们假设 第一个为正例 的时候,预测指标 > 0.95,此时的 查准率很高,但 查全率很低。
接着,我们把前三个当作正例:
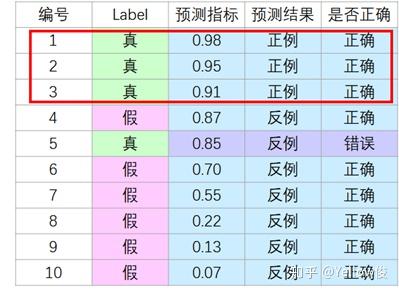
前三个为正例:预测指标 > 0.90
此时的混淆矩阵为:
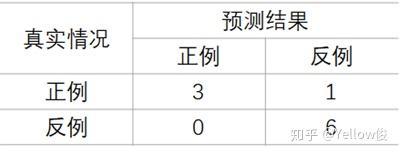
前三个为正例:预测指标 > 0.90
此时的 查准率 P 与 查全率 R 分别为:
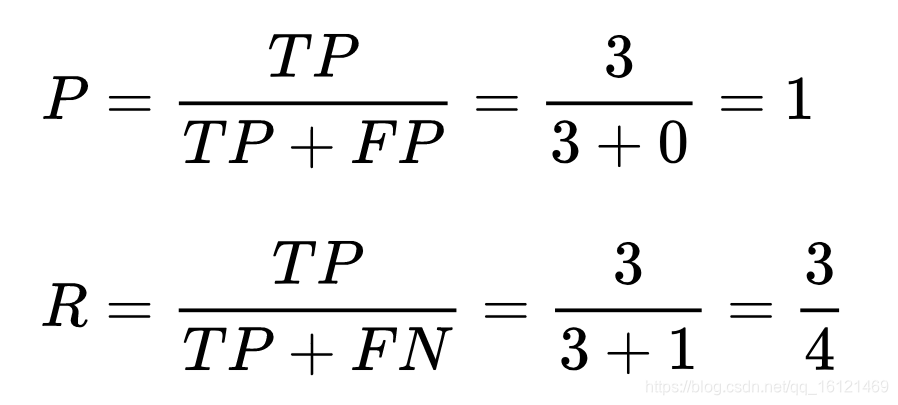
显然,当我们假设 前三个为正例 的时候,预测指标 > 0.90,此时的 查准率很高,而且 查全率也有提升。
我们 按顺序逐个把样本 作为 正例 进行 预测,就可以计算出当前的 查全率、查准率。
通过上述过程我们就可以得到 查准率 - 查全率 的 关系曲线:
- 对于 一个 学习器来说,我们可以 选择最佳参数
- 对于 多个 学习器来说,我们可以 比较学习器的优劣















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









