









纠结了非常久,最终还是决定开始更新大数据集群类的文章了。
操作前需要准备:
1.虚拟机镜像:CentOS-6.5-x86_64-bin-DVD1.iso
链接:https://pan.baidu.com/s/1O9a-6Sn7riGWG3mVQssTGg
提取码:rud1
2.jdk:jdk-8u144-linux-x64.tar.gz
链接:https://pan.baidu.com/s/1TdaCDaT_qriDMjbYFyphPw
提取码:qulj
3.hadoop:hadoop-2.7.2.tar.gz
链接:https://pan.baidu.com/s/1Wt0mAUHKJDSYTUM5-u6CYw
提取码:oofe
或者官网:
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
上述的如果百度云下载的慢的话,可以去各大开源论坛或者官网下载
博主使用的工具为Xshell,非常方便的一个软件,感兴趣的话可以动动自己的小手,去官网下载
一. 安装Linux
1. 安装Linux(内存2G-4G,硬盘50G)
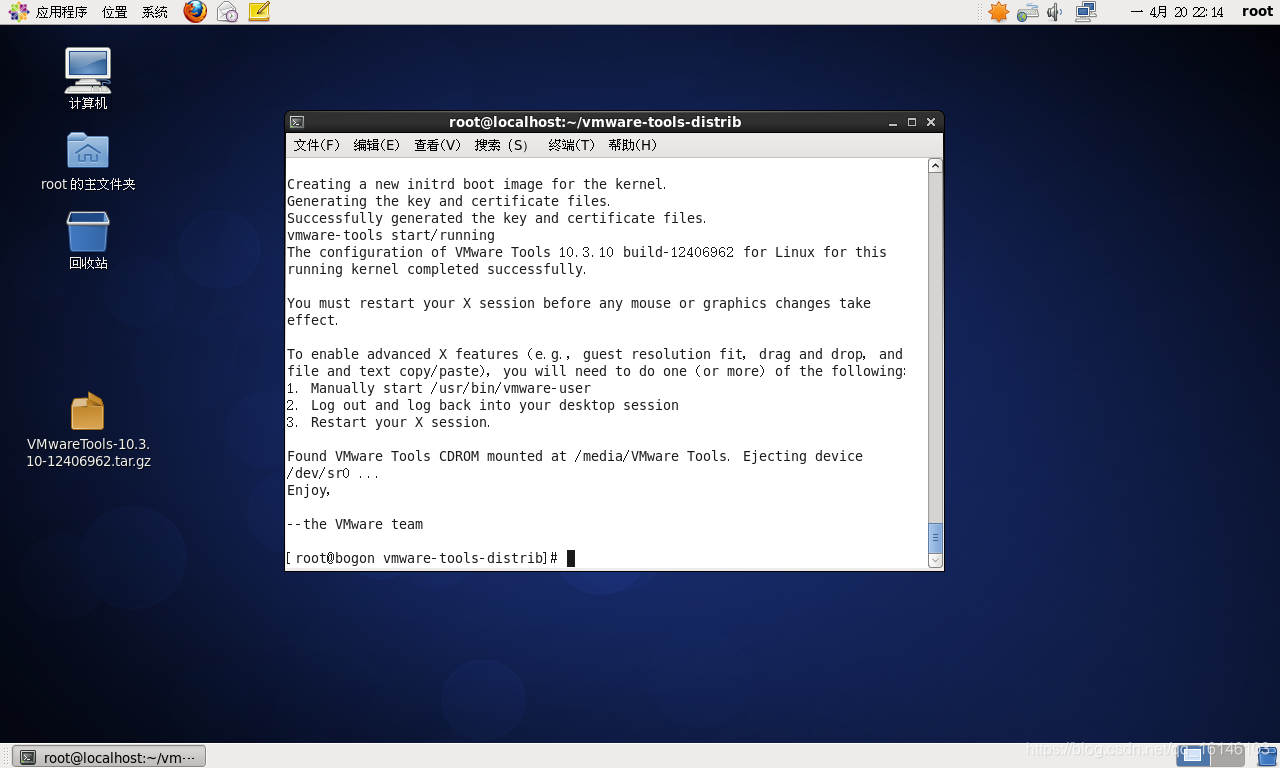
2. 安装VMTools(可不装,不过装了方便)
如果不会安装可以参考:
https://jingyan.baidu.com/article/597a0643356fdc312b5243f6.html
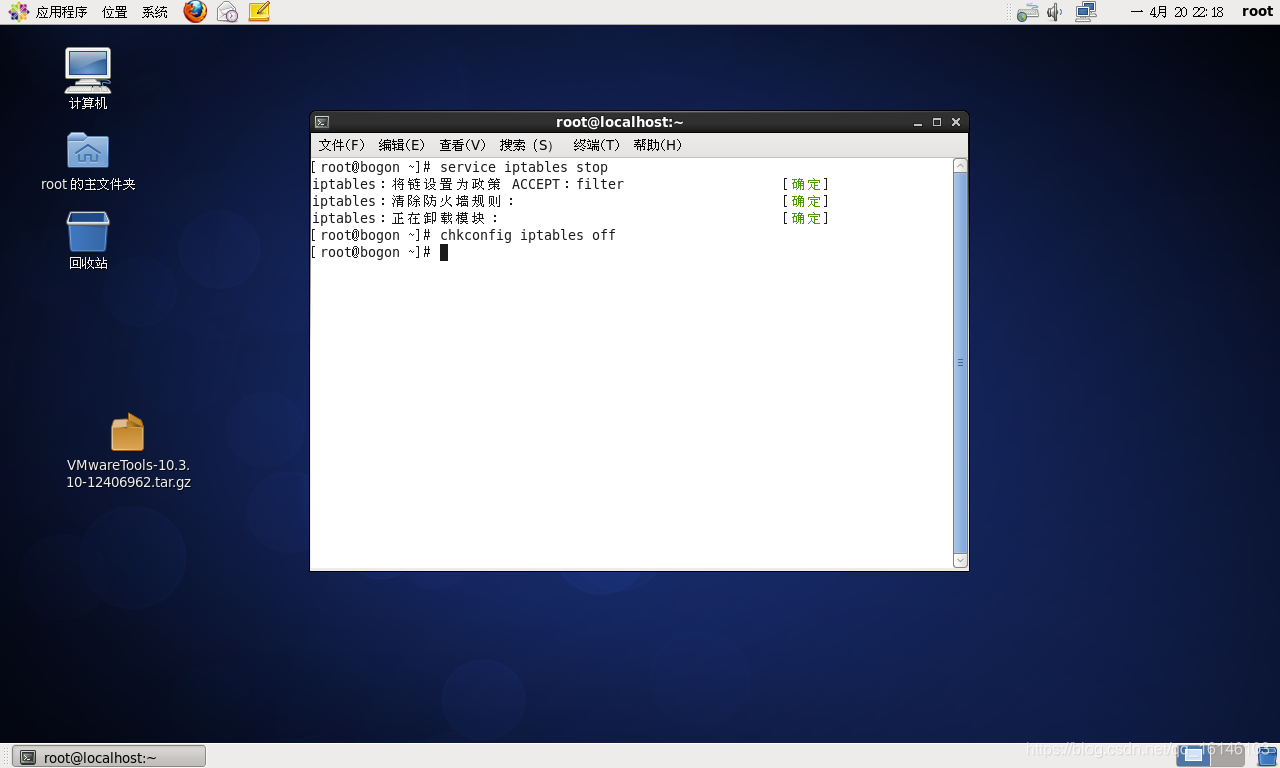
3. 关闭防火墙(重要)
关闭防火墙
sudo service iptables stop
sudo chkconfig iptables off
4. 设置静态IP,改主机名
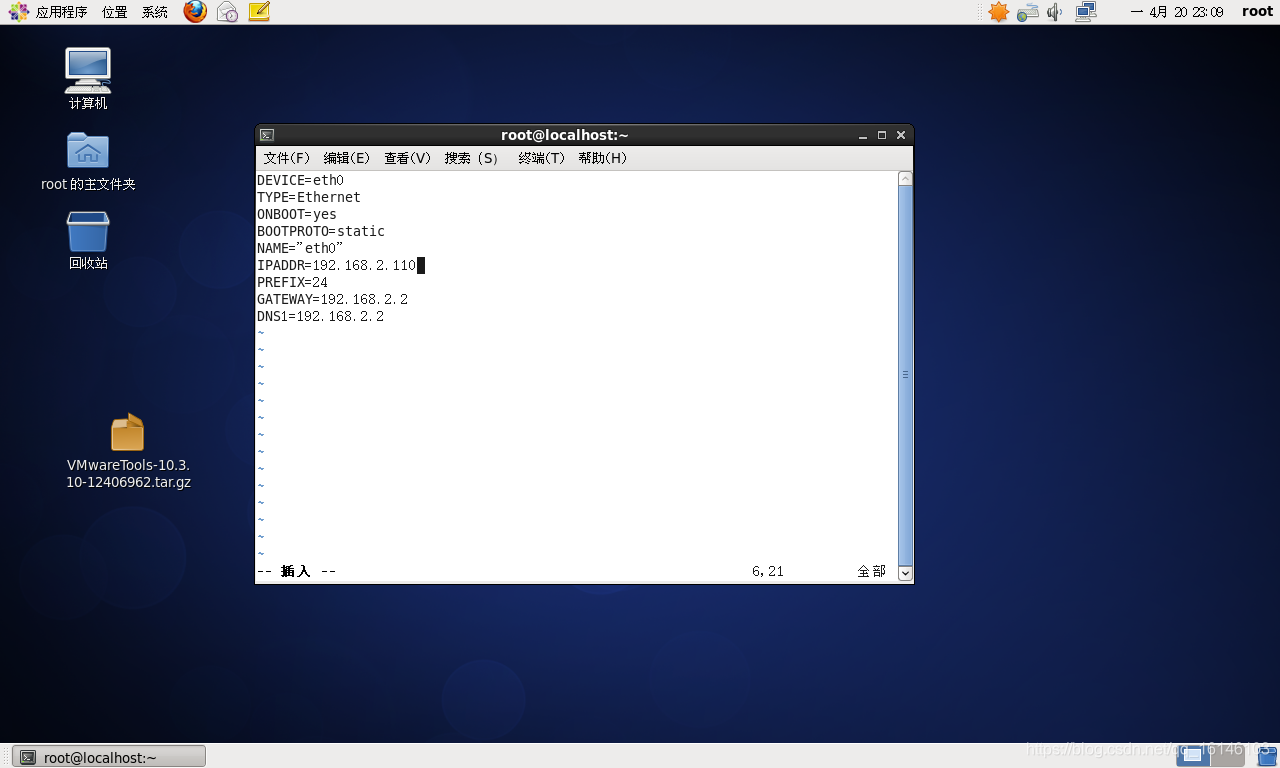
- 1. 修改IP
vim /etc/sysconfig/network-scripts/ifcfg-eth0
# 修改
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="eth0"
IPADDR=192.168.2.101 # 要看自己的网段
PREFIX=24
GATEWAY=192.168.2.2
DNS1=192.168.2.2
- 2. 改主机名
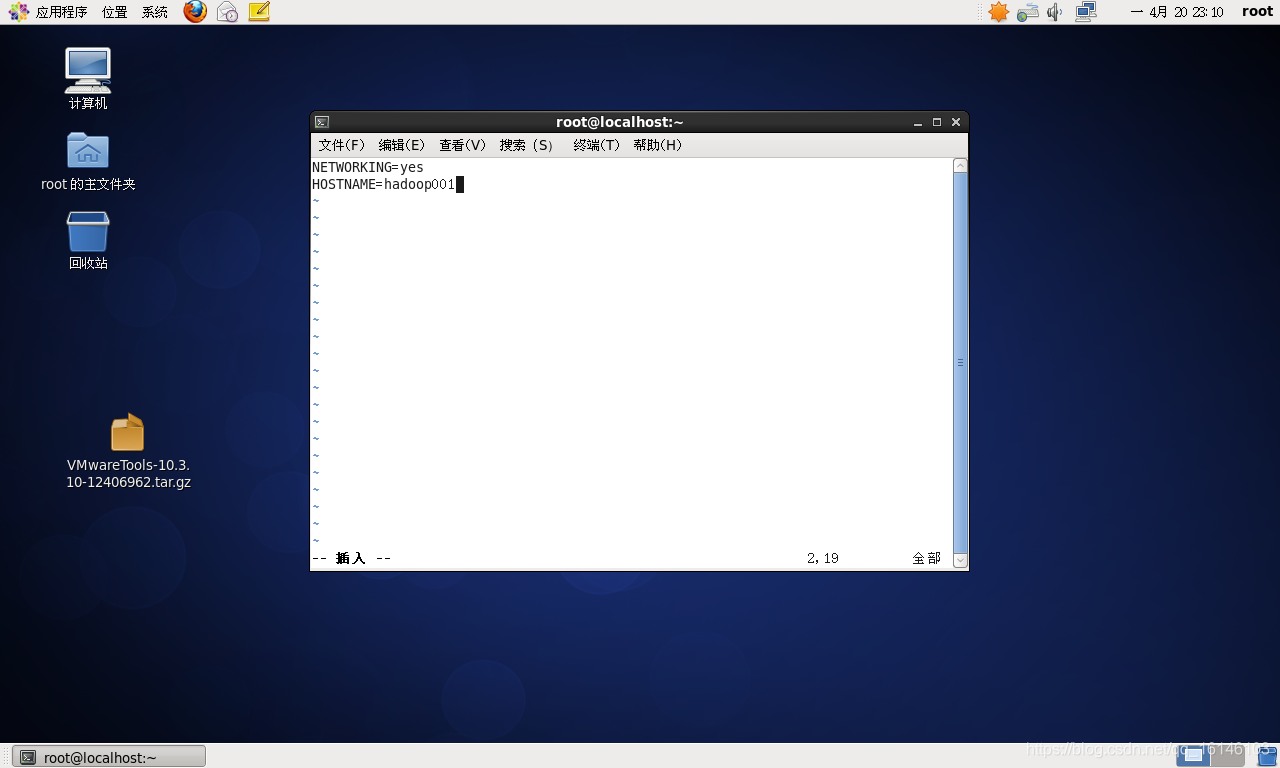
vim /etc/sysconfig/network
改HOSTNAME=那一行
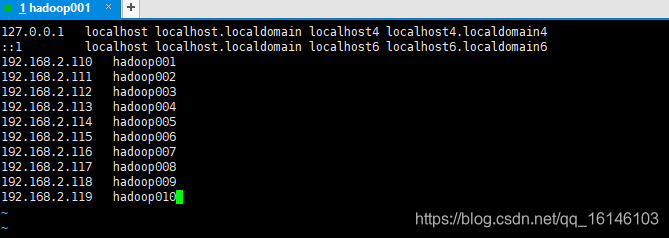
5. 配置hosts文件
vim /etc/hosts
=============================
192.168.2.110 hadoop001
192.168.2.111 hadoop002
192.168.2.112 hadoop003
192.168.2.113 hadoop004
192.168.2.114 hadoop005
192.168.2.115 hadoop006
192.168.2.116 hadoop007
192.168.2.117 hadoop008
192.168.2.118 hadoop009
192.168.2.119 hadoop010
=============================
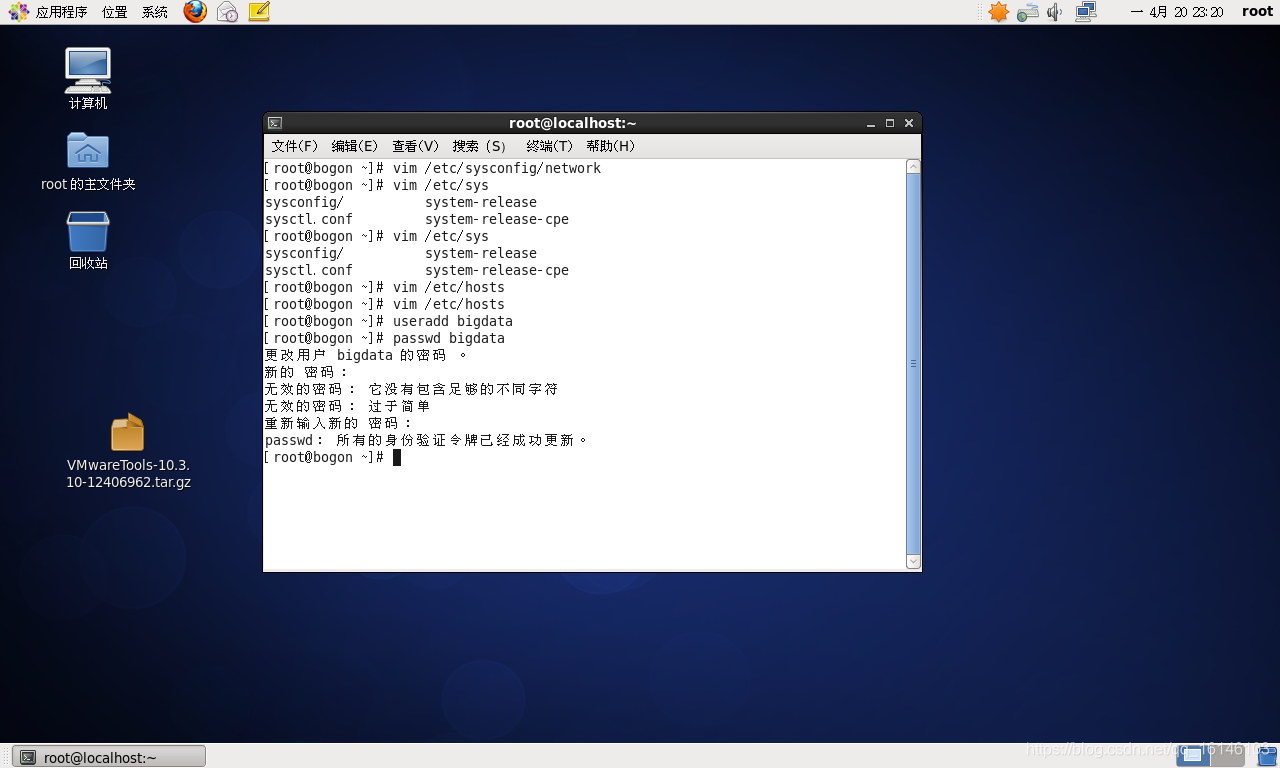
6. 创建用户名
创建一个一般用户bigdata,给他配置密码
useradd bigdata
passwd bigdata
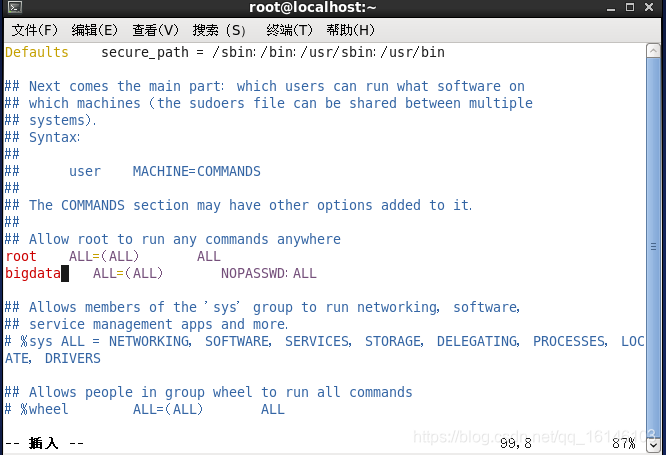
7. 配置用户为sudoers
vim /etc/sudoers
在root ALL=(ALL) ALL
添加bigdata ALL=(ALL) NOPASSWD:ALL
保存时wq!强制保存
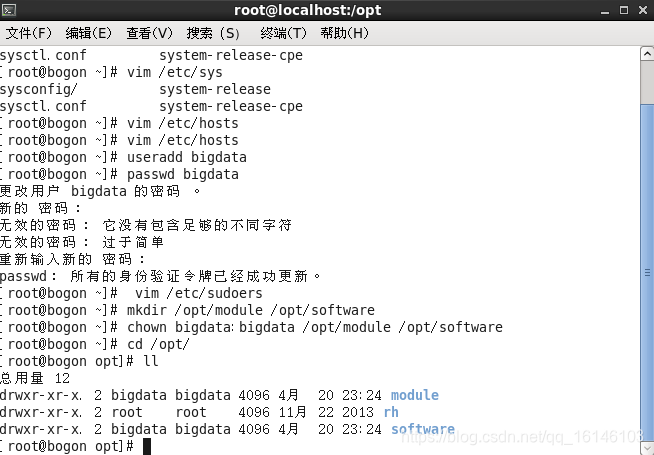
8. 创建文件夹,并赋权限给新建的用户名
mkdir /opt/module /opt/software
chown bigdata:bigdata /opt/module /opt/software
如果只是想搭建伪分布式的话,到这里就可以了,不过下面要进行的操作都要登录到刚刚创建的bigdata,来进行操作。
关于分布式的那部分,会在搭建集群时,详细进行说明;
下面操作基本上都会使用Xshell这个软件进行,感兴趣的可以下载使用。
二. 安装JDK
在开始安装前,需要检查一下现有的JDK
# 查询是否安装Java软件:
[root@hadoop001 ~]# rpm -qa | grep java
java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
tzdata-java-2013g-1.el6.noarch
java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
# 如果安装的版本低于1.7,卸载该JDK:
[bigdata@hadoop001 jdk1.8.0_144]$ rpm -qa | grep java | xargs sudo rpm -e --nodeps
[root@hadoop001 ~]# rpm -qa | grep java
1. 上传文件到指定文件夹内
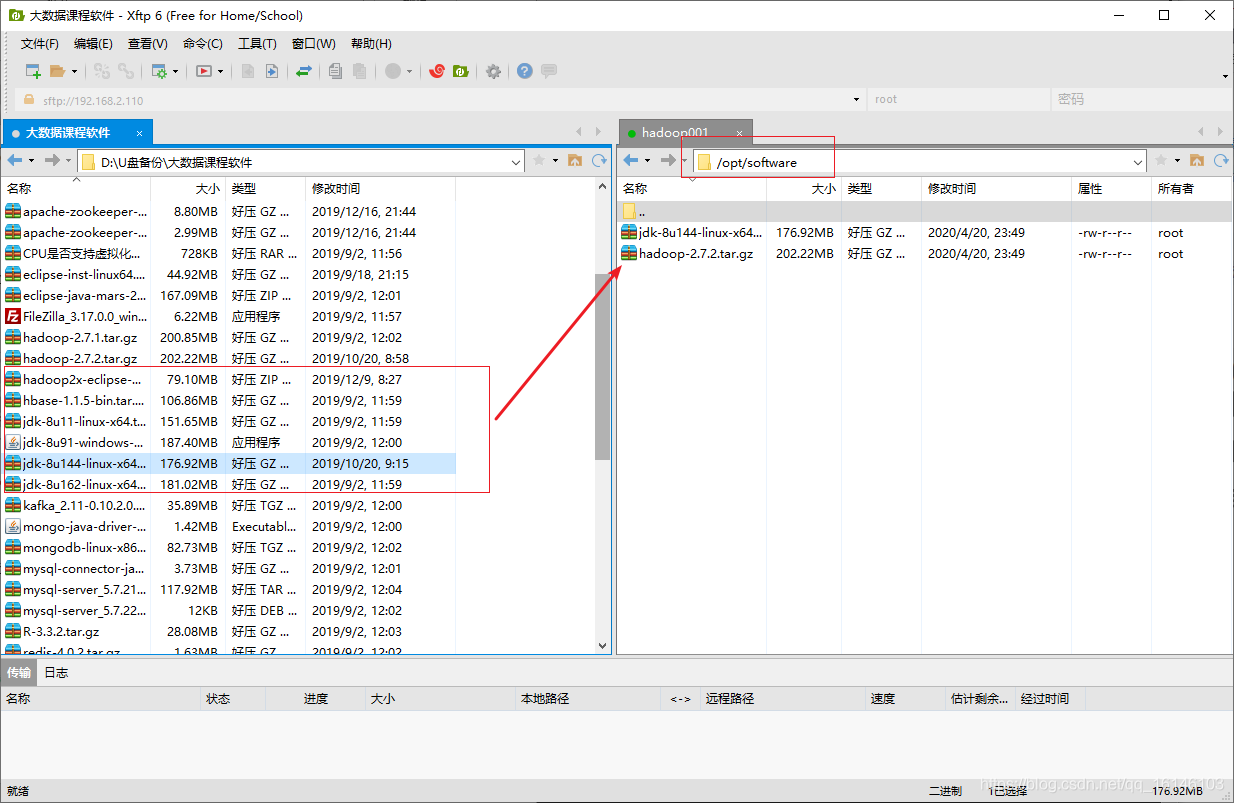
2. 在Linux系统下的opt目录中查看软件包是否导入成功
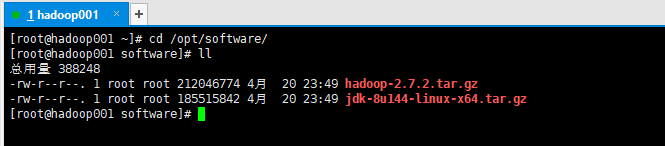
3. 解压JDK到/opt/module目录下
[bigdata@hadoop101 software]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
[bigdata@hadoop001 software]$ cd /opt/module/
[bigdata@hadoop001 module]$ ll
总用量 4
drwxr-xr-x. 8 bigdata bigdata 4096 7月 22 2017 jdk1.8.0_144
4. 配置JDK环境变量
- 1. 先获取JDK路径
[bigdata@hadoop001 jdk1.8.0_144]$ pwd
/opt/module/jdk1.8.0_144
- 2. 打开/etc/profile文件
[bigdata@hadoop001 jdk1.8.0_144]$ sudo vim /etc/profile
#在profile文件末尾添加JDK路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
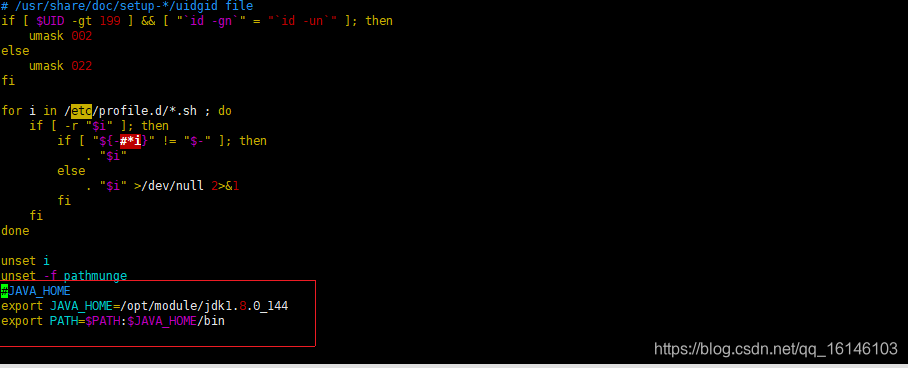
- 3. 保存后退出 :wq
- 4. 让修改后的文件生效
[bigdata@hadoop001 jdk1.8.0_144]$ source /etc/profile
- 5. 测试JDK是否安装成功
[bigdata@hadoop001 jdk1.8.0_144]$ java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
三. 安装Hadoop
1. 进入到Hadoop安装包路径下
2. 解压安装文件到/opt/module下面
[bigdata@hadoop001 jdk1.8.0_144]$ cd /opt/software/
[bigdata@hadoop001 software]$ tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
3. 查看是否解压成功
[bigdata@hadoop001 software]$ cd /opt/module/
[bigdata@hadoop001 module]$ ll
总用量 8
drwxr-xr-x. 9 bigdata bigdata 4096 1月 26 2016 hadoop-2.7.2
drwxr-xr-x. 8 bigdata bigdata 4096 7月 22 2017 jdk1.8.0_144
4. 将Hadoop添加到环境变量
- 1. 获取Hadoop安装路径
[bigdata@hadoop001 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.7.2
- 2. 打开/etc/profile文件
[bigdata@hadoop001 hadoop-2.7.2]$ sudo vi /etc/profile
在profile文件末尾添加JDK路径:
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
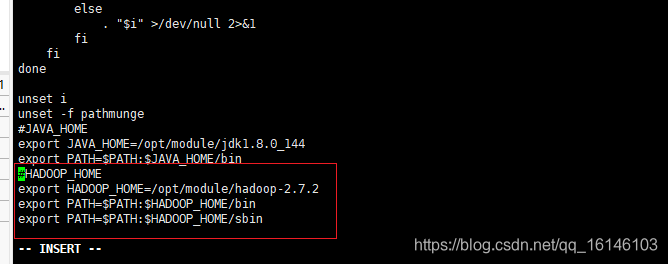
- 3. 保存并退出 :wq!
- 4. 让修改后的文件生效
[bigdata@hadoop001 hadoop-2.7.2]$ source /etc/profile
5. 测试是否安装成功
[bigdata@hadoop001 hadoop-2.7.2]$ hadoop version

四. Hadoop目录结构
查看Hadoop目录结构
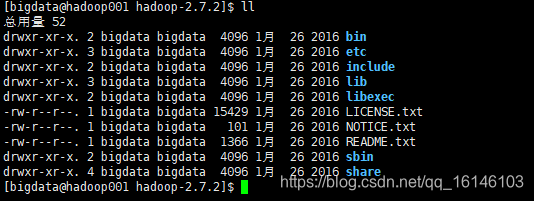
- 重要的目录如下:
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
各位路过的朋友,如果觉得可以学到些什么的话,点个赞再走吧,欢迎各位路过的大佬评论,指正错误,也欢迎有问题的小伙伴评论留言,私信。每个小伙伴的关注都是本人更新博客的动力!!!















 3760
3760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









