







HBase中的RowKey主要有以下的作用:
- 读写数据时通过Row Key找到对应的Region
- MemStore中的数据按RowKey字典顺序排序
- HFile中的数据按RowKey字典顺序排序
底层的HFile最终是按照RowKey进行切分的,所以我们的设计原则是结合业务的特点,并考虑高频查询,尽可能的将数据打散到整个集群中。
RowKey的设计-Salting
Salting的原理是将固定长度的随机数放在行键的起始处
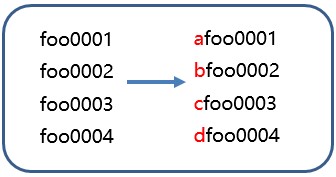
缺点:由于前缀是随机生成的,因而如果想要按照字典顺序找到这些行,则需要做更多的工作。从这个角度上看,Salting增加了写操作的吞吐量,却也增大了读的开销。
RowKey的设计-Hashing
Hashing原理将RowKey进行hash计算,然后取hash的部分字符串和原来的RowKey进行拼接。
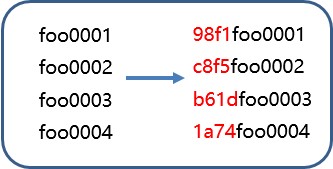
优缺点:可以一定程度打散整个数据集,但是不利于Scan,由于不同数据的hash值可能一样,实际应用一般使用Md5计算,然后截取前几位的字符串。
RowKey的设计-Reversing
Reversing的原理是反转一段固定长度或者全部的键

优缺点:有效地打乱了行键,但是却牺牲了行排序的属性。
HBase的生态主要包括:
- Phoenix:主要提供使用 SQL 的方式来查询 HBase 里面的数据。一般能够在毫秒级别返回,比较适合 OLTP 场景。
- Spark:我们可以使用 Spark 进行 OLAP 分析;也可以使用 Spark SQL 来满足比较复杂的 SQL 查询场景;使用 Spark Streaming 来进行实时流分析。
- Solr:原生的 HBase 只提供了 Rowkey 单主键,如果我们需要对 Rowkey 之外的列进行查找,这时候就会有问题。幸好我们可以使用 Solr 来建立二级索引/全文索引充分满足我们的查询需求。
- HGraphDB:HGraphDB是分布式图数据库。依托图关联技术,帮助金融机构有效识别隐藏在网络中的黑色信息,在团伙欺诈、黑中介识别等。
- GeoMesa:目前基于NoSQL数据库的时空数据引擎中功能最丰富、社区贡献人数最多的开源系统。
- OpenTSDB:基于HBase的分布式的,可伸缩的时间序列数据库。适合做监控系统;譬如收集大规模集群(包括网络设备、操作系统、应用程序)的监控数据并进行存储,查询。
参考出处微信公众号:过往记忆大数据
你的鼓励是我分享技术最大的动力!如有错误之处,请指正,不胜感激。















 128
128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









