







引用指的是引用类型。Java引入引用的目的在于JVM能更加柔性地管理内存,比如对引用对象来说,当内存足够,垃圾回收器不去回收这些内存。因为引用的特殊性,引用对象的使用和回收与一般对象的使用和回收并不相同。本章将介绍:JDK如何实现引用,JVM如何发现引用对象、处理引用,最后分析了引用相关的日志并介绍了如何调优。G1并没有对引用做额外的处理,所以本章介绍的内容也适用于其他的垃圾回收器。
引用概述
我们这里所说的引用主要指:软引用、弱引用和虚引用。另外值得一提的是Java中的Finalize也是通过引用实现的,JDK定义了一种新的引用类型FinalReference,这个类型的处理和其他三种引用都稍有不同。另外在非公开的JDK包中还有一个sun.misc.cleaner,通常用它来释放非堆内存资源,它在JVM内部也是用一个CleanerReference实现。要理解引用处理需要先从Java代码入手。先看看java.lang.ref包里面的部分代码,这一部分代码不在Hotspot中,通常可以在JDK安装目录下找到它,其代码如下所示:
jdk/src/share/classes/java/lang/ref/Reference.java
public abstract class Reference<T> {
// Reference指向的对象
private T referent; /* Treated specially by GC */
/*Reference所指向的队列,如果我们创建引用对象的时候没有指定队列,那么队列就是ReferenceQueue.NULL,这是一个空队列,这个时候所有插入队列的对象都被丢弃。这个字段是引用的独特之处。这个队列一般是我们自定义,然后可以自己处理。典型的例子就是weakhashmap和FinalReference,他们都有自己的代码处理这个队列从而达到自己的目的。*/
volatile ReferenceQueue< super T> queue;
// next指针是用于形成链表,具体也是在JVM中使用。
Reference next;
// 这个字段是私有,在这里明确注释提到它在JVM中使用。它的目的是发现可收回的引用,
// 在后面的discover_reference里面可以看到更为详细的信息。
transient private Reference<T> discovered; /* used by VM */
// 这是一个静态变量,前面提到垃圾回收线程做的事情就是把discovered的元素
// 赋值到Pending中,并且把JVM中的Pending链表元素放到Reference类中Pending链表中
private static Reference<Object> pending = null;
}我们都知道JVM在启动之后有几个线程,其中之一是ReferenceHandler。这个线程做的主要工作就是把上面提到的pending里面的元素送到队列中。具体功能在tryHandlePending中,代码如下所示:
private static class ReferenceHandler extends Thread {
……
public void run() {
while (true) {
tryHandlePending(true);
}
}
}
……
static boolean tryHandlePending(boolean waitForNotify) {
Reference<Object> r;
Cleaner c;
try {
synchronized (lock) {
if (pending != null) {
r = pending;
c = r instanceof Cleaner (Cleaner) r : null;
pending = r.discovered;
r.discovered = null;
} else {
if (waitForNotify) {
lock.wait();
}
return waitForNotify;
}
}
} catch (OutOfMemoryError x) {
Thread.yield();
return true;
} catch (InterruptedException x) {
return true;
}
// Fast path for cleaners
if (c != null) {
c.clean();
return true;
}
ReferenceQueue< super Object> q = r.queue;
if (q != ReferenceQueue.NULL) q.enqueue(r);
return true;
}这里的discovered就是在垃圾回收中发现可回收的对象,什么是可回收的对象?指对象只能从引用这个根到达,没有任何强引用使用这个对象。所以说可回收的对象在被垃圾回收器发现后会被垃圾回收器放入pending这个队列,pending的意思就是等待被回收,如果我们自定义引用队列,那么引用线程ReferenceHandler把它加入到引用队列,供我们进一步处理。比如Finalizer里面就会激活一个线程,让这个线程把队列里面的对象拿出来,然后执行对象的finalize()方法。具体代码在runFinalization中,代码如下所示:
jdk/src/share/classes/java/lang/ref/Finalizer.java
static void runFinalization() {
if (!VM.isBooted()) {
return;
}
forkSecondaryFinalizer(new Runnable() {
private volatile boolean running;
public void run() {
if (running)
return;
final JavaLangAccess jla = SharedSecrets.getJavaLangAccess();
running = true;
for (;;) {
// 获取可回收对象
Finalizer f = (Finalizer)queue.poll();
if (f == null) break;
// 执行对象的finialize方法
f.runFinalizer(jla);
}
}
});在Reference.java这个类中描述了Reference的4个可能的状态:
- Active:对象是活跃的,这个活跃的意思是指GC可以通过可达性分析找到对象或者对象是软引用对象,且符合软引用活跃的规则。从活跃状态可以到Pending状态或者Inactive状态。新创建的对象总是活跃的。
- Pending:指对象进入上面的pengding_list,即将被送入引用队列。
- Enqueued:指引用线程ReferenceHandler把pending_list的对象加入引用队列。
- Inactive:对象不活跃,可以将对象回收了。
状态转换图如下图所示。
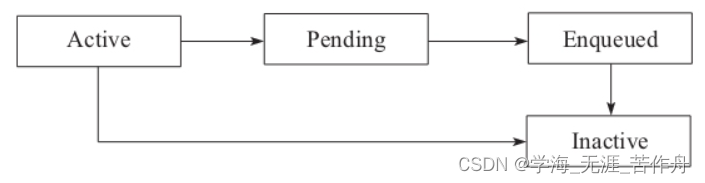
其中除了Pending到Enqueued状态是有引用线
程ReferenceHandler参与的,其他的变化都是GC线程完成的。另外值得一提的是,这些状态是虚拟状态,是为了便于大家理解引用是如何工作的,并没有一个字段来描述状态。所以在注释中我们看到对象所处状态的确定是通过queue这个字段和next这个字段来标记的。
可回收对象发现
在GC的标记阶段,从根对象出发对所有的对象进行标记,如果对象是引用对象,在JVM内部对应的类型为InstanceRefKlass,在对象遍历的时候会处理对象的每一个字段。在前面YGC的时候,我们提到copy_to_survior会执行obj->oop_iterate_backwards(&_scanner),在这里就会执行宏InstanceRefKlass_SPECIALIZED_OOP_ITERATE展开的代码,在这段代码里面有个关键的方法ReferenceProcessor::discover_reference,这个方法就是把从引用对象类型中的可回收对象放入链表中。
我们先看一下宏代码片段,代码如下所示:
hotspot/src/share/vm/oops/instanceRefKlass.cpp
#define InstanceRefKlass_SPECIALIZED_OOP_ITERATE(T, nv_suffix, contains) \
…… \
\
T* referent_addr = (T*)java_lang_ref_Reference::referent_addr(obj); \
T heap_oop = oopDesc::load_heap_oop(referent_addr); \
ReferenceProcessor* rp = closure->_ref_processor; \
if (!oopDesc::is_null(heap_oop)) { \
oop referent = oopDesc::decode_heap_oop_not_null(heap_oop); \
if (!referent->is_gc_marked() && (rp != NULL) && \
rp->discover_reference(obj, reference_type())) { \
return size; \
} else if (contains(referent_addr)) { \
/* treat referent as normal oop */ \
SpecializationStats::record_do_oop_call##nv_suffix(SpecializationStats::irk);\
closure->do_oop##nv_suffix(referent_addr); \
} \
}我们发现只有当引用里面的对象还没有标记时才需要去处理引用,否则说明对象还存在强引用。注意在这里discover_reference返回true表示后续不需要进行处理,否则继续。根据前面的分析,后续的动作将会对引用对象里面的对象进行处理(其实就是复制对象到新的位置,处理方法已经介绍过了)。代码如下所示:
hotspot/src/share/vm/memory/referenceProcessor.cpp
bool ReferenceProcessor::discover_reference(oop obj, ReferenceType rt) {
/*判断是否不需要处理,_discovering_refs在执行GC的时候设置为true表示不执行;
在执行完GC或者CM时,设置为false,表示可以执行RegisterReferences由参数控制。*/
if (!_discovering_refs || !RegisterReferences) return false;
// 我们在前面提到,next是用于形成链表,如果非空说明引用里面的对象已经被处理过了。
oop next = java_lang_ref_Reference::next(obj);
if (next != NULL) return false;
HeapWord* obj_addr = (HeapWord*)obj;
if (RefDiscoveryPolicy == ReferenceBasedDiscovery && !_span.contains(obj_
addr)) return false;
/*可以通过参数RefDiscoveryPolicy选择引用发现策略,默认值为0,即ReferenceBasedDiscovery,
使用1则表示ReferentBasedDiscovery。策略的选择将会影响处理的速度。*/
// 引用里面对象如果有强引用则无需处理
if (is_alive_non_header() != NULL) {
if (is_alive_non_header()->do_object_b(java_lang_ref_Reference::referent(obj)))
return false; // referent is reachable
}
if (rt == REF_SOFT) {
if (!_current_soft_ref_policy->should_clear_reference(obj, _soft_ref_
timestamp_clock)) return false;
}
/*在上面的处理逻辑中,可以看出在JVM内部,并没有针对Reference重新建立相应的处理结构来维护
相应的处理链,而是直接采用Java中的Reference对象链来处理,只不过这些对象的关系由JVM在内部
进行处理。在Java中discovered对象只会被方法tryHandlePending修改,而此方法只会处理pending
链中的对象。而在上面的处理过程中,相应的对象并没有在pending中,因此两个处理过程是不相干的。*/
HeapWord* const discovered_addr = java_lang_ref_Reference::discovered_addr(obj);
const oop discovered = java_lang_ref_Reference::discovered(obj);
// 已经处理过了则不再处理。如果是ReferentBasedDiscovery,引用对象在处理范围,
// 或者引用里面的对象在处理范围内
if (RefDiscoveryPolicy == ReferentBasedDiscovery) {
// RefeventBased Discovery策略指的是引用对象在处理范围内或者引用对象里面的对象在
// 处理范围内
if (_span.contains(obj_addr) ||
(discovery_is_atomic() &&
_span.contains(java_lang_ref_Reference::referent(obj)))) {
// should_enqueue = true;
} else {
return false;
}
}
/*把引用里面的对象放到引用对象的discovered字段里面。同时还会把对象放入DiscoveredList。
上面提到的5种引用类型,在JVM内部定义了5个链表分别处理。分别为:_discoveredSoftRefs、
_discoveredWeakRefs、_discoveredFinalRefs、_discoveredPhantomRefs、_discoveredCleanerRefs */
DiscoveredList* list = get_discovered_list(rt);
if (list == NULL) {
return false;
}
// 链表里面的每一个节点都对应着Java中的reference对象。
if (_discovery_is_mt) {
// 并行处理
add_to_discovered_list_mt(*list, obj, discovered_addr);
} else {
oop current_head = list->head();
oop next_discovered = (current_head != NULL) current_head : obj;
// 这里采用头指针加上一个长度字段来描述需要处理的reference对象。在这里面存放的对象都是
// 在相应的处理过程中还没有被放入java Reference中pending结构的对象。
oop_store_raw(discovered_addr, next_discovered);
list->set_head(obj);
list->inc_length(1);
}
return true;
}判断对象是否有强引用的方法是通过G1STWIsAliveClosure::do_object_b,判断依据也非常简单,就是对象所在分区不在CSet中或者对象在CSet但没有被复制到新的分区。代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1CollectedHeap.cpp
bool G1STWIsAliveClosure::do_object_b(oop p) {
return !_g1->obj_in_cs(p) || p->is_forwarded();
}软引用处理有点特殊,它用到_soft_ref_timestamp_clock,来自于java.lang.ref.SoftReference对象,有一个全局的变量clock(实际上就是java.lang.ref.SoftReference的类变量clock):其记录了最后一次GC的时间点(时间单位为毫秒),即每一次GC发生时,该值均会被重新设置。另外对于软引用里面的对象,JVM并不会立即清除,也是通过参数控制,有两种策略可供选择:·C2(服务器模式)编译使用的是LRUMaxHeapPolicy。·非C2编译用的是LRUCurrentHeapPolicy。需要注意的是策略的选择是通过编译选项控制的,而不像其他的参数可以由使用者控制,代码如下所示:
hotspot/src/share/vm/memory/referenceProcessor.cpp
_default_soft_ref_policy = new COMPILER2_PRESENT(LRUMaxHeapPolicy())
NOT_COMPILER2(LRUCurrentHeapPolicy())。通常生产环境中使用服务器模式,所以我们看一下LRUMaxHeapPolicy。它有一个重要的函数should_clear_reference,目的是为了判断软引用里面对象是否可以回收,代码如下所示:
hotspot/src/share/vm/memory/referencePolicy.cpp
void LRUMaxHeapPolicy::setup() {
size_t max_heap = MaxHeapSize;
max_heap -= Universe::get_heap_used_at_last_gc();
max_heap /= M;
// 根据最大可用的内存来估算软引用对象最大的生存时间
_max_interval = max_heap * SoftRefLRUPolicyMSPerMB;
}
bool LRUMaxHeapPolicy::should_clear_reference(oop p, jlong timestamp_clock) {
jlong interval = timestamp_clock - java_lang_ref_SoftReference::timestamp(p);
if(interval <= _max_interval) return false;
return true;
}在这个代码片段中,可以看到软引用对象是否可以回收的条件是:对象存活时间是否超过了阈值_max_interval。如果你继续探究策略LRUCurrentHeapPolicy,你会发现LRUCurrentHeapPolicy中的should_clear_reference函数和这里介绍的完全一样。其实这两种策略的区别是_max_interval的计算不同,但都受控于参数SoftRefLRUPolicyMSPerMB,其中LRUMaxHeapPolicy是基于最大内存来设置软引用的存活时间,LRUCurrentHeapPolicy是根据当前可用内存来计算软引用的存活时间。
在GC时的处理发现列表
处理已发现的可回收对象会根据不同的引用类型分别处理,入口函数在process_discovered_references。其主要工作在process_discovered_reflist中,代码如下所示:
hotspot/src/share/vm/memory/referenceProcessor.cpp
ReferenceProcessor::process_discovered_reflist(...)
{
bool mt_processing = task_executor != NULL && _processing_is_mt;
bool must_balance = _discovery_is_mt;
// 平衡引用队列,具体介绍可以参考8.6节
if ((mt_processing && ParallelRefProcBalancingEnabled) || must_balance) {
balance_queues(refs_lists);
}
size_t total_list_count = total_count(refs_lists);
if (PrintReferenceGC && PrintGCDetails) {
gclog_or_tty->print(", %u refs", total_list_count);
}
// 处理软引用(soft reference)
if (policy != NULL) {
if (mt_processing) {
RefProcPhase1Task phase1(*this, refs_lists, policy, true /*marks_oops_
alive*/);
task_executor->execute(phase1);
} else {
for (uint i = 0; i < _max_num_q; i++) {
process_phase1(refs_lists[i], policy,
is_alive, keep_alive, complete_gc);
}
}
} else { // policy == NULL
......
}
// Phase 2:
if (mt_processing) {
RefProcPhase2Task phase2(*this, refs_lists, !discovery_is_atomic() /*marks_
oops_alive*/);
task_executor->execute(phase2);
} else {
for (uint i = 0; i < _max_num_q; i++) {
process_phase2(refs_lists[i], is_alive, keep_alive, complete_gc);
}
}
// Phase 3:
if (mt_processing) {
RefProcPhase3Task phase3(*this, refs_lists, clear_referent, true /*marks_
oops_alive*/);
task_executor->execute(phase3);
} else {
for (uint i = 0; i < _max_num_q; i++) {
process_phase3(refs_lists[i], clear_referent,
is_alive, keep_alive, complete_gc);
}
}
return total_list_count;
}这里唯一的注意点就是当mt_processing为真时,阶段一(phase1)、阶段二(phase2)、阶段三(phase3)中多个任务分别可以并行执行(阶段之间还是串行执行);否则阶段中的多个任务串行执行。mt_processing主要受控于参数ParallelRefProcEnabled。下面介绍这三个阶段的主要工作:
·process_phase1针对软引用,如果对象已经死亡并且满足软引用清除策略才需要进一步处理,否则认为对象还活着,把它从这个链表中删除,并且重新把对象复制到Survivor或者Old区,代码如下所示:
hotspot/src/share/vm/memory/referenceProcessor.cpp
ReferenceProcessor::process_phase1(…) {
DiscoveredListIterator iter(refs_list, keep_alive, is_alive);
while (iter.has_next()) {
iter.load_ptrs(DEBUG_ONLY(!discovery_is_atomic() /* allow_null_referent */));
bool referent_is_dead = (iter.referent() != NULL) && !iter.is_referent_
alive();
if (referent_is_dead && !policy->should_clear_reference(iter.obj(), _soft_
ref_timestamp_clock)) {
// 如果对象还需要挽救,重新激活它
iter.remove();
iter.make_active();
iter.make_referent_alive();
iter.move_to_next();
} else {
iter.next();
}
}
complete_gc->do_void();
}把对象重新激活的做法就是在卡表中标示对象的状态,并且把对象复制到新的分区。keep_live就是G1CopyingKeepAliveClosure,它是真正做复制动作的地方,代码如下所示:
hotspot/src/share/vm/memory/referenceProcessor.hpp
// 对象激活
inline void make_referent_alive() {
if (UseCompressedOops) {
_keep_alive->do_oop((narrowOop*)_referent_addr);
} else {
_keep_alive->do_oop((oop*)_referent_addr);
}
}·process_phase2识别引用对象里面的对象是否活跃,如果活跃,把引用对象从这个链表里面删除。为什么要有这样的处理?关键在于discover_reference中可能会误标记,比如引用对象先于强引用对象执行,这个时候就发生了误标记,所以需要调整;这个阶段比较简单,不再列出源码。
·process_phase3清理引用关系,首先把对象复制到新的分区,为什么呢?因为在前面提到discovered列表会被放到pending列表,而pending列表会进入到引用队列供后续处理,然后把引用对象里面的对象设置为NULL,那么原来的对象没有任何引用了,就有可能被回收了。代码如下所示:
hotspot/src/share/vm/memory/referenceProcessor.cpp
void ReferenceProcessor::process_phase3(…) {
DiscoveredListIterator iter(refs_list, keep_alive, is_alive);
while (iter.has_next()) {
// 先执行update_discovered,就是把对象复制到新的分区
iter.update_discovered();
iter.load_ptrs(DEBUG_ONLY(false /* allow_null_referent */));
if (clear_referent) {
// 如果不是软引用,则清理指针,此时除了链表不会有任何对象引用它了
iter.clear_referent();
} else {
// 再次确保对象被复制
iter.make_referent_alive();
}
iter.next();
}
// 更新链表
iter.update_discovered();
complete_gc->do_void();
}上面的clear_referent就是把对象的引用关系打断了,所以设置为NULL,代码如下所示:
hotspot/src/share/vm/memory/referenceProcessor.hpp
void DiscoveredListIterator::clear_referent() {
oop_store_raw(_referent_addr, NULL);
}上面的update_discovered就是把待回收的对象复制到新的分区,形成新的链表,供后续pending列表处理。代码如下所示:
hotspot/src/share/vm/memory/referenceProcessor.hpp
inline void DiscoveredListIterator::update_discovered() {
// _prev_next指向DiscoveredList
if (UseCompressedOops) {
if (!oopDesc::is_null(*(narrowOop*)_prev_next)) {
_keep_alive->do_oop((narrowOop*)_prev_next);
}
} else {
if (!oopDesc::is_null(*(oop*)_prev_next)) {
_keep_alive->do_oop((oop*)_prev_next);
}
}
}重新激活可达的引用
正如我们前面提到的,在引用处理的时候,pending会加入引用队列,所以待回收的对象还不能马上被回收,而且待回收的对象都已经放入discovered链表,所以这个时候只需要把discovered链表放入pending形成的链表中。主要代码在enqueue_discovered_ref_helper中。这个处理比较简单,不再列出源码。
日志解读
本节通过一个例子来分析引用处理。代码如下所示:
public class ReferenceTest {
public static void main(String[] args) {
Map<Integer, SoftReference<String>> map = new HashMap<>();
int i = 0;
while (i < 10000000) {
String p = "" + i;
map.put(i, new SoftReference<String>(p));
i++;
}
System.out.println("done");
}
}运行参数设置如下所示:
-Xmx256M -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintReferenceGC
-XX:+PrintGCTimeStamps -XX:+TraceReferenceGC -XX:SoftRefLRUPolicyMSPerMB=0得到日志片段如下:
0.193: [GC pause (G1 Evacuation Pause) (young)0.208: [SoftReference, 8285
refs, 0.0008413 secs]0.208: [WeakReference, 4 refs, 0.0000137 secs]0.208:
[FinalReference, 1 refs, 0.0000083 secs]0.208: [PhantomReference, 0
refs, 0 refs, 0.0000094 secs]0.208: [JNI Weak Reference, 0.0000063
secs], 0.0158259 secs]
……
[Ref Proc: 1.1 ms]
[Ref Enq: 0.2 ms]可以看到在这一次YGC中,一共有8285个软引用被处理。
参数介绍和调优
软引用在实际工作中关注的并不多,原因主要有两点。第一,软引用作为较难的知识点,实际工作中真正使用的并不多;第二,介绍软引用对象回收细节的文章也不多。本章较为详细地介绍了G1中软引用回收的步骤,下面介绍一下软引用相关的参数和优化:
·参数PrintReferenceGC,默认值为false,可以打开该参数以输出更多信息。如果是调试版本还可以打开TraceReferenceGC获得更多的引用信息。
·参数ParallelRefProcBalancingEnabled,默认值为true,在处理引用的时候,引用(软/弱/虚/final/cleaner)对象在同一类型的队列中可能是不均衡的,如果打开该参数则表示可以把链表均衡一下。注意这里的均衡不是指不同引用类型之间的均衡,而是同一引用类型里面有多个队列,同一引用类型多个队列之间的均衡。
·参数ParallelRefProcEnabled,默认值为false,打开之后表示在处理一个引用的时候可以使用多线程的处理方式。这个参数主要是控制引用列表的并发处理。另外引用的处理在GC回收和并发标记中都会执行,在GC中执行的引用处理使用的线程数目和GC线程数目一致,在并发标记中处理引用使用的线程数目和并发标记线程数一致。实际中通常打开该值,减少引用处理的时间。
·参数RegisterReferences,默认值true,表示可以在遍历对象的时候发现引用对象类型中的对象是否可以回收,false表示在遍历对象的时候不处理引用对象。目前的设计中在GC发生时不会去遍历引用对象是否可以回收。需要注意的是该参数如果设置为false,则在GC时会执行软引用对象是否可以回收,这将会增加GC的时间,所以通常不要修改这个值。
·参数G1UseConcMarkReferenceProcessing,默认值true,表示在并发标记的时候发现对象。该值为实验选项,需要使用-XX:+UnlockExperimentalVMOptions才能改变选项。
·参数RefDiscoveryPolicy,默认值为0,0表示ReferenceBasedDiscovery,指如果引用对象在我们的处理范围内,则对这个引用对象进行处理。1表示ReferentBasedDiscovery,指如果引用对象在我们的处理范围内或者引用对象里面的对象在处理范围内,则对引用对象处理。1会导致处理的对象更多。
·参数SoftRefLRUPolicyMSPerMB,默认值为1000,即对软引用的清除参数为每MB的内存将会存活1s,如最大内存为1GB,则软引用的存活时间为1024s,大约为17分钟,但是如果内存为100GB,这个参数不调整,软引用对象将存活102400s,大约为28.5小时。所以需要根据总内存大小以及预期软引用的存活时间来调整这个参数。















 1131
1131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









