







1. 交互式运行Spark(shell)
- 进入spark目录
- To launch Pyspark,we need to use
sudo bin/pyspark(你不一定需要加sudo) - To launch spark of scala version, use
sudo bin/spark-shell
2. 日志设置
我们需要在conf目录下创建一个名为log4j.properties的文件来管理日志设置。设置内容可参考已经存在的log4j.properties.template文件内容。
我们可以通过log4j.rootCategory=WARN, console来将日志级别设置为只显示警告及更严重的信息。
3. Spark原理简介
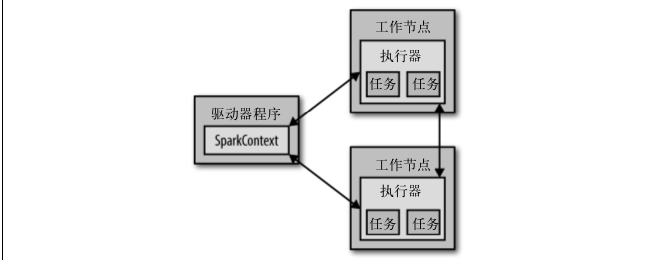
从上层来看,每个 Spark 应用都由一个驱动器程序(driver program)来发起集群上的各种并行操作。驱动器程序包含应用的 main 函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作。Spark Shell就是驱动程序。
驱动器程序通过一个 SparkContext 对象来访问 Spark。这个对象代表对计算集群的一个连接。shell 启动时已经自动创建了一个 SparkContext 对象,是一个叫作 sc 的变量。我们可以用它创建RDD。
驱动器程序一般要管理多个执行器节点,下图展示了spark如何在集群上运行:
4. 独立应用中使用Spark
除了交互式运行之外,Spark 也可以在 Java、Scala 或 Python 的独立程序中被连接使用。这与在 shell 中使用的主要区别在于你需要自行初始化 SparkContext。
(1) 应用与Spark连接
在 Python 中, 你 可 以 把 应 用 写 成 Python 脚 本, 但 是 需 要 使 用 Spark 自 带 的 bin/spark-submit 脚本来运行。 spark-submit 脚本会帮我们引入 Python 程序的 Spark 依赖。这个脚本为 Spark 的 PythonAPI 配置好了运行环境。
编写好脚本以后,你需要运行如下命令:
bin/spark-submit my_script.py
(2) 初始化SparkContext
一旦完成了应用与 Spark 的连接,接下来就需要在你的程序中导入 Spark 包并且创建SparkContext。
你可以通过先创建一个 SparkConf 对象来配置你的应用,然后基于这个SparkConf 创建一个 SparkContext 对象。
Python Example:
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf=conf)Scala example:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
val conf = new SparkConf().setMaster("local").setAppName("My App")
val sc = new SparkContext(conf)创建SparkContext的基本方法需要传递两个参数:
- 集群url:通过
setMaster()方法来创建,告诉Spark如何连接到集群上。上面我们使用了local,表示spark运行在单机单线程上。 - 应用名:通过
setAppName()方法创建。当连接到一个集群时,这个值可以帮助你在集群管理器的用户界面中找到你的应用。
关闭Spark可以调用SparkContext的stop()方法。
5. 独立应用示例
使用scala的sbt构建一个WordCount应用。
WordCount.scala
// 创建一个Scala版本的Spark Context
val conf = new SparkConf().setAppName("wordCount")
val sc = new SparkContext(conf)
// 读取我们的输入数据
val input = sc.textFile(inputFile)
// 把它切分成一个个单词
val words = input.flatMap(line => line.split(" "))
// 转换为键值对并计数
val counts = words.map(word => (word, 1)).reduceByKey{case (x, y) => x + y}
// 将统计出来的单词总数存入一个文本文件,引发求值
counts.saveAsTextFile(outputFile)sbt构建文件
name := "learning-spark-mini-example"
version := "0.0.1"
scalaVersion := "2.10.4"
// 附加程序库
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "1.2.0" % "provided"
)运行
sbt clean package
$SPARK_HOME/bin/spark-submit \
--class com.oreilly.learningsparkexamples.mini.scala.WordCount \
./target/... (as above) \
./README.md ./wordcountsRef















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









