






Tomcat中可以放多个Java项目的jar文件,如果每个jar文件中都有一个User的类,那么User类在没有自定义类加载器的情况下是只能加载一次;想要加载多次,只能自定义类加载器
JDK:开发环境
JRE:运行环境
JVM:JRE的一部分,实现Java跨平台的核心

三、==和equals
==:比较引用地址
equals:先比较引用地址,再比较内容
其它Object对象和String的equals不是同一个方法(String是最终类,被final修饰过)
四、new String("abc")到底创建了几个对象
- 如果'abc'这个字符串常量不存在,则创建两个对象,分别是'abc'这个字诗串常量,以及'new String'这个实例对象
- 如果'abc'这个字符串常量存在,则只会创建一个对象
- 因为String是最终类,被final修饰过
五、String、StringBuffer、StringBuilder的区别
String:string s="4";s=5; 其实4还在
StringBuffer:线程安全
StringBuilder:线程不安全(链式调用)
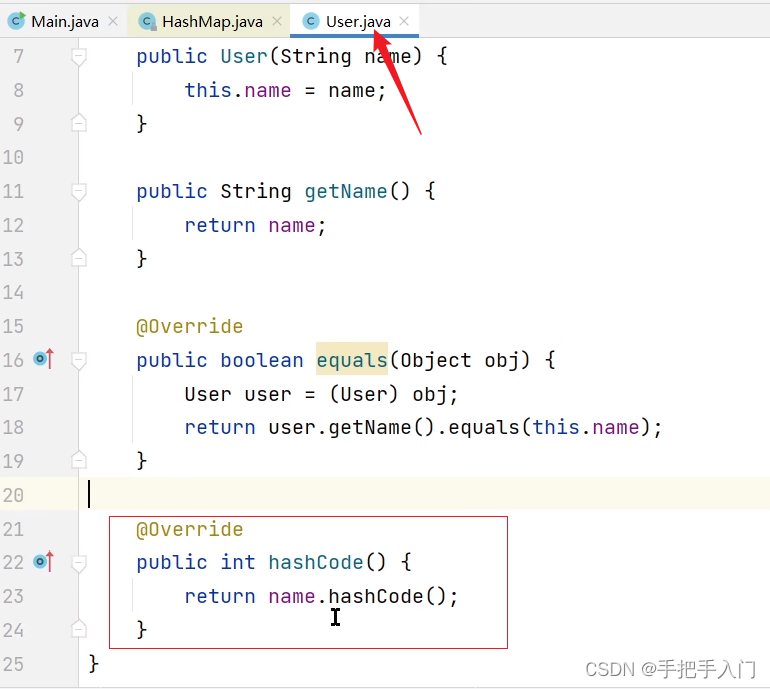
比较两个类是否相等

八、
重载:1、和返回值无关
重写:

iterator
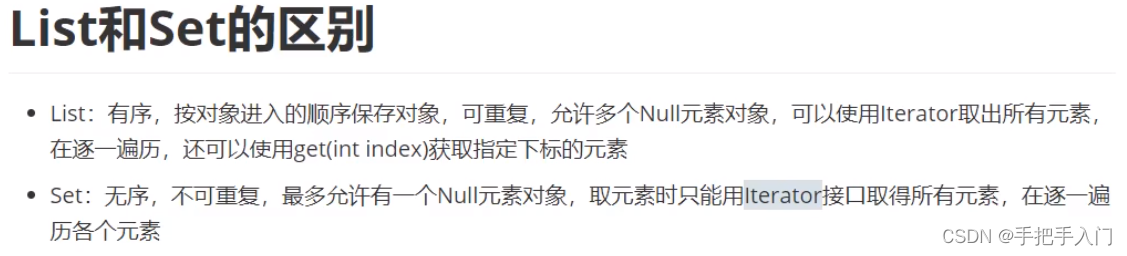
19、Java中 List、Set、Map 的区别
Java集合List、Set和Map史上最详细讲解_java list set map-CSDN博客
Java中 List、Set、Map 之间的区别_map集合处理起来为什么比list效率高-CSDN博客
9、Redis的缓存穿透、缓存击穿和缓存雪崩_redis 缓存穿透,雪崩-CSDN博客
1、缓存穿透
用户请求的数据在缓存中和数据库中都不存在,不断发起这样的请求,给数据库带来巨大压力;解决方案:①数据库没有数据,也给Redis一个空值,②布隆过滤
2、缓存击穿
部分热点key过期,请求瞬间给数据库带来巨大的冲击;解决方案:①加锁,但是会降低效率,②通过程序策略来控制缓存过期时间
3、缓存雪崩
同一时段大量热点key同时失效或者Redis服务宕机,导致大量请求到达数据库带来巨大压力。解决方案:①给不同的Key的TTL添加随机值,②利用Redis集群
, ③添加多级缓存(请求到达浏览器,nginx可以做缓存,未命中找Redis,再未命中找JVM,最后到数据库)
Java事务失效时,Redis不会自动进行回滚操作,你需要通过编程方式来处理这种情况。如果你的应用程序在使用Redis时遇到了错误,并且你希望回滚到某个状态,你需要自己实现这种逻辑。例如,你可以记录每次更改的状态,并在事务失败时手动恢复到上一个状态。但这需要额外的开发工作和维护成本。
#{}可以防止sql注入
线程在阻塞状态仍然占用内存,但是没有占用线程。Java中加锁、同步、线程安全都会影响性能。
12、Java中锁的实现方式
(Redis 本身是单线程的,所有的命令都按照先后顺序执行,避免了多线程下的竞态条件等问题。Redis也是一种锁,线程安全的分布式锁;Redis 实现线程安全不是通过锁机制来实现的,而是通过内部的单线程执行命令的机制来保证命令执行的顺序性和不会被并发问题所干扰。)
13、Spring AOP
Spring的核心是AOP和IOC,AOP的核心即切面,而AOP的核心就是动态代理。AOP在Spring框架中应用非常广泛,最常见的事务。
在Spring中的AOP有6种增强方式,分别是:
1、Before 前置增强
2、After 后置增强
3、Around 环绕增强
4、AfterReturning 最终增强
5、AfterThrowing 异常增强
6、DeclareParents 引入增强
15、事务
Spring事务的实现方式和实现原理
Spring事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,Spring是无法提供事务功能的。Spring事务实现主要有两种方法:
- 编程式:beginTransaction()、commit()、rollback()等事务管理相关的方法,
- 声明式:利用注解Transactional 或者aop配置
谈谈你对事务的理解?
当Java中一个方法内有多次对数据库的增删改查等操作,并且这些操作之间有一些关联关系,如果方法执行一半出问题报错,后面的操作将不会执行,造成数据异常,但是使用了事务以后可以如果中途执行失败,可以回退到方法执行之前,保证数据不出问题。
事务的隔离级别?
- ISOLATION_DEFAULT: 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.另外四个与JDBC的隔离级别相对应。
- ISOLATION_READ_UNCOMMITTED:读未提交,这是事务最低的隔离级别,它充许另外一个事务可以看到这个事务未提交的数据。这种隔离级别会产生脏读,不可重复读和幻像读。
- ISOLATION_READ_COMMITTED:读提交,保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据。
- ISOLATION_REPEATABLE_READ:可重复读取,这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻读。它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
- ISOLATION_SERIALIZABLE;序列化,这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。除了防止脏读,不可重复读外,还避免了幻像读。
事务的传播行为
所谓事务的传播行为就是多个事务方法相互调用时,事务如何在这些方法间传播。Spring 支持 7 种事务传播行为,默认为 REQUIRED。
1.REQUIRED
@Transactional(propagation=Propagation.REQUIRED)
如果当前有事务,加入到这个事务中。如果当前没有事务,就新建一个事务。2.REQUIRES_NEW
@Transactional(propagation=Propagation.REQUIRES_NEW)
不管是否存在事务,都创建一个新的事务,原来的挂起,新的执行完毕,继续执行老的事务。表示当前方法必须运行在它自己的事务中。如果使用 JTATransactionManager 的话,则需要访问 TransactionManager。3.MANDATORY
@Transactional(propagation=Propagation.MANDATORY)
表示该方法必须在事务中运行,如果当前不存在事务,则会抛出一个异常。不会主动开启一个事务。4.NEVER
@Transactional(propagation=Propagation.NEVER)
表示该方法不应该运行在事务上下文中,如果当前正有一个事务在运行,则会抛出异常。(与Propagation.MANDATORY相反)。5.SUPPORTS
@Transactional(propagation=Propagation.SUPPORTS)
表示当前方法不需要事务上下文,但是如果存在当前事务的话,那么这个方法会在这个事务中运行。6.NOT_SUPPORTED
@Transactional(propagation=Propagation.NOT_SUPPORTED)
表示该方法不应该运行在事务中,如果存在当前事务,在该方法运行期间,当前事务将被挂起。如果使用 JTATransactionManager 的话,则需要访问 TransactionManager。7.NESTED
@Transactional(propagation=Propagation.NESTED)
表示如果当前已经存在事务,那么该方法将会在嵌套事务中运行。嵌套的事务可以独立于当前事务进行单独地提交或回滚。如果当前不存在事务,那么其行为等价于 Propagation.REQUIRED。嵌套事务一个非常重要的概念就是内层事务依赖于外层事务。外层事务失败时,会回滚内层事务所做的动作。而内层事务操作失败并不会引起外层事务的回滚。综上所述,NESTED 和 REQUIRES_NEW 非常相似,都是开启一个属于它自己的新事务。使用 REQUIRES_NEW 时,内层事务与外层事务就像两个独立的事务一样,一旦内层事务进行了提交后,外层事务不能对其进行回滚。当内部事务开始执行时, 外部事务将被挂起,内务事务结束时,外部事务将继续执行。两个事务互不影响,两个事务不是一个真正的嵌套事务,同时它还需要 JTA 事务管理器的支持。
使用 NESTED 时,外层事务的回滚可以引起内层事务的回滚,而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。嵌套事务开始执行时,它将取得一个 savepoint,如果这个嵌套事务失败,将回滚到此 savepoint。嵌套事务是外部事务的一部分,只有外部事务结束后它才会被提交。
什么情况下事务会失效?
@Transactional放在非public修饰的方法上
如使用mysql且引擎是MyISAM,则事务会不起作用,原因是MyISAM不支持事务,可以改成InnoDB引擎
在同一个类中,在没有加事务的方法中调用带事务的方法,事务会失效。
Spring事务总结
Spring事务的本质其实就是Spring AOP和数据库事务,Spring将数据库的事务操作提取为切面,通过AOP在方法执行前后增加数据库事务操作;不同的事务隔离级别通过使用不同类型的锁来实现对数据资源的访问控制,从而保证了事务的隔离性和数据的一致性;事务的隔离级别越高,性能越低,需在两者间选其一
18、MySQL
一、MySQL语句的执行顺序大致如下:
FROM
JOIN(如果存在)
ON(如果存在,在JOIN之后)
WHERE
GROUP BY
AVG、SUM(聚合函数)
HAVING
SELECT(如果存在)DISTINCT
ORDER BY
LIMIT二、MySQL索引优化
- 索引就是数据结构
- 索引的类型(主键、唯一、普通、组合)
- 字符串不加单引号索引会失效。
- 使用or连接时索引失效。
内连接时,mysql会自动把小结果集的选为驱动表,所以大表的字段最好加上索引。左外连接时,左表会全表扫描,所以右边大表字段最好加上索引,右外连接同理。我们最好保证被驱动表上的字段建立了索引。
三、MySQL联表优化
MYSQL执行过程和顺序详解_mysql执行顺序-CSDN博客
- 使用联表替代子查询,因为子查询需要建立/销毁临时表,开销更大。
- 用EXISTS(或内连接)替代IN、用NOT EXISTS(或者外连接)替代NOT IN
- 用EXISTS替换DISTINCT
- 字符串型 =,in,like’abc%‘索引生效;!=, not in, like'%abc', like'a%bc'索引失效(like'a%bc'生效一部分!)
- 数值型 =, !=, in, not in都可以索引生效
避免使用 != 或者 <> 或者 null 或者 OR 或者 like前导 或者 in 或者 not in 或者 =号左边不能使用函数(左边使用函数,索引直接失效)
=号左边使用函数会直接导致索引失效,因为MySQL的查询优化器在处理IN操作符时,倾向于使用全表扫描而不是索引查找,特别是当IN列表中的值很多时。
复合索引有4个字段:ABCD,where中ABCD的先后位置会影响性能吗?复合索引的顺序和WHERE子句中条件的顺序确实会影响查询性能。复合索引是由多个字段组合而成的索引,MySQL使用这些索引来优化查询的执行。
-
索引前缀使用: MySQL可以使用复合索引的前缀来查找数据。这意味着即使你没有为每个字段单独创建索引,也可以在
WHERE子句中使用这些字段。但是,MySQL只能有效地使用从左到右的索引前缀。也就是说,如果你的复合索引是(A, B, C, D),那么(A, B)、(A, B, C)都是有效的前缀,但(B, C)或(C, D)则不是。 -
查询条件顺序: 在
WHERE子句中,条件的顺序也会影响性能。MySQL优化器会尽可能地先应用那些可以选择性最高的条件。通常,这意味着那些在索引中最左边的字段的条件应该放在WHERE子句的前面。例如,如果有复合索引(A, B, C, D),那么查询WHERE A = value AND B = value AND C = value AND D = value很可能会比WHERE D = value AND C = value AND B = value AND A = value性能更好。 -
索引选择性: 索引字段的选择性是指一个字段值的唯一性程度。选择性越高的字段,作为查询条件时,能够排除更多的行,从而提高查询性能。因此,在复合索引中,选择性最高的字段应该放在最左边。
-
查询优化器: MySQL的查询优化器会根据表的统计信息来决定最有效的查询执行计划。虽然优化器会尝试找出最佳的执行路径,但编写查询时考虑索引的顺序仍然非常重要。
20、关于开启多线程的例子
Java: 模拟开启多个线程处理数据,完成数据处理后回到主线程,并return数据-CSDN博客
21、String的内容太多怎么分叶返回到接口呢?
用String的索引,最好是在存入数据库时做优化,如果字符串太长还得先读到程序中(内存中),对于服务器来说压力是非常大的
21、reids
22、Java开发中常用的数据结构















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









