









一、概述
二、详细内容
- abstract
a. deberataV3, debearta的改进版本
b. 方法1(改进mlm):通过使用RTD来替换原始的MLM任务,一个更有效的简单的预训练方法
c. 方法2(改进electra):
ⅰ. 原因:鉴别器和生成器将所有的token放到不同的方向,一直在那里拔河,tug-of-war
ⅱ. 方法:梯度解纠缠embedding来避免拔河
ⅲ. 好处:提高训练效率+提升预训练模型质量
d. 效果
ⅰ. 和deberta一样的设置
ⅱ. v3 large模型:NLU +1.37% vs v1, +1.91 vs electra
ⅲ. multi-lingual model:- zero-short +3.6% vs xml-r Base
- introduction
a. RoBERTa: 大的batch size和 more dat来提高模型的容量
b. deBERTa: 分散注意力机制,来改善相当位置编码机制,1/8的 xxlarge T5胜出
c. RTD:生成器+鉴别器
d. ELECTRA缺点:
ⅰ. 鉴别器和生成器用同一个共享层 -> 伤害训练效率,影响模型表现。
ⅱ. 原因:loss函数差别非常大 -> 在那里拔河。
ⅲ. 发现:生成器和鉴别器用单独的embeding对使用鉴别器fine tune下游任务,伤害比较大
ⅳ. 改进:新的共享层: gradient-disentangled embedding sharing (GDES) method
e. 改进
ⅰ. finding:共享的优点:生成器有利于改进鉴别器,但是在那里拔河也不好,也会伤害模型
ⅱ. MLM->RTD:liyo0ng鉴别器来判断是否有token corrupted
ⅲ. new embedding sharing method:新的共享层 gradient-disentangled embedding sharing (GDES) method
ⅳ. 方法:还是鉴别器和生成器用同一个embedding,阻止鉴别器中的梯度反向传播到生成器embedding,以避免拔河动态。 - Background
a. transformer
ⅰ. multi-head self-attention
ⅱ. fully connected positional feed-forward network
ⅲ. attention机制对位置编码不友好:绝对位置+相对位置编
b. deberta
ⅰ. 相对位置信息利用:分开对content和postion进行编码。来更好的利用位置信息
ⅱ. 绝对位置信息利用:在MLM decoding层加入绝对位置信息
c. ELECTRa
ⅰ. MLM:Masked Language Model
ⅱ. RTD:replaced token detection
ⅲ. generator: MLM -> 生成一些tokens来替换mask,然后再送到鉴别器
ⅳ. discriminator:分类
ⅴ. loss:MLM + LRTD * k - DeBERTaV3
a. 生成器的宽度和鉴别器一样但是深度只有一半
b. DeBERTaV3 significantly outperforms DeBERTa, i.e., +2.5% on the MNLI-m accuracy and +3.8% on the SQuAD v2.0 F1.
c. MLM和RTD:相当于是多任务学习,但是差异实在太大了,导致将embedding推到不同的方向
d. MLM:token->相同语义放到一起->找到相同语义的词
e. RTD: token->从相同语义里面来区分相似的token->分类精度
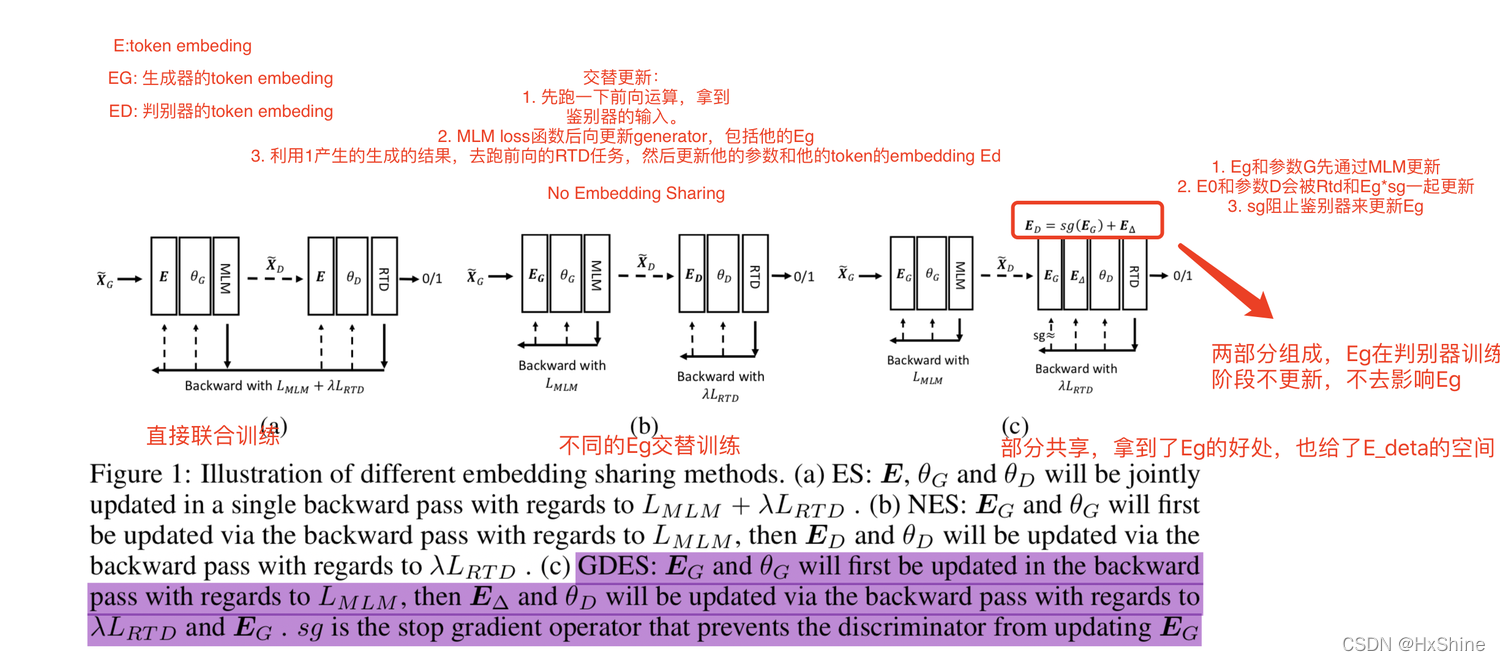
f. 3.2 Token Embedding Sharing
ⅰ. NES具体步骤:- 交替更新:
-
- 先跑一下前向运算,拿到鉴别器的输入。
-
- MLM loss函数后向更新generator,包括他的Eg
-
- 利用1产生的生成的结果,去跑前向的RTD任务,然后更新他的参数和他的token的embedding Ed
ⅱ. GDES
- 利用1产生的生成的结果,去跑前向的RTD任务,然后更新他的参数和他的token的embedding Ed
-
- Eg和参数G先通过MLM更新
-
- E_deta和参数D会被Rtd更新
-
- Eg*sg阻止鉴别器来更新Eg
- 总结:阻止了鉴别器对Eg的影响,这里Ed=sg*Eg+E_deta,训练判别器的时候,不更新Eg,sg为0,相当于判别器不去影响生成器的token embedding Eg
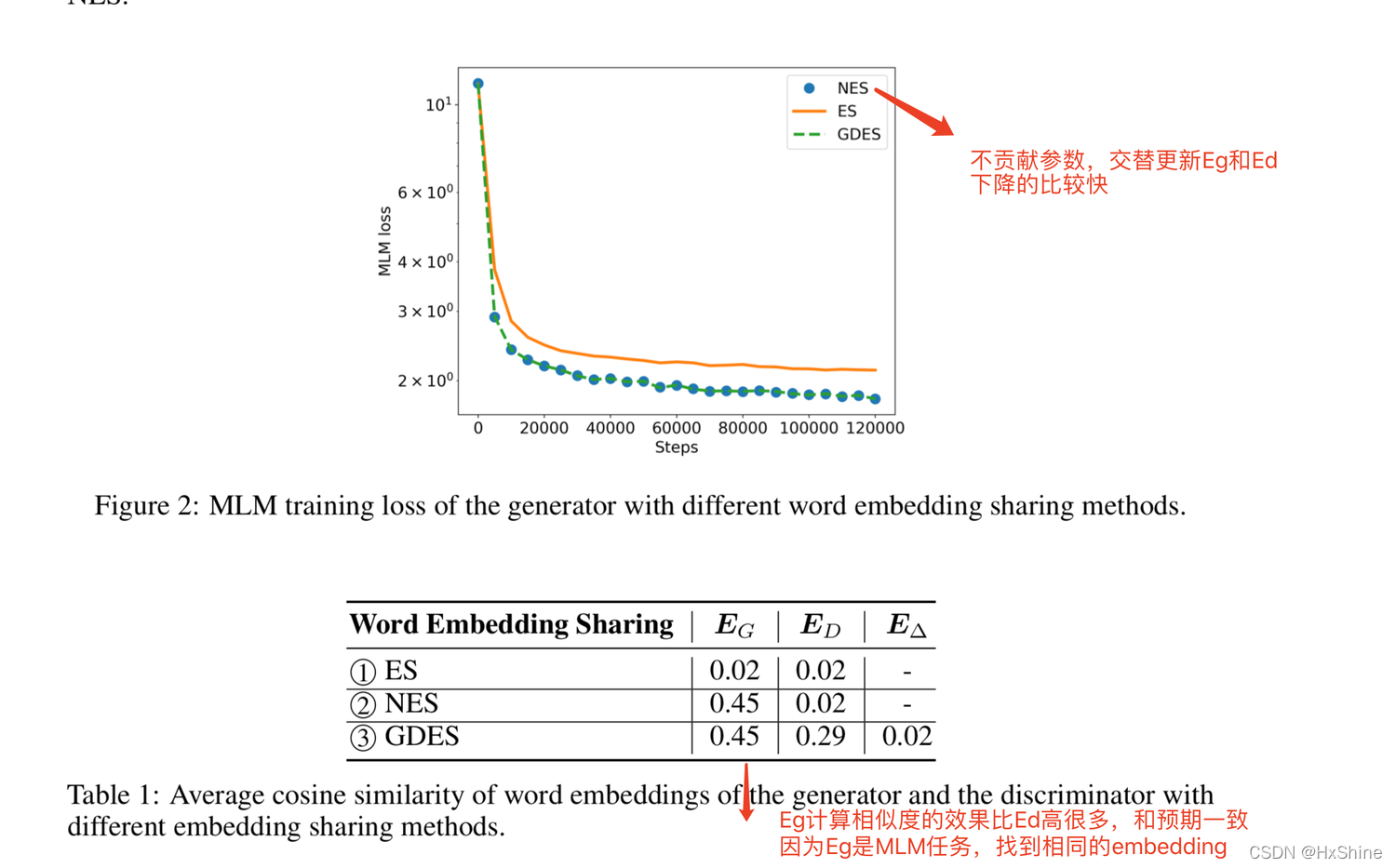
ⅲ. 实验 - NES:不共享参数,速度和收敛快很多,Eg的相似度计算效果好很多
- GDES:Eg相似度效果计算好很多,Ed<Eg,但是也好一点
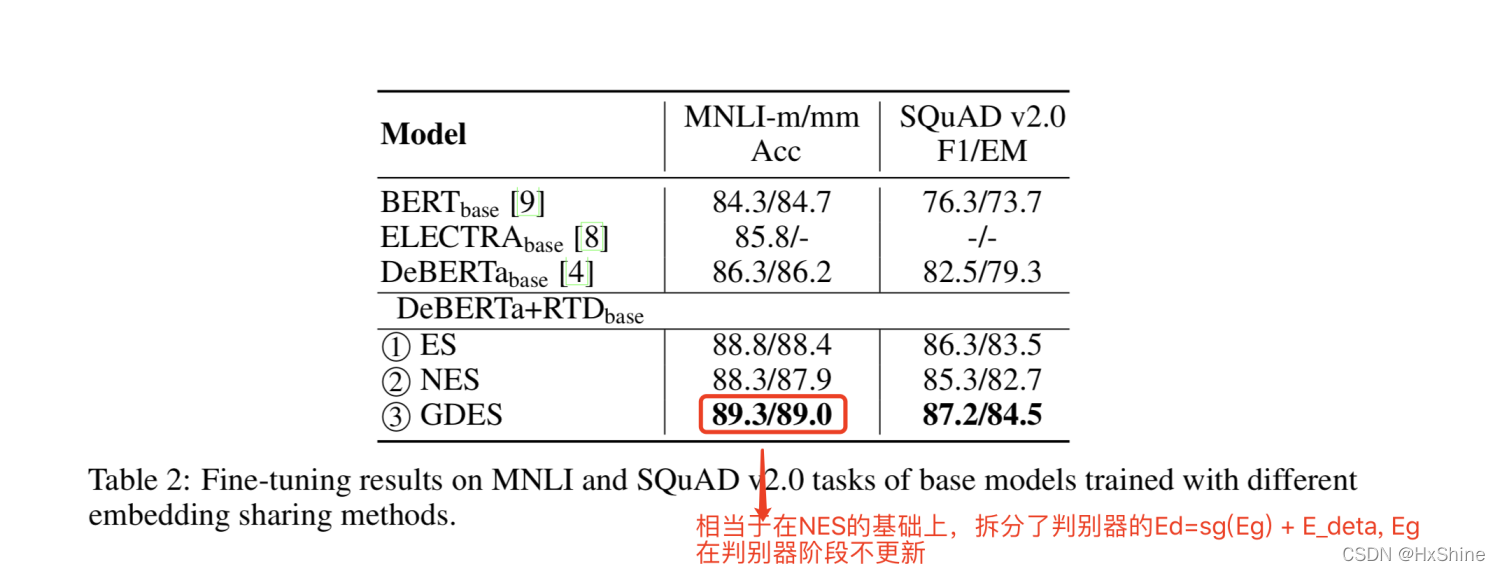
- fine tune训练:NLI 居然比Bert-base高5个点???,squad高了11个点??
ⅳ. 实验对别总结 - ES(完全共用):共享embedding训练
- NES(完全不影响):交替训练,不共享生成器和判别器的Embedding层,也不共享参数层
- GDES(MLM影响Eg和Ed,RTD判别训练不影响Eg,这样就会往同一个方向去训练了):还是共享Eg,但是添加了E_deta,Ed = sg(Eg) + E_deta,Eg在判别器阶段不更新,不共享参数层
- experiment
a. 大模型对比
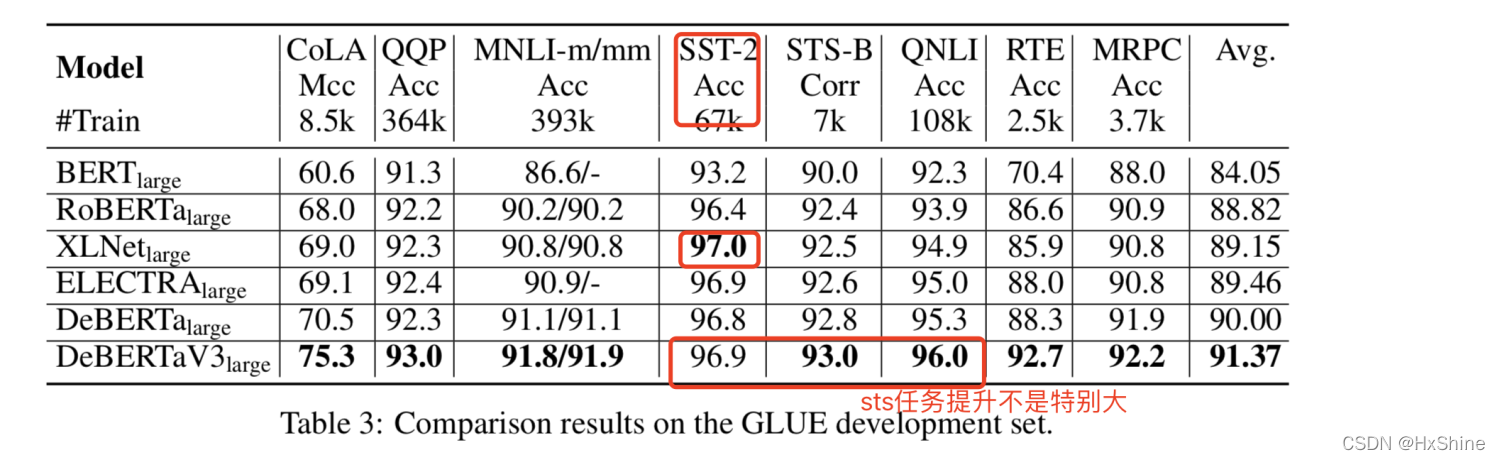
ⅰ. low resource task提升非常大,RTE+4.4%,CoLA+4.8%,说明DeBERTav3在同样的数据情况下,更有效。sts任务提升不大,可能是饱和了。
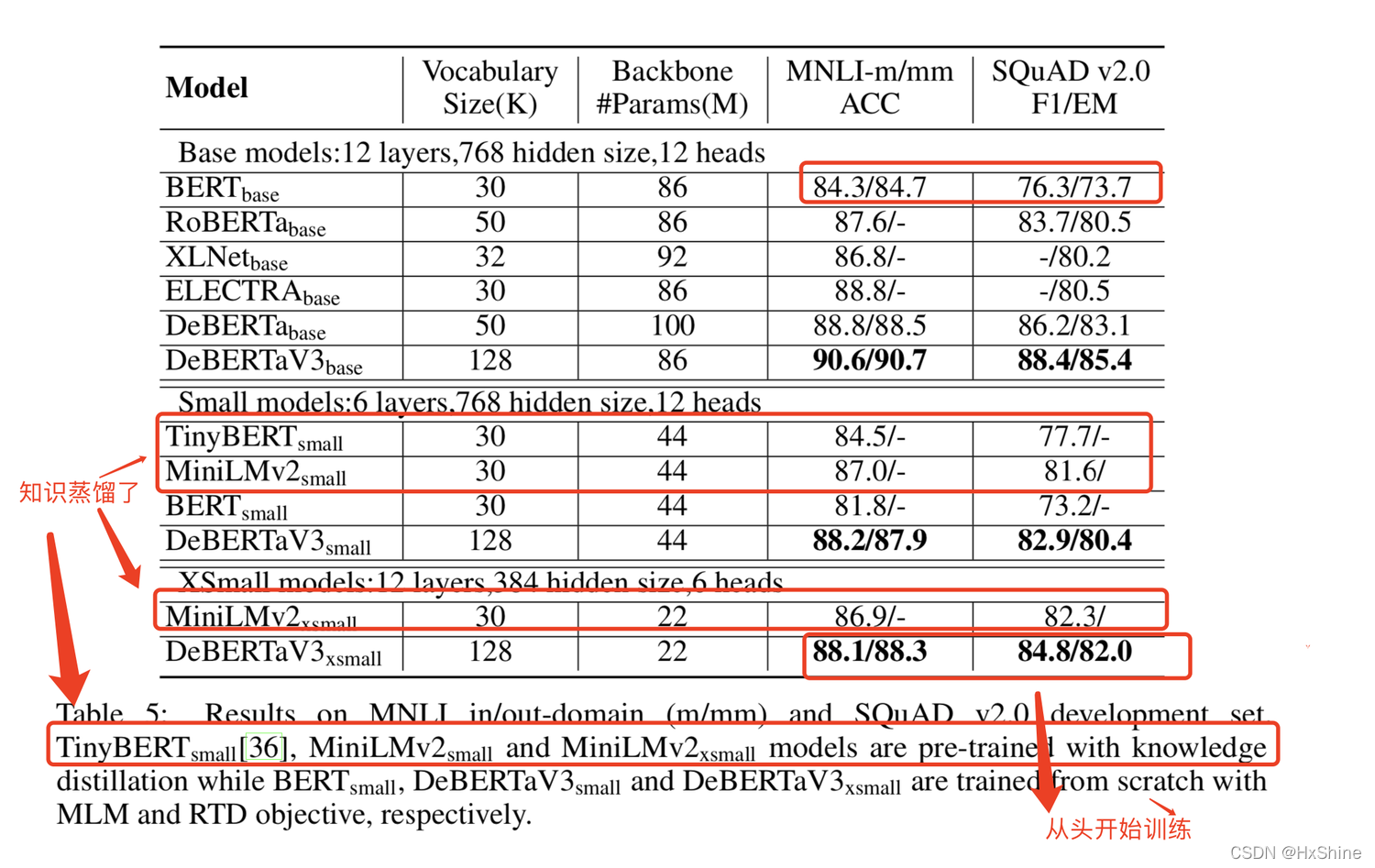
b. 小模型对比
ⅰ. base模型,MNLI-m任务:90.6 vs 84, squad: 88 vs 76.3
ⅱ. small:+6.4%提升,RoBERTa-base 1/4的参数,效果还好
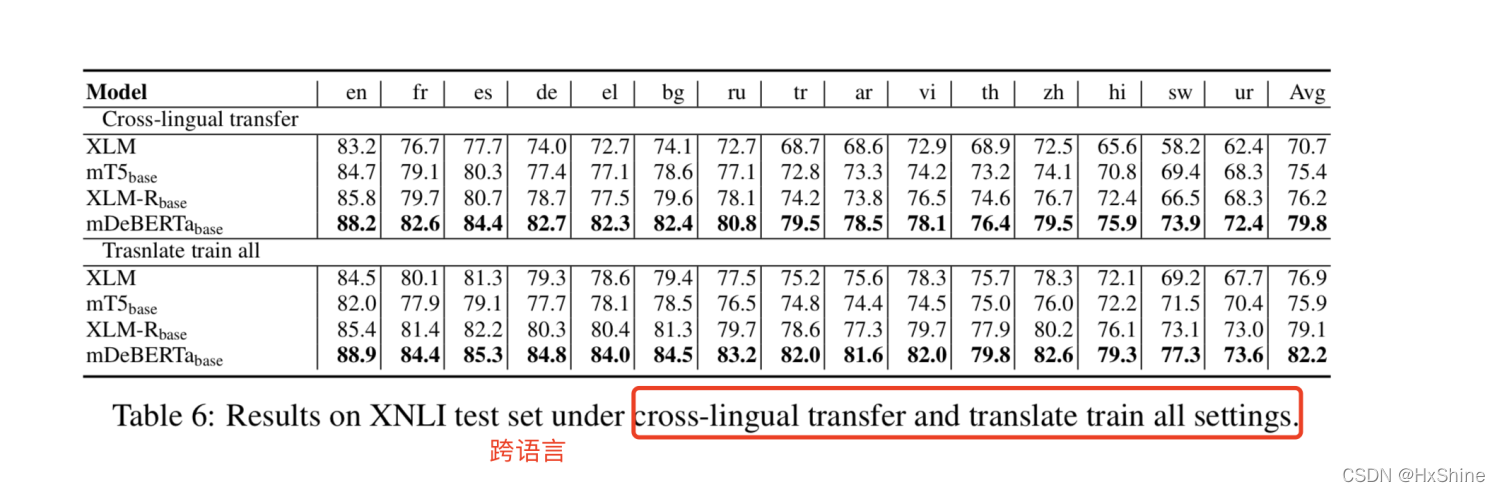
c. 跨语言模型
ⅰ. 提升巨大
三、知识点解读
-
ES(完全共用):共享embedding训练
-
NES(完全不影响):交替训练,不共享生成器和判别器的Embedding层,也不共享参数层
-
GDES(MLM影响Eg和Ed,RTD判别训练不影响Eg,这样就会往同一个方向去训练了):还是共享Eg,但是添加了E_deta,Ed = sg(Eg) + E_deta,Eg在判别器阶段不更新,不共享参数层
-
优点:
a. 收敛的更快
b. 生成器的Eg相似度计算效果更好
-
下游任务fine-tune:
a. GDES:居然比Bert-base高5个点???,squad高了11个点??
四、详细实验对比
-
大模型对比:low resource task提升非常大,RTE+4.4%,CoLA+4.8%,说明DeBERTav3在同样的数据情况下,更有效。sts任务提升不大,可能是饱和了。
-
小模型对比,6层模型比12成的bert还好啊?
-
跨语言:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









