







 本文作者作为工科硕士,分享如何使用Python实现实验数据的批量处理,简化繁琐的工作流程。通过读取TXT文件,处理并保留关键数据,转换格式,最终实现批量处理并适用于特定分析软件。代码实现包括读取文件、数据处理、文件写入和批量操作,旨在帮助有类似需求的研究者。
本文作者作为工科硕士,分享如何使用Python实现实验数据的批量处理,简化繁琐的工作流程。通过读取TXT文件,处理并保留关键数据,转换格式,最终实现批量处理并适用于特定分析软件。代码实现包括读取文件、数据处理、文件写入和批量操作,旨在帮助有类似需求的研究者。
本即将毕业工科硕士,编程小白,偶然认识了python,就觉得这东西很牛逼,在网上找了几节python教程视频看完后更加感受到了它的强大之处。在看视频教程的过程中想到能用python把工作学习中的一些繁琐量大的工作变得简单,也就是自动化办公,在具体实现的过程中也遇到了很多问题,好在参阅了各路大神的杰作,将各种困难逐一击破,可能在大神看来解决的办法比较蠢,但终究达到了目的,现在已经在本人所在课题组推广。发这篇博文有三个目的:1.给其他有相同需要的搬砖人提供帮助;2.和大家交流其中一些问题的解决方法;3.希望在各路大神的指点下,能获得更高程度的提升。
先介绍下问题背景。我们实验室有一台热失重分析仪,这台设备基本实验室百分之六十的人都会用到,但是在实验完成后处理实验数据是个大麻烦,少则几十组,多则上百组。
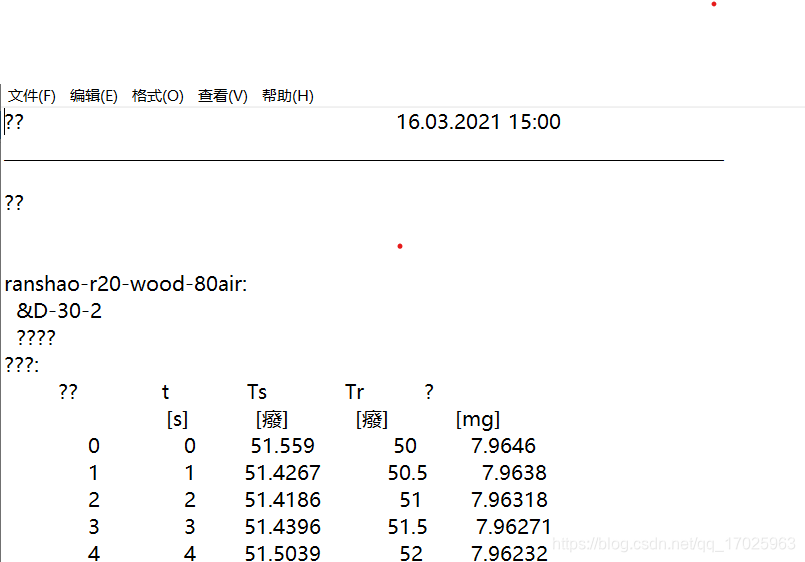
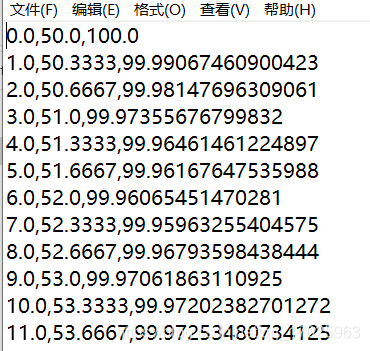
如上图,需要处理的是上百个这样的txt,最后需要处理成下图形式的txt,然后导入Proteus Analysis软件做相关分析。中间的变化主要是去掉了原有的无关内容(如标题,标尾等),只保留第一列、第四列、第五列的数据,第五列的数据由质量转换为失重百分比,每列数据以“,”分隔。
话不多说,先分享全部代码,再做详细解释!
#最终保存的是.txt,适合于热重分析
import numpy as np
import os
import xlrd
import xlwt
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
path=r'D:\Python data save\test\auto work\test data\txt data' #给出文件路径
files=os.listdir(path) #得到文件夹下所有文件的名称
fileslens=len(files) #得到文件夹下有多少个txt文件
for filename in files:
domain=os.path.abspath(r'D:\Python data save\test\auto work\test data\txt data')
filename2=os.path.join(domain,filename) #filename2是带路径的文件名
with open(filename2,'r') as f:
data=f.rea 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









