






 本文介绍了数据库设计中的关键优化技巧,如选择合适的数据类型、SQL语句的最佳实践、主从复制与读写分离的应用,以及索引、分库分表(包括垂直和水平拆分)的策略,以提升系统性能和稳定性。
本文介绍了数据库设计中的关键优化技巧,如选择合适的数据类型、SQL语句的最佳实践、主从复制与读写分离的应用,以及索引、分库分表(包括垂直和水平拆分)的策略,以提升系统性能和稳定性。
表的设计优化(参考阿里开发手册《嵩山版》)
1.比如设置合适的数值(tinyint int bigint),要根据实际情况选择
2.比如设置合适的字符串类型(char和varchar) char定长效率高,varchar可变长度,效率稍低
SQL语句优化
1.SELECT语句务必指明字段名称(避免直接使用select * )
2.SQL语句要避免造成索引失效的写法
3.尽量用union all代替union union会多一次过滤,效率低
4.避免在where子句中对字段进行表达式操作
5.Join优化能用innerjoin就不用left join right join,如必须使用一定要以小表为驱动
内连接会对两个表进行优化,优先把小表放到外边,把大表放到里边。
left join或right join,不会重新调整顺序
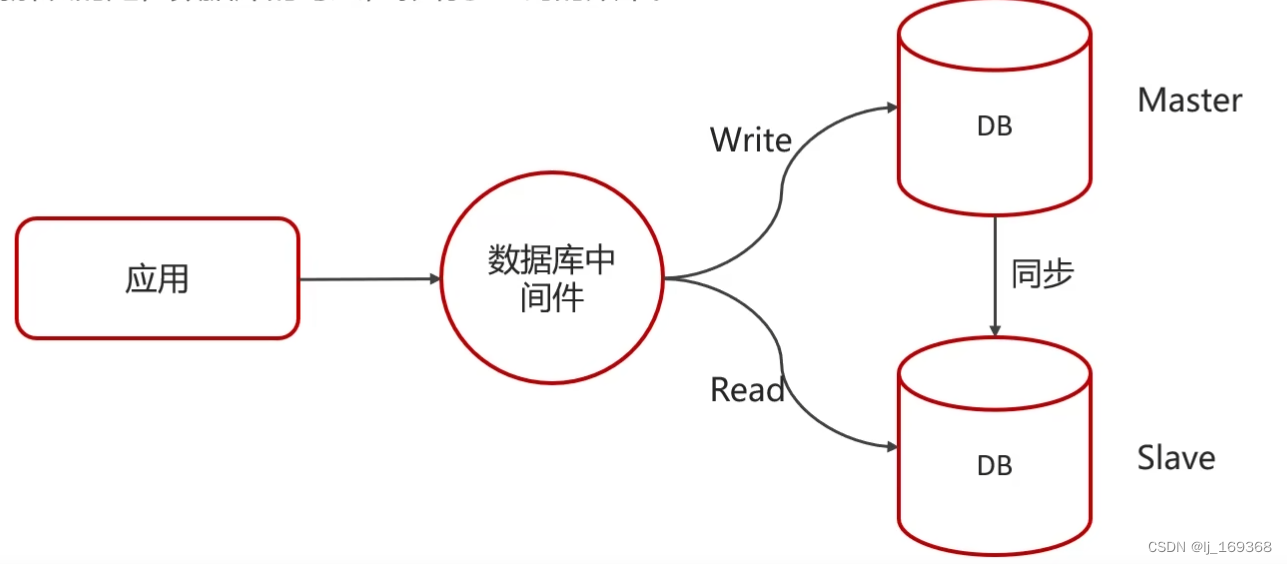
主从复制、读写分离
如果数据库的使用场景读的操作比较多的时候,为了避免写的操作所造成的性能影响可以采用读写分离的架构。读写分离解决的是,数据库的写入,影响了查询的效率。
索引优化
参考:MYSQL 聚集索引和二级索引、覆盖索引和超大分页处理、索引创建原则及索引失效情况
分库分表
分库分表的时机:
1,前提,项目业务数据逐渐增多,或业务发展比较迅速,单表的数据量达1000W或20G以后
2,优化已解决不了性能问题(主从读写分离、查询索引.….)
3. IO瓶颈(磁盘IO、网络IO)、CPU瓶颈(聚合查询、连接数太多)
垂直拆分
垂直分库:
以表为依据,根据业务 将不同表拆分到不同库中。
特点:
1.按业务对数据分级管理、维护、监控、扩展
2.在高并发下,提高磁盘IO和数据量连接数
垂直分表:
以字段为依据,根据字段属性将不同字段拆分到不同表中。
拆分规则:
1.把不常用的字段单独放在一张表
2.把text,blob等大字段拆分出来放在附表中
特点:
1,冷热数据分离
2,减少IO过渡争抢,两表互不影响
水平拆分
水平分库:
将一个库的数据拆分到多个库中。
路由规则
1.根据id节点取模
2.按id也就是范围路由,节点1(1-100万),节点2(100万-200万)
特点:
1.解决了单库大数量,高并发的性能瓶颈问题 2.提高了系统的稳定性和可用性
水平分表:
将一个表的数据拆分到多个表中(可以在同一个库内)。
特点:
1.优化单一表数据量过大而产生的性能问题;2.避免IO争抢并减少锁表的几率;
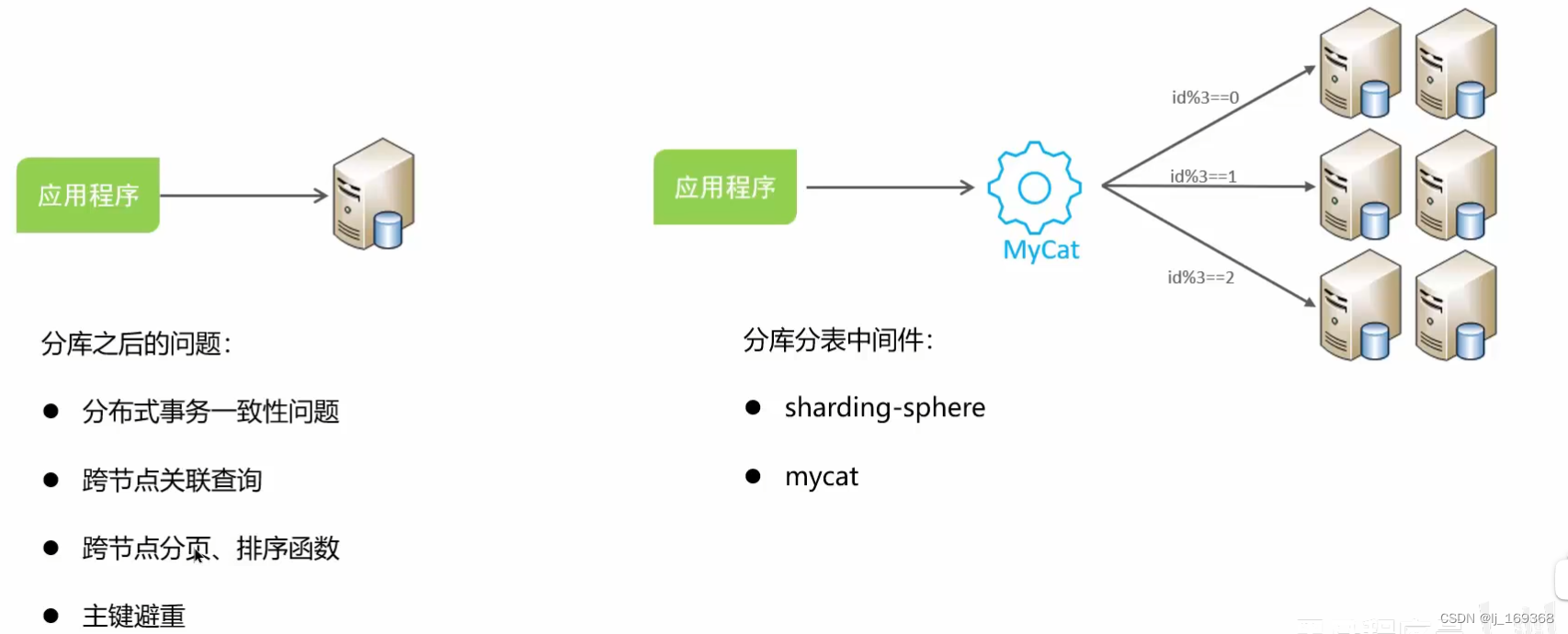
分库分表的策略















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









