






研究一下chunk locality 的问题。
主要最近在思考是不是可以把我们的global deduplication做的更好,看到了Ceph引用的一篇讲global data deduplication的文章[3],所以想把我对关于chunk locality方面的思考分享记录一下。
这篇文章结合了HP和Data Domain的两篇论文,想深度研究下chunk(segment) locality对于deduplicated数据的读写会有怎样的影响。
希望通过这篇文章弄明白几件事情:
1.主存储架构和备份存储的对数据locality的要求是否有区别,有什么区别
2.Chunk locality会怎么影响数据的读写(在不同的locality基础之上我们应该如何设计deduplication方案)
3.不同的Chunk locality适用于什么样的业务/存储架构
在读这篇文章之前,最好通读一下这三篇论文:[1][2][3]。
CEPH
我们就拿CEPH作为主存目标去分析一下它的locality,这里只讨论较大的object。
在它官方文档的Architecture->Ceph protocol章节里,我们可以看到它有一个Data striping 的描述:
Storage devices have throughput limitations, which impact performance and scalability. So storage systems often support striping--storing sequential pieces of information across multiple storage devices--to increase throughput and performance.
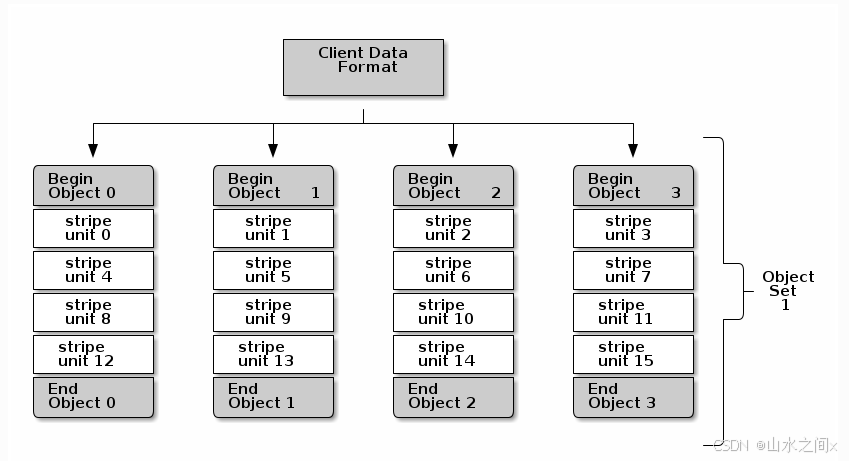
正如文中描述,这么做的原因是为了利用多个存储设备去增加吞吐能力和性能。
这个方法显然从理论上是可行的,因为RAID 0就用的类似的方法来提高的读写性能。
那这样的话,对于一个文件来说,假如他被切分成32个units, 这些units会被交叉且均匀的分配到不同的object上,之后所有的object通过CRUSH再sharding到不同的storage devices上。
我们在读这个文件时需要通过简单的计算去得到相应的offset的存储位置,这样实现了利用多个driver并发去读的功能。
总结一下:我们通过把数据的locality从一个顺序的线性排列变成一个非常均匀且分散的排列,从而提高throughput and performance。
看上去非常不错的方案,但我们看问题应该从全局角度出发,包括整个IO链路。
那么如果我们在后端加上去重功能会怎么样?
来看看官方文档中的引入的Depulication:Double hashing 详情参考【Design of Global Data Deduplication for A Scale-out Distributed Storage System】
简单来说这个design会将object再次切块,然后将切好的chunks利用CRUSH算法(chunk的fingerprint作为hash值)再sharding到相应的FG/OSD里。
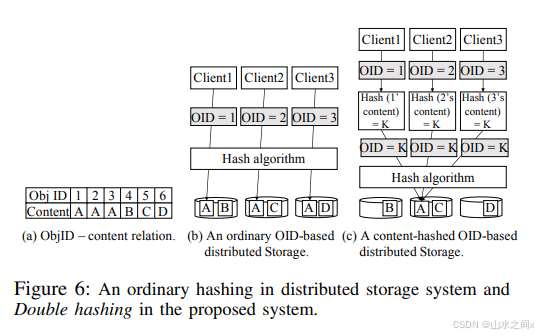
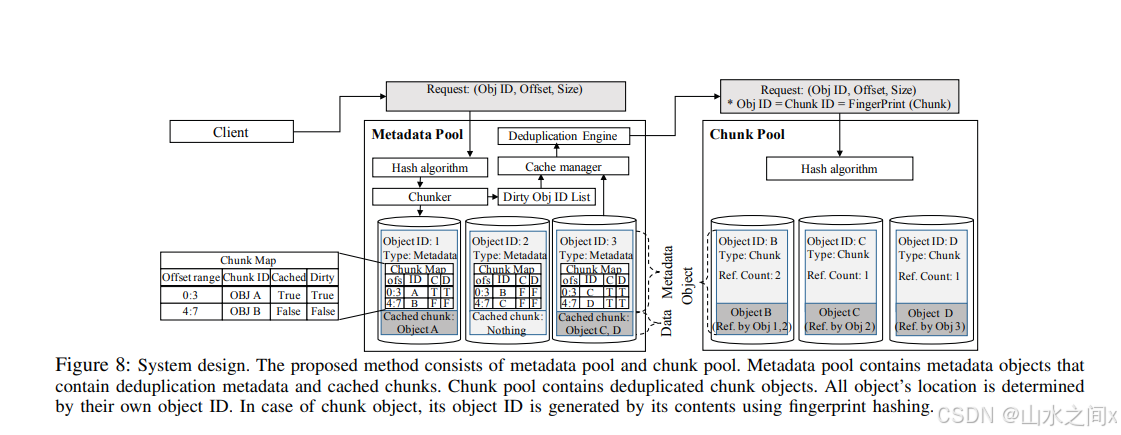
我截取了两个文章里的结构图,帮助理解上面的逻辑。
了解了以上逻辑,我们需要提出几个问题:
1.既然chunks又会sharding到不同的storage里,那开始的striping还有意义吗?
2.这种利用指纹把本应在同一manifest里的objects在进行chunk后,均匀的(理论上)sharding到不同的storage里,会带来什么问题?
3.这样的design会对deduplication带来什么优点和缺点?
其实第二个问题在论文中作者就给出了一些答案:
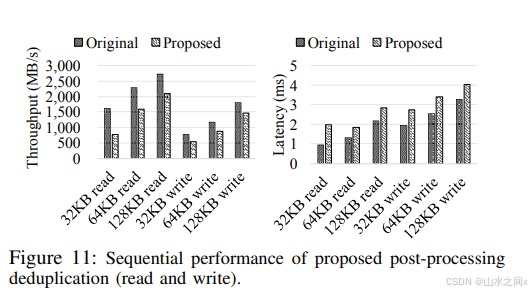
我贴出了作者给的读写性能对比以及原因分析:

我们对这个分析结论先不做判断,保留一下。
毕竟官方文档里也只是在说目前这个方案是实验性的:

但在这里我要先说一个观点:
对分布式系统,上面这种double-hash的设计可以通过简单的计算将fingerprint定位到某个节点上,然后做global deduplication,看上去是个很好的想法(我其实一度也以为这样很好啊,解决了data streaming backup 在cluster里的global deduplication的难题,而且还有striping的效果,我们的产品为什么不这样设计呢?)
但实际上,这样的design至少在备份存储场景里会带来非常严重的性能问题!
Chunk locality
现在引出我们今天要讨论的重点:locality的问题。
这里主要针对两个地方:
1.数据的manifest里的块引用位置的排列分布
2.chunk在container里的位置排列分布
我们要看一下备份行业是怎么做这个事情的,在很多backup stream deduplication的优化设计文章里,总会有一个章节讨论locality的事情,因为它对很多数据指标有很大影响,引用一下【Sparse Indexing: Large Scale, Inline Deduplication Using Sampling and Locality】里的一句话:
Both approaches degrade under conditions of poor chunk locality: with BFPFI, throughput degrades, whereas with sparse indexing, deduplication quality degrades
BFPFI: Bloom Filter with Paged Full Index
那我们思考一下为什么chunk locality不好会导致这些问题。
throughput degrades
对于Data Domain的BFPFI(Bloom Filter with Paged Full Index),这里简单介绍一下他提到的避免去重文件系统的磁盘瓶颈问题。
他针对这个问题提出了三个技术方案:
(1) the Summary Vector, a compact in-memory data structure for identifying new segments;
(2) Stream-Informed Segment Layout, a data layout method to improve on-disk locality for sequentially accessed segments;
(3) Locality Preserved Caching, which maintains the locality of the fingerprints of duplicate segments to achieve high cache hit ratios
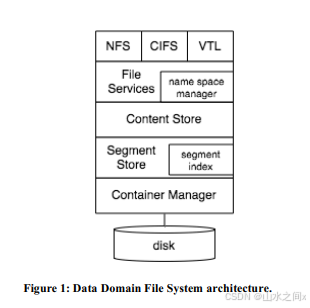
具体的细节感兴趣的可以去看原文,这三个方案一起应用的效果是减少了99%的磁盘访问针对于真实场景中的workload,高效的提高了磁盘throughput的能力。
这是三个优化方案一起工作的流程:
We have combined all three techniques above in the segment filtering phase of our implementation. For an incoming segment for write, the algorithm does the following:
• Checks to see if it is in the segment cache. If it is in the cache, the incoming segment is a duplicate.
• If it is not in the segment cache, check the Summary Vector. If it is not in the Summary Vector, the segment is new. Write the new segment into the current container.
• If it is in the Summary Vector, lookup the segment index for its container Id. If it is in the index, the incoming segment is a duplicate; insert the metadata section of the container into the segment cache. If the segment cache is full, remove the metadata section of the least recently used container first.
• If it is not in the segment index, the segment is new. Write the new segment into the current container.
这几个优化是和chunk locality息息相关的。
我们先看(2),这里说我们在将数据进行container存储时要按照数据流原始的数据进行顺序存储。而不是向我们在Ceph里看到的是要利用fingerprint做sharding。
原因是这样我们可以让container里的数据来自一个原始数据流,那他的metadata也是集中包含在这个container里的。
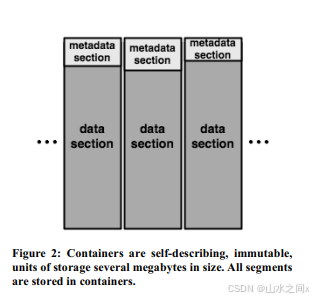
如果我们在BFPFI(1)里检测到存在,我们就需要去访问the segment index,查一查fingerprint是否存在,这里肯定是需要访问磁盘的(这里似乎和locality没什么关系的)。
Locality Preserved Caching说的是他会缓存整个container ID fingerprints,他的理论依据是:
we apply LPC to take advantage of segment duplicate locality so that if a segment is a duplicate, the base segment is highly likely cached already
那这里是说(2)加载的container 里的fingerprints是有更大概率被去重的。如果container里的locality不好,那这个功能就大打折扣了。对于那些在缓存里没有命中的我们得去对应的container ID去加载它里面的fingerprints, 如果container里的locality很差,就会有频繁的磁盘页换进内存,引起throughput降级问题。
对于备份场景,往往是大数据量,前后重复率非常高的数据流,这样如果按照fingerprint sharding的方式去存chunk,问题就非常明显了,会有大量的页换进换出,大量的磁盘访问。
deduplication quality degrades
对于Sparse Indexing,他对于locality的依赖就比较明显了。
他是通过把全局的fingerprint进行一定比例(128:1)的sampling插入到sparse index里,之后我们把新来的segment到sparse index里进行匹配,如果找到了符合条件的manifest,把他作为champins'候选人再进行排序筛选最优解,最终找到一个指纹集合进行去重。
这里的去重效果就依赖于manifest(segment)的locality,毕竟sparse index能加载的manifest是有限制的,到达上限时就需要LRU去做换进换出,如果segment存的chunk是分散的那我们会消耗很多磁盘访问,最重要的是去重效果会变差。毕竟我们能加载的champins也是有限制的。
我们要知道的是HP这个方案里是没有类似上文中segment index一样的full chunk index的,所以去重效果好坏全靠the Sparse Index。
我们的产品在实现从Full chunk index 转型为samping index时也用了类似的方法优化的FP cache使用大量内存的问题。
Global deduplication vs chunk locality
经过上面的讨论我们可以发现,如果你想吧global deduplication over multiple nodes 做的好的话,chunk locality就会比较差,因为你的manifest可能会大量引用其他节点的chunk,那你就需要在读一个segment时需要大量的节点间通讯,letency会变高和节点间throughput会被浪费。
但是呢,global deduplication又不能不做,否则去重效果就会不好。
这个问题在我们的产品后端存储支持对象存储(Cloud)后,就更加明显了:
locality不好的话,整体读container就浪费流量,做partial read的话,IO Requests就会变多。这都是钱啊!!!
所以我们需要一个平衡,在locality和deduplication quality之间的平衡。
Throughput
Object的chunks都顺序存储在单个container里,这样做是不是就不能利用多个disk driver并发读写的能力?
这个问题其实不能这么单一的看,要结合整条IO路径
1.对于一些企业级的备份存储产品(比如NBU,Netbackup)它后端是不可能简单的用单块磁盘做存储介质的,后端基本都会是RAID,从软件到硬件,其实都是有整体安排的,比如我们就可以通过RAID完成数据高可用(EC)、数据striping的功能。
2.即使对于想Ceph这种开源软件,利用OSD优化对磁盘driver的使用,在之前版本的File Store,也是建立在文件系统之上的,随着磁盘虚拟化的功能,你是要分清楚你的逻辑磁盘和物理磁盘是否是一一对应的,硬件上是不是独立的。
Improvement
随着数据的不断更新,我们的container因为过多的引用,它的locality会变得越来越差,下面提出几种方法来提高相关性能:
1.减少或者不引用那些garbage rate很高的container(useless data size/whole container size>75%)里的数据块。
2.限制单个container被引用的次数,比如一个container不能被超过200个object引用。
3.对于后端存储是cloud(object storage), 且manifest 引用的container的locality特别差的,我看可以采用partial read去优化读带宽。
前两点是牺牲一些dedup rate来提高locality的方法,最终可以使没有引用的数据可以尽快被删掉,节省空间。
对于第三点可以详细介绍下:
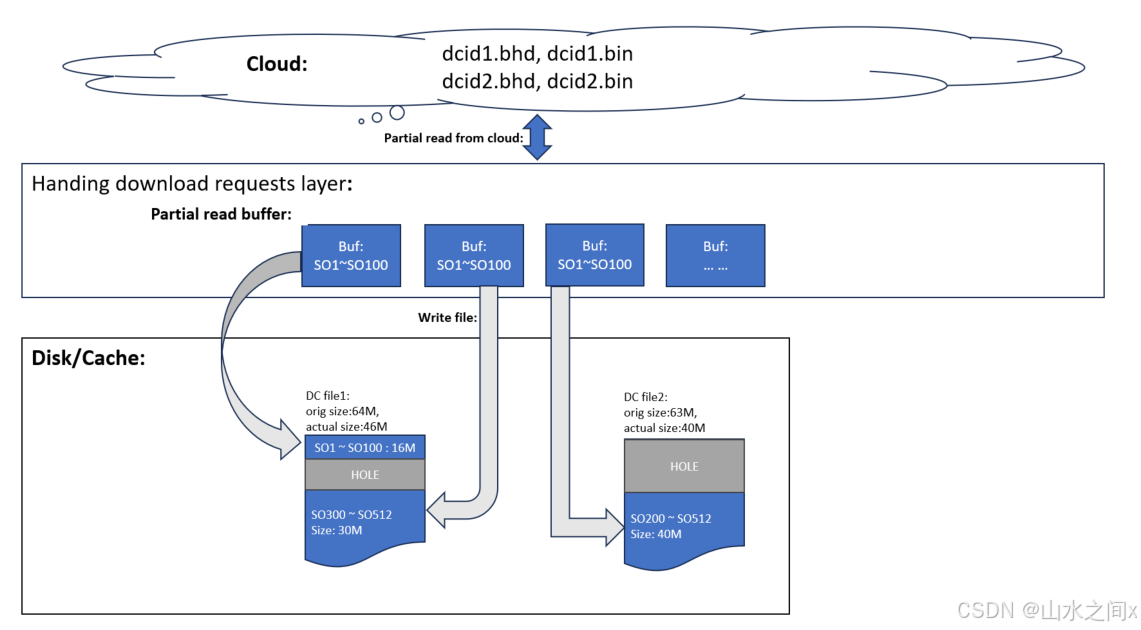
我们正常情况下会预下载一些后面要用的container(系统瓶颈不在从cloud下载),就会需要一个cache去缓存这些pre-download的container,对于那些有用数据占比很小的data container,我们是不希望下载全部数据的(浪费了时间和钱),如果使用partial read的话就可以读取我们需要的部分,那pre-download又怎么实现呢?利用file hole, 我们把需要的数据预下载到文件的指定位置上,如果有其他并发的读想下载这个container其它的数据,只需要把下载数据填充到对应的file offset处就可以了,下面给出一个读数据的处理流程图。
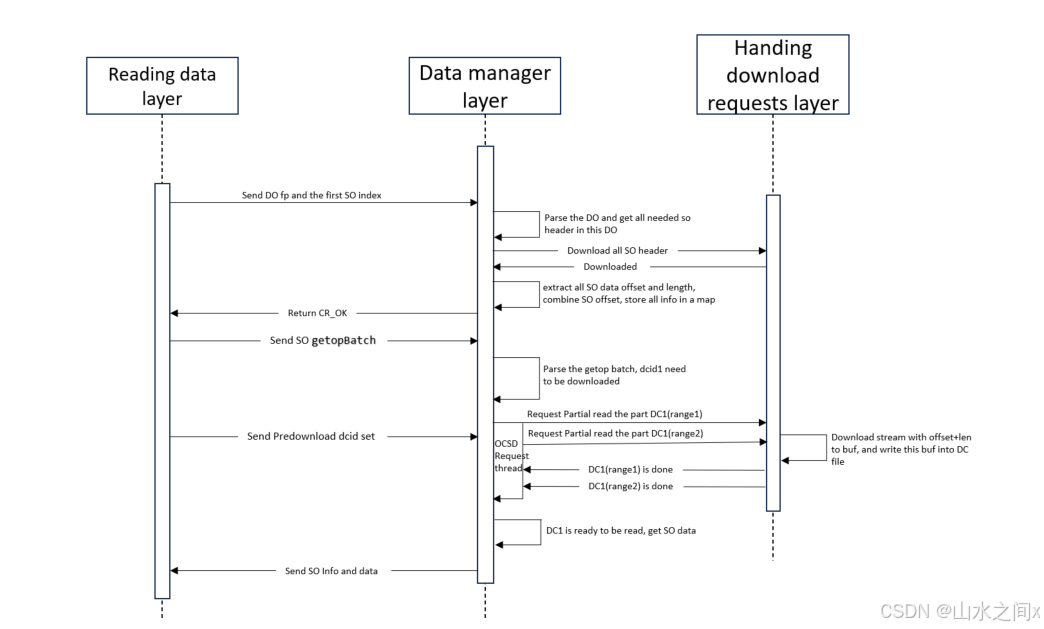
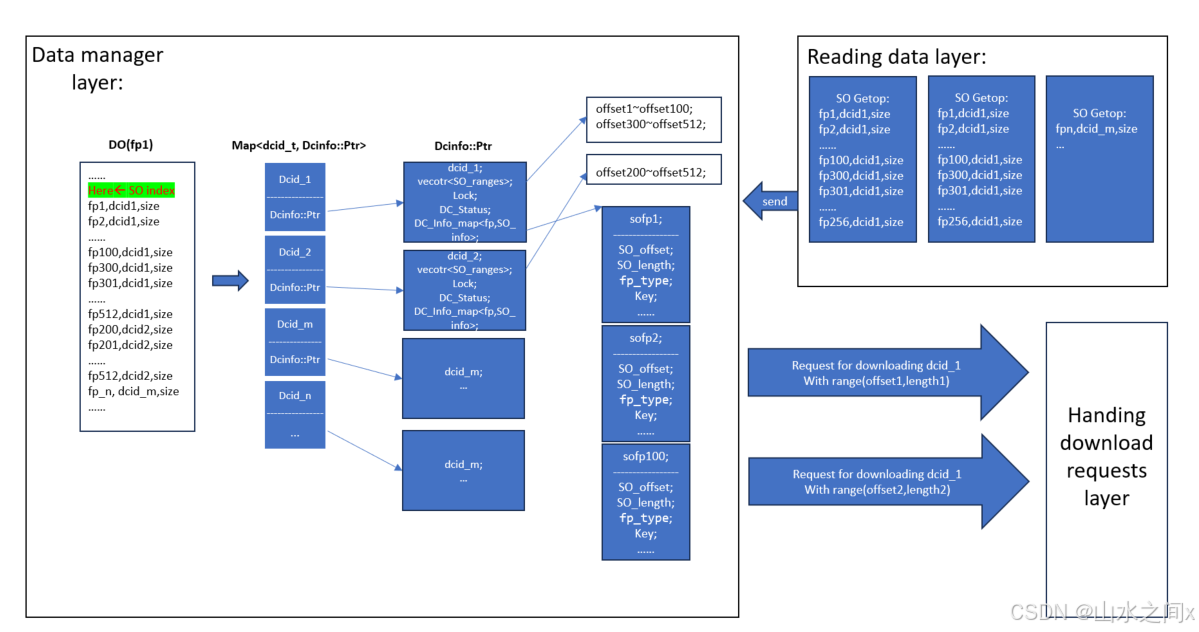
结论
讨论这些并不想证明哪个design是对的,哪个是错的。只是想帮助自己理解locality在数据存储中的重要性。
不同的业务逻辑,不同的产品设计会引起不同的问题,有些事情我们不能一概而论,其中的复杂性,是需要深度思考才能更好理解的。
Chunk Locality是贯彻并且内嵌在存储IO路径里的, 设计上我们必须仔细研究,一旦确定了方案,再发现问题,很有可能会给你一个大的surprise!
如果您发现文章中有任何问题或不足之处,欢迎讨论!
引用
- Benjamin Zhu, Kai Li, R. Hugo Patterson: Avoiding the Disk Bottleneck in the Data Domain Deduplication File System. FAST 2008: 269-282
- Mark Lillibridge, Kave Eshghi, Deepavali Bhagwat, Vinay Deolalikar, Greg Trezis, Peter Camble: Sparse Indexing: Large Scale, Inline Deduplication Using Sampling and Locality. FAST 2009: 111-123
- M. Oh, S. Park, J. Yoon, S. Kim, K.-w. Lee, S. Weil, H. Y. Yeom, and M. Jung. Design of global data deduplication for a scale-out distributed storage system. In IEEE 38th International Conference on Distributed Computing Systems (ICDCS), pages 1063–1073, 2018.
- Architecture — Ceph Documentation

















 1427
1427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









