






适用平台:Matlab2021及以上
一、摘要
2025年5月即将发表于SCI一区顶级期刊《Applied Soft Computing》提出了一种优化算法一键改进方法!!!论文提出了一种名为思维创新策略(TIS)的新机制,用于改进元启发式算法。TIS的灵感来源于人类的创新思维过程,通过模拟个体的知识深度和想象力来平衡算法的探索与开发能力。在57个工程问题和IEEE CEC2020基准测试上验证了TIS的有效性,显著提升了多种算法的性能。创新性极强非常简单且,目前还未有利用该改进策略的论文,赶紧码住!

二、创新点
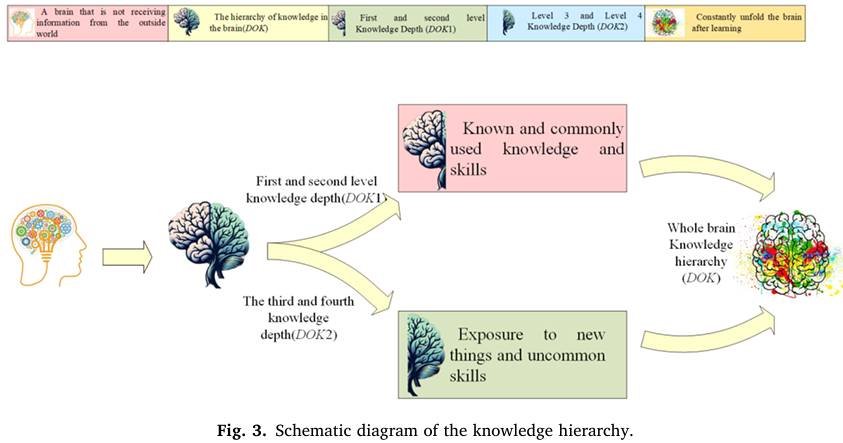
①知识深度模型(DOK Model)• DOK1 表示常规经验知识,由常数 和进化代数占比的平方根组成,反映算法早期快速积累经验。
• DOK2 为创新知识,通过 放大迭代次数的影响,后期主导搜索方向。
• 总知识深度 是两者的加权和,实现经验继承与创新突破的平衡。
• 通俗比喻:
好比学生解题:DOK1是课本知识(随时间稳步增长),DOK2是竞赛经验(后期爆发式提升),两者结合形成解题能力,多策略结合!
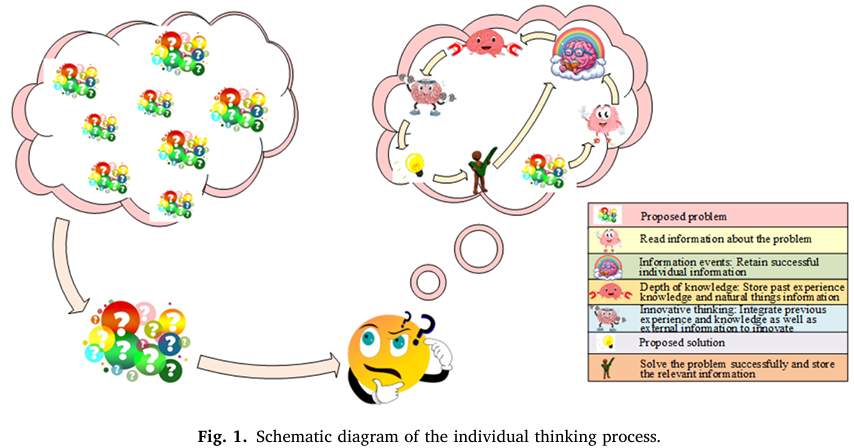
②想象力驱动算子(IM Operator)
• IE 为信息事件库中的优质解, 引入随机扰动。•Π是放大系数,确保扰动幅度与问题规模适配。
主要作用:在已有优质解(IE)基础上,通过随机扰动(rand)探索周边区域,类似科学家在已知方案附近尝试改进。
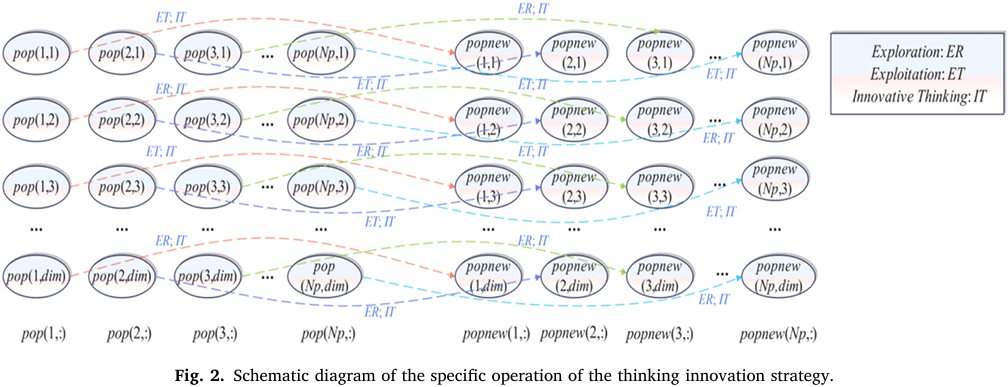
③思维跃迁方程(Innovation Equation)
• 函数将输入映射到 ,增强搜索方向多样性。
• 表示基于知识深度对当前位置的修正,经验越深修正越小。
• 引导向历史优质解方向搜索。
类似导航系统: 提供方向探索(如尝试新路径), 是已知最优路线, 调节两者权重(新手多探索,老手多依赖经验)。
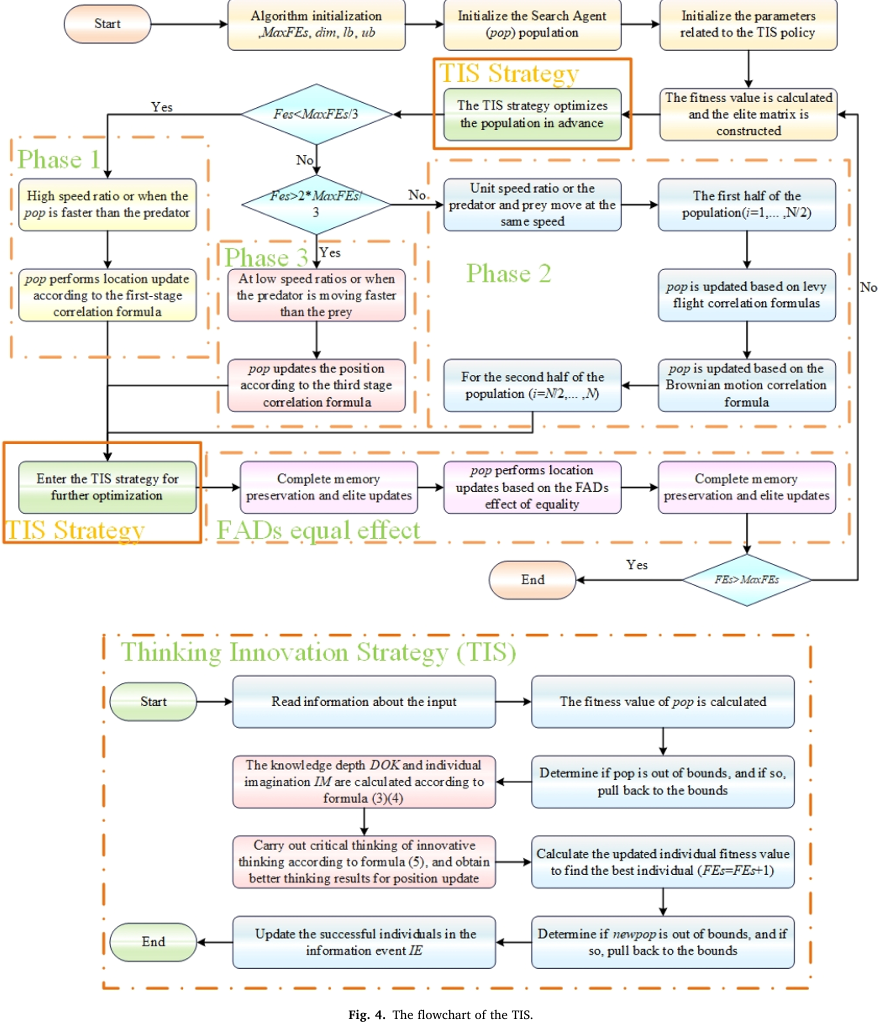
④信息事件更新机制(IE Update)
该机制通过动态保留历史优质解来指导搜索方向,其更新规则为:
动态保留历代最优解,形成经验库,指导后续搜索方向,类似棋手记忆经典棋局(IE),遇到相似局面时快速调用,但遇到新棋局时更新记忆库。
⑤自适应越界处理(Boundary Control)
镜像反弹策略:若 ,则修正为:避免直接截断导致的梯度信息损失,保持解的空间连续性。 类似光线射到镜面反射,既能保证不越界,又能保留运动方向信息。
⑥约束协同处理(Constraint Handling)自适应惩罚函数:其中 动态调整惩罚系数 ,早期允许轻度违约束( 较小),后期严格惩罚( 增大)。类似"先粗筛后精修":先粗略探索大范围,后期聚焦可行域。
关键改进总结表
| 改进模块 | 核心公式 | 学术贡献 | 工程意义 |
|---|---|---|---|
| 知识深度模型 | 公式 (1)-(3) | 量化经验与创新的动态交互 | 平衡算法探索与开发 |
| 想象力驱动 | 公式 (4) | 引入可控随机扰动 | 避免早熟收敛 |
| 思维跃迁方程 | 公式 (5) | 非线性映射增强搜索多样性 | 提升高维问题求解效率 |
| 自适应约束处理 | 动态惩罚系数 | 无需人工设置惩罚权重 | 自动适配复杂约束场景 |
| 镜像越界修正 | 反弹公式 | 保持解空间连续性 | 提高边界附近搜索精度 |
上述方法使得TIS既保留了数学严谨性(如DOK模型的可微性证明),又通过动态机制(如IE更新)适配工程实际需求,实用性非常强,真正做到即插即用!
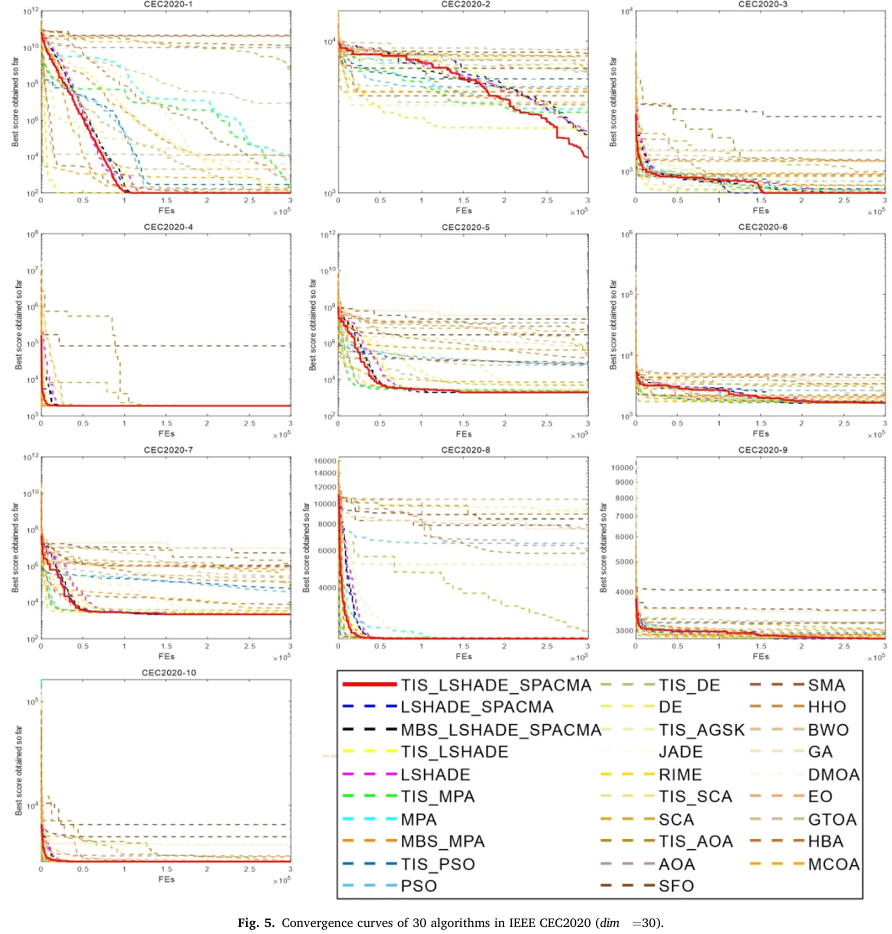
三、程序结果
四、 程序获取
关注公众号,私信发送:TIS 免费获取
往期推荐


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









