






你有没有想过,用人工智能来研究动物世界?比如,让一台计算机学会分辨不同种类的猴子。听起来很酷对吧?今天,我们将带你进入一个有趣的深度学习实验:使用卷积神经网络(CNN)实现猴子种类的精准分类。
从零开始,我们不仅会教你如何设计神经网络,还会利用数据增强技术来扩展数据集,提升模型的泛化能力。更令人激动的是,我们还可以用实时摄像头捕获画面,看看你的模型能否分辨出屏幕中的猴子种类!即使是人工智能的初学者,也能通过这个项目轻松入门。
准备好了吗?让我们一起解锁这项“猴”大的挑战吧! 🐵✨
项目背景
使用卷积神经网络(CNN)对猴子种类进行分类任务。通过数据增强技术,提升泛化能力,成功在特定图片和摄像头画面中实现分类预测。
1. 数据增强的重要性
为了提高模型的泛化能力,我们引入数据增强技术。在训练集中,通过对原始图片的尺寸调整、随机翻转、亮度调整等操作,生成了更多样化的图片数据,缓解了数据量不足的问题。
2. 数据加载与增强
原始数据和增强数据路径(改成你自己的数据集路径):原始数据路径:E:\Desktop\实验六\Monkeys
增强数据路径:E:\Desktop\实验六\DA_Monkeys
from torchvision import datasets, transforms
from torch.utils.data import ConcatDataset
transform = transforms.Compose([
transforms.Resize((160, 160)),
transforms.ToTensor(),
])
original_dataset = datasets.ImageFolder(root=original_data_dir, transform=transform)
augmented_dataset = datasets.ImageFolder(root=augmented_data_dir, transform=transform)
combined_dataset = ConcatDataset([original_dataset, augmented_dataset])
增强完的数据: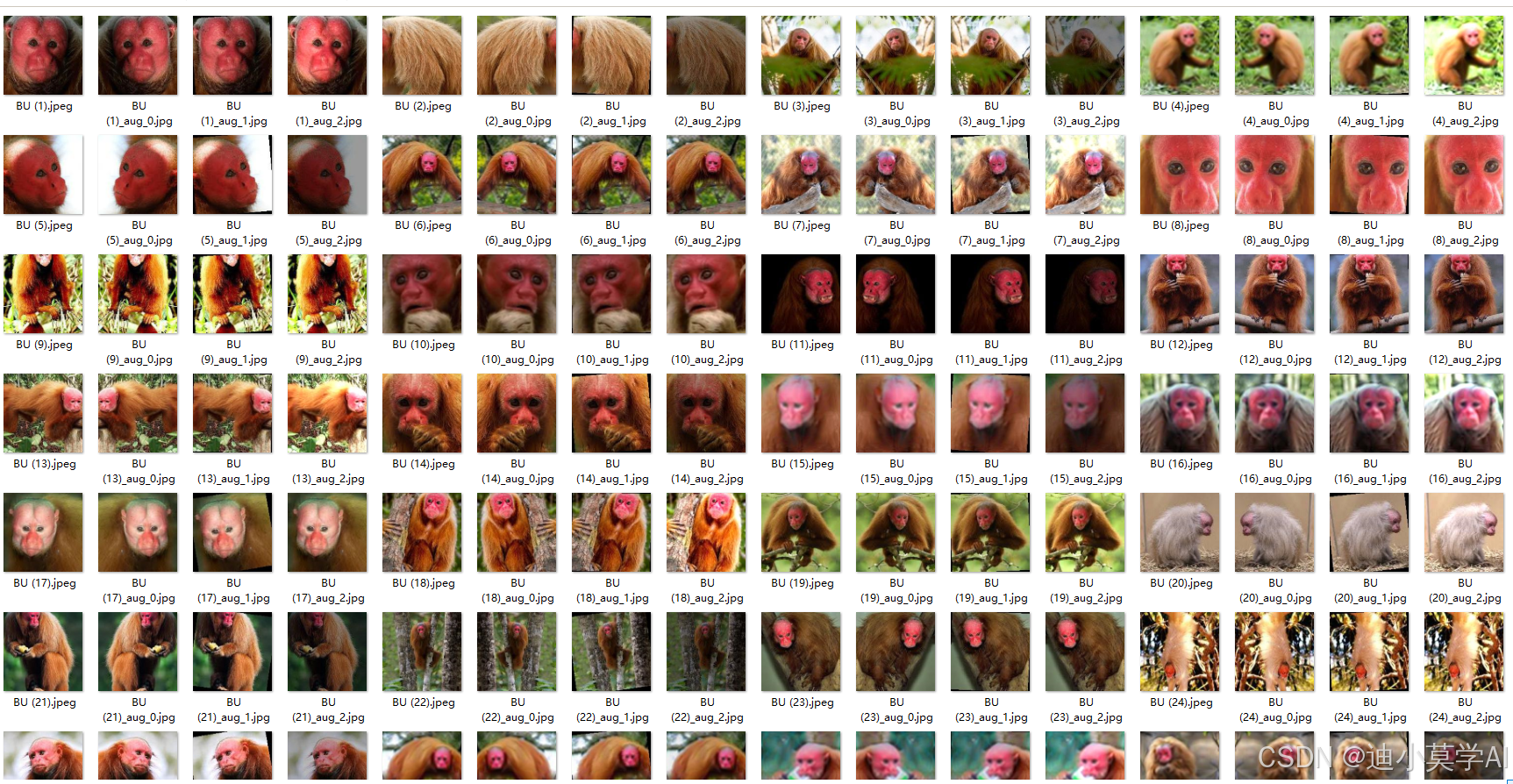
数据划分与加载
我们将数据集划分为 80% 的训练集和 20% 的测试集,并使用 DataLoader 加载数据:
from torch.utils.data import DataLoader
train_size = int(0.8 * len(combined_dataset))
test_size = len(combined_dataset) - train_size
train_data, test_data = torch.utils.data.random_split(combined_dataset, [train_size, test_size])
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
test_loader = DataLoader(test_data, batch_size=32, shuffle=True)模型设计
1. 网络结构
设计一个的卷积神经网络模型,包括两层卷积层、最大池化层和批归一化层,以及三层全连接层。最后输出层使用 Softmax 激活函数实现分类。
模型的定义如下:
import torch.nn as nn
class MonNet(nn.Module):
def __init__(self):
super(MonNet, self).__init__()
# 卷积层 1:输入通道 3(RGB 图像),输出通道 6,卷积核大小 5x5
self.conv1 = nn.Conv2d(3, 6, kernel_size=(5, 5), padding=0)
# 批归一化 1:对通道数为 6 的特征进行归一化
self.bn1 = nn.BatchNorm2d(6)
# 最大池化层 1:池化窗口大小为 6x6
self.maxpool1 = nn.MaxPool2d(6)
# ReLU 激活函数
self.relu = nn.ReLU()
# 卷积层 2:输入通道 6,输出通道 16,卷积核大小 5x5,带 padding
self.conv2 = nn.Conv2d(6, 16, kernel_size=(5, 5), padding=5)
# 批归一化 2:对通道数为 16 的特征进行归一化
self.bn2 = nn.BatchNorm2d(16)
# 全连接层 1:16 x 5 x 5 的特征映射到 120 个神经元
self.fc1 = nn.Linear(16 * 5 * 5, 120)
# 全连接层 2:120 个神经元映射到 84 个神经元
self.fc2 = nn.Linear(120, 84)
# 全连接层 3:84 个神经元映射到 5 个类别(对应猴子的分类)
self.fc3 = nn.Linear(84, 5)
# Softmax 激活函数:输出类别的概率分布
self.sf1 = nn.Softmax(dim=1)
def forward(self, x):
# 第一层卷积 -> ReLU -> 最大池化
x = self.relu(self.conv1(x))
x = self.maxpool1(x)
# 第二层卷积 -> ReLU -> 最大池化
x = self.relu(self.conv2(x))
x = self.maxpool1(x)
# 展平特征图,准备进入全连接层
x = x.view(-1, 16 * 5 * 5)
# 全连接层 1 -> ReLU
x = self.relu(self.fc1(x))
# 全连接层 2 -> ReLU
x = self.relu(self.fc2(x))
# 全连接层 3 -> Softmax
y = self.sf1(self.fc3(x))
return y
-
卷积层(Convolutional Layer):
self.conv1和self.conv2是卷积操作,用于提取图像的低级特征(如边缘、纹理)。- 参数:
in_channels: 输入通道数(如 RGB 图像为 3)。out_channels: 输出通道数(卷积核的个数)。kernel_size: 卷积核的大小(如 5x5)。padding: 在图像边界添加零填充,保持特征图尺寸。
-
批归一化(Batch Normalization):
self.bn1和self.bn2对卷积输出进行归一化,稳定训练过程并加速收敛。
-
最大池化层(MaxPooling Layer):
self.maxpool1用于降维,减小特征图的大小,同时保留重要信息。
-
全连接层(Fully Connected Layer):
self.fc1、self.fc2和self.fc3将卷积提取的特征映射到分类结果。- 参数:
in_features: 输入神经元的数量。out_features: 输出神经元的数量。
-
激活函数(Activation Function):
self.relu:ReLU(Rectified Linear Unit)激活函数,用于引入非线性。self.sf1:Softmax 激活函数,将网络输出转化为概率分布。
-
前向传播(Forward Pass):
forward方法定义了数据流经网络的路径:- 输入图像通过卷积层提取特征。
- 池化层对特征降维。
- 展平成一维后,通过全连接层映射到分类空间。
- 最终输出类别概率。
2.输出示例
假设输入图像尺寸为 (3, 160, 160):
- 经过
conv1和maxpool1:- 输出尺寸:
(6, 26, 26)
- 输出尺寸:
- 经过
conv2和maxpool2:- 输出尺寸:
(16, 5, 5)
- 输出尺寸:
- 展平成一维后:
- 特征维度:
(16 * 5 * 5 = 400)
- 特征维度:
- 最终经过全连接层:
- 输出维度:
(5)(对应 5 个类别)。
- 输出维度:
训练与优化
1. 损失函数与优化器
选择 交叉熵损失函数(CrossEntropyLoss)和 Adam 优化器。Adam 优化器以其快速收敛性能和稳定性,适合处理分类问题。
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
2. 模型训练
训练了 50 个 epoch,每个 epoch 中:
- 计算训练集的损失(Loss)和准确率(Accuracy)。
- 保存模型检查点,记录损失和准确率变化。
训练代码如下:
for epoch in range(start_epoch, num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
correct += (predicted == labels).sum().item()
total += labels.size(0)
epoch_loss = running_loss / len(train_loader)
epoch_accuracy = correct / total
train_losses.append(epoch_loss)
train_accuracies.append(epoch_accuracy)
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_accuracy:.4f}")
模型性能展示
1. 文件分类结果
对特定图片文件进行分类的预测结果展示:
from PIL import Image
def predict_image(image):
image = transform(image).unsqueeze(0) # 增加 batch 维度
with torch.no_grad():
output = model(image)
_, predicted = torch.max(output, 1)
return predicted.item()
image = Image.open(r'E:\Desktop\实验六\DA_Monkeys\White face saki\WFS (13)_aug_0.jpg').convert('RGB')
class_idx = predict_image(image)
print(f"Predicted Class: {class_idx}")
2. 实时摄像头分类结果
实时捕获画面,并预测分类结果:
import cv2
def predict_from_camera():
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
cv2.imshow('Press "q" to capture and classify', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image = Image.fromarray(image)
class_idx = predict_image(image)
print(f"Predicted Class: {class_idx}")
break
cap.release()
cv2.destroyAllWindows()
实验总结
1. 实验成果
在训练 50 个 epoch 后,模型的测试集准确率达到 97.8%。
数据增强手段显著提升了模型的泛化能力。
2. 改进空间
种类映射:将分类索引(如 0, 1)映射到实际猴子种类名称,便于结果解释。
优化实时摄像头预测:加入图像预处理,如背景过滤或边框检测,进一步提升实时预测性能。
源码地址
完整项目源码已开源,欢迎克隆测试:
git clone https://gitee.com/songaoxiangsoar/monkey-classification.git
如果本项目对您有所帮助,欢迎点赞、评论或分享! 🐒✨


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









