









K Nearest Neighbor算法
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法。其中的K表示最接近自己的K个数据样本。KNN算法和K-Means算法不同的是,K-Means算法用来聚类,用来判断哪些东西是一个比较相近的类型,而KNN算法是用来做归类的,也就是说,有一个样本空间里的样本分成很几个类型,然后,给定一个待分类的数据,通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。你可以简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
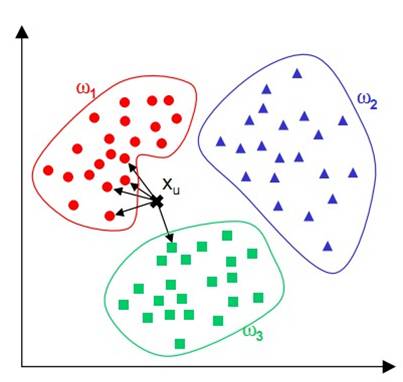
根据距离函数计算待分类样本X和每个训练样本的距离(作为相似度),选择与待分类样本距离最小的K个样本作为X的K个最邻近,最后以X的K个最邻近中的大多数所属的类别作为X的类别。KNN可以说是一种最直接的用来分类未知数据的方法。
简单来说,KNN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑出离这个数据最近的K个点,看看这K个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
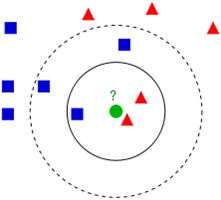
从上图中我们可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
源码
package org.bigdata.mapreduce.knn;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.bigdata.util.DistanceUtil;
import org.bigdata.util.HadoopCfg;
import org.bigdata.util.HadoopUtil;
public class KNNMapReduce {
public static final String POINTS = "knn-test.txt";
public static final int K = 3;
public static final int TYPES = 3;
private static final String JOB_NAME = "knn";
// train-points
private static List<Point> trans_points = new ArrayList<>();
public static void initPoints(String pathin, String filename)
throws IOException {
List<String> lines = HadoopUtil.lslFile(pathin, filename);
for (String line : lines) {
trans_points.add(new Point(line));
}
}
public static class KNNMapper extends
Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName();
if (POINTS.equals(fileName)) {
Point point1 = new Point(value.toString());
try {
for (Point point2 : trans_points) {
double dis = DistanceUtil.getEuclideanDisc(
point1.getV(), point2.getV());
context.write(new Text(point1.toString()), new Text(
point2.getType() + ":" + dis));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
public static class KNNReducer extends
Reducer<Text, Text, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
List<DistanceType> list = new ArrayList<>();
for (Text value : values) {
list.add(new DistanceType(value.toString()));
}
Collections.sort(list);
int cnt[] = new int[TYPES + 1];
for (int i = 0, len = cnt.length; i < len; i++) {
cnt[i] = 0;
}
for (int i = 0; i < K; i++) {
cnt[list.get(i).getType()]++;
}
int type = 0;
int maxx = Integer.MIN_VALUE;
for (int i = 1; i <= TYPES; i++) {
if (cnt[i] > maxx) {
maxx = cnt[i];
type = i;
}
}
context.write(key, new IntWritable(type));
}
}
public static void solve(String pointin, String pathout)
throws ClassNotFoundException, InterruptedException {
try {
Configuration cfg = HadoopCfg.getConfiguration();
Job job = Job.getInstance(cfg);
job.setJobName(JOB_NAME);
job.setJarByClass(KNNMapReduce.class);
// mapper
job.setMapperClass(KNNMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// reducer
job.setReducerClass(KNNReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(pointin));
FileOutputFormat.setOutputPath(job, new Path(pathout));
job.waitForCompletion(true);
} catch (IllegalStateException | IllegalArgumentException | IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws ClassNotFoundException,
InterruptedException, IOException {
initPoints("/knn", "knn-train.txt");
solve("/knn", "/knn_out");
}
}
package org.bigdata.mapreduce.knn;
public class DistanceType implements Comparable<DistanceType> {
private double distance;
private int type;
public double getDistance() {
return distance;
}
public void setDistance(double distance) {
this.distance = distance;
}
public int getType() {
return type;
}
public void setType(int type) {
this.type = type;
}
public DistanceType(String s) {
super();
String terms[] = s.split(":");
this.type = Integer.valueOf(terms[0]);
this.distance = Double.valueOf(terms[1]);
}
@Override
public int compareTo(DistanceType o) {
return this.getDistance() > o.getDistance() ? 1 : -1;
}
@Override
public String toString() {
return "DistanceType [distance=" + distance + ", type=" + type + "]";
}
}
package org.bigdata.mapreduce.knn;
import java.util.Vector;
public class Point {
private int type;
private String strpoint;
private Vector<Double> v = new Vector<>();
public int getType() {
return type;
}
public void setType(int type) {
this.type = type;
}
public Vector<Double> getV() {
return v;
}
public void setV(Vector<Double> v) {
this.v = v;
}
public Point(String s) {
super();
this.strpoint=s;
String terms[]=s.split(" ");
for(int i=0,len=terms.length;i<len-1;i++){
this.v.add(Double.valueOf(terms[i]));
}
this.type=Integer.valueOf(terms[terms.length-1]);
}
public Point() {
super();
}
@Override
public String toString() {
return this.strpoint;
}
}
输入
1.0 2.0 3.0 1
1.0 2.1 3.1 1
0.9 2.2 2.9 1
3.4 6.7 8.9 2
3.0 7.0 8.7 2
3.3 6.9 8.8 2
2.5 3.3 10.0 3
2.4 2.9 8.0 32.1 5.5 7.2 0
1.1 2.5 4.2 0
4.1 3.5 9.2 0
















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









