




0.摘要
在matplotlib绘图过程中,中文的标题或者轴标中如果含有中文,会出现不能正常显示的问题。
本文主要介绍在Windows系统下,matplotlib库中的中文字体显示方法和相关配置。
1.全局设置
#!/usr/bin/python
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
x = np.linspace(-10,10,200)
y = x
plt.plot(x,y)
# 设置matplotlib正常显示中文和负号
matplotlib.rcParams['font.sans-serif']=['SimHei'] # 用黑体显示中文
matplotlib.rcParams['axes.unicode_minus']=False # 正常显示负号
plt.xlabel("横轴/单位")
plt.ylabel("纵轴/单位")
plt.title("标题")
plt.show()该方法具有全局作用范围,会将所有字体设置为黑体。因此,如果不加入下面这一句,会导致负号无法显示:
matplotlib.rcParams['axes.unicode_minus']=False
2.局部设置
如果希望对图表中不同部分采用个性化的设置方案,可以使用FontProperties设置方法。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
x = np.linspace(-10,10,200)
y = x
plt.plot(x,y)
font1 = FontProperties(fname=r"c:\windows\fonts\simsun.ttc")
font2 = FontProperties(fname=r"c:\windows\fonts\STHUPO.TTF")
font3 = FontProperties(fname=r"c:\windows\fonts\STCAIYUN.TTF")
plt.xlabel("横轴/单位",fontproperties=font1)
plt.ylabel("纵轴/单位",fontproperties=font2)
plt.title("标题",fontproperties=font3)
plt.show()这里的字体来自于系统,因此字体形式更加丰富,但是需要找到字体存放的路径,Windows下的默认路径为:C:\Windows\Fonts。由于Windows的文件系统并不区分大小写,因此这里对大小写问题不需要过多留意。
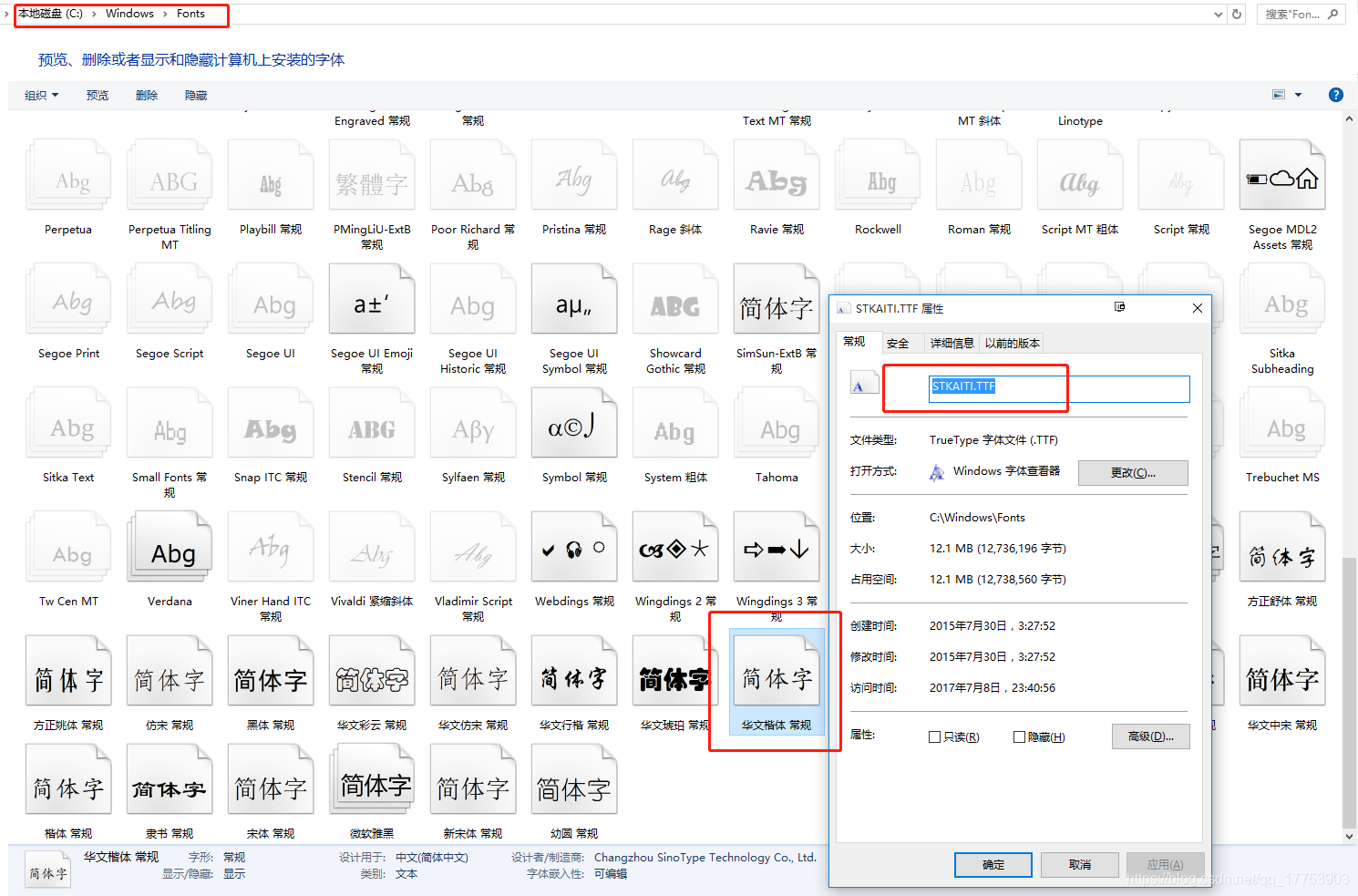
这里介绍一下Windows系统字体名称的查看方法:
step1:进入目录C:\Windows\Fonts
step2:点击相应字体-->属性
3.通过fontproperties参数设定
上一种方法虽然能够实现个性化的配置,并且不会影响全局字体环境,但配置步骤相对繁琐,这里介绍一种更为简单的方法:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
x = np.linspace(-10,10,200)
y = x
plt.plot(x,y)
plt.xlabel("横轴/单位",fontproperties="STLiti")
plt.ylabel("纵轴/单位",fontproperties="STXingkai")
plt.title("标题",fontproperties="STXinwei")
plt.show()
matplotlib.matplotlib_fname()其中,fontproperties后跟字体名称,字体中英文名称对应关系见下表:
| 字体 | 字体名 |
| 黑体 | SimHei |
| 楷体 | KaiTi |
| 隶书 | LiSu |
| 幼圆 | YouYuan |
| 华文细黑 | STXihei |
| 华文楷体 | STKaiti |
| 华文宋体 | STSong |
| 华文中宋 | STZhongsong |
| 华文仿宋 | STFangsong |
| 方正舒体 | FZShuTi |
| 方正姚体 | FZYaoti |
| 华文彩云 | STCaiyun |
| 华文琥珀 | STHupo |
| 华文隶书 | STLiti |
| 华文行楷 | STXingkai |
| 华文新魏 | STXinwei |

















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









