







作者:李雪茸
介绍
Adaboost算法是一种集成学习(ensemble learning)方法。在集成学习中,强学习器指的是由多个机器学习模型组合形成的精度更高的模型。而参与组合的模型就被称为是弱学习器。进行预测时使用的是这些弱学习器的联合模型。训练时需要用训练样本依次训练这些弱学习器。 典型的集成学习算法是随机森林和boosting算法,Adaboost算法是boosting算法的一种实现版本。
Adaboost库参数介绍
Adaboost库分为AdaBoostClassifier(分类)和AdaBoostRegressor(回归),两者的参数相近,均包括Adaboost框架参数和弱学习器参数
1、框架参数
① base_estimator: 弱学习器,常用的一般是CART决策树或者神经网络MLP。
② n_estimators: 弱学习器数量,一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是50
③ learning_rate:弱学习器的权重缩减系数,取值范围为0~1。
④ algorithm:分类算法,AdaBoostClassifier才有,可选SAMME和SAMME.R。两者的区别是弱学习器权重的度量,SAMME使用分类器的分类效果作为弱学习器权重,而SAMME.R使用了对样本集分类的预测概率大小来作为弱学习器权重。
2、弱分类器参数
弱分类器参数要根据所选弱分类器而定,一般使用CART决策树,参数如下:
① criterion: 特征选取方法,分类是gini(基尼系数),entropy(信息增益),通常选择gini,即CART算法,如果选择后者,则是ID3和C4.5
② splitter: 特征划分点选择方法,可以是best或random,前者是在特征的全部划分点中找到最优的划分点,后者是在随机选择的部分划分点找到局部最优的划分点
③ max_depth: 树的最大深度,一般取10~100
④ min_samples_split:节点再划分所需最少样本数,如果节点上的样本数已经低于这个值,则不会再寻找最优的划分点进行划分,且以结点作为叶子节点,默认是2,如果样本过多的情况下,可以设定一个阈值
⑤ min_samples_leaf: 叶子节点所需最少样本数,如果达不到这个阈值,则同一父节点的所有叶子节点均被剪枝,这是一个防止过拟合的参数
⑥ min_weight_fraction_leaf: 叶子节点所有样本权重和,如果低于阈值,则会和兄弟节点一起被剪枝,默认是0,就是不考虑权重问题。
⑦ max_features: 划分考虑最大特征数,不输入则默认全部特征
⑧ max_leaf_nodes:最大叶子节点数,防止过拟合,默认不限制
实例
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_iris
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import LinearSVC
from sklearn import metrics
from sklearn.metrics import roc_auc_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
二分类问题
##导入数据
cancer = load_breast_cancer()
x = cancer.data
y = cancer.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.333, random_state=0) # 分训练集和验证集
# Adaboost分类器,使用svm为弱分类器
model = AdaBoostClassifier(LinearSVC(C=1),n_estimators=40,learning_rate=0.9,algorithm='SAMME')###使用SVM弱分类器
model.fit(x_train, y_train)
# 对测试集进行预测
y_pred = model.predict(x_test)
predictions = [round(value) for value in y_pred]
#计算准确率
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
print(f"\nAdaboost模型混淆矩阵为:\n{metrics.confusion_matrix(y_test,y_pred)}")
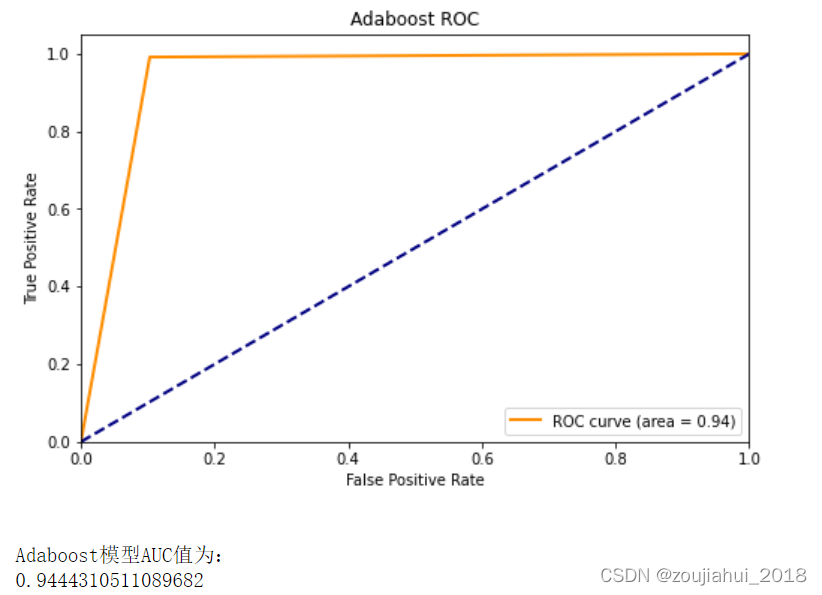
####绘制ROC曲线
fpr,tpr,threshold = roc_curve(y_test,y_pred) ###计算ROC曲线,即真阳率、假阳率
roc_auc = auc(fpr, tpr) ###计算auc值
lw = 2
plt.figure(figsize=(8, 5))
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Adaboost ROC')
plt.legend(loc="lower right")
plt.show()
print(f"\nAdaboost模型AUC值为:\n{roc_auc_score(y_test,y_pred)}")

多分类问题
###多分类
# 加载样本数据集
iris = load_iris()
X,y = iris.data,iris.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=12343)
model = AdaBoostClassifier(DecisionTreeClassifier(max_depth=5),n_estimators=40)
model.fit(X_train,y_train)
# 对测试集进行预测
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
#计算准确率
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
print(f"\nAdaboost模型混淆矩阵为:\n{metrics.confusion_matrix(y_test,y_pred)}")
















 4132
4132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









