






在学习【操作系统】 【MySQL】【Redis】后,发现其都有一些缓存淘汰的策略,因此一篇小文章总结一下。
目前还没着笔,初略一想MySQL和操作系统应该都是使用的
年轻代和老生代的改进策略,而Redis使用的是随机抽的策略。
MySQL
MySQL中存在一个内存缓存池,Buffer Pool。里面存在着控制块和缓存的数据页(当然还有些其他缓存,比如:锁信息、undo页等)。
下面的
LRU限制在缓存的数据页当中(控制块等应该也是不会淘汰的)
有了缓存池之后
- 当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再去磁盘中读取。
- 当修改数据时,首先是修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页,最后由后台线程将脏页写入到磁盘。
即MySQL会直接操作缓存池中的数据,然后再刷新到磁盘中。 在Buffer Pool中MySQL还会维护三个链表,分别为:LRU链表,dirty page 链表与free page链表。三个链表存在分别的意义为:
- LRU链表:内存是有限的,不能无限读入数据,此LRU链表key方便决定要淘汰哪些页面。---也正是本文的核心,内存淘汰策略。
- dirty page 链表:为了方便确认哪些数据页是脏页,要刷新入磁盘。
- free page链表:为了方便确认哪些页还没有读入数据。
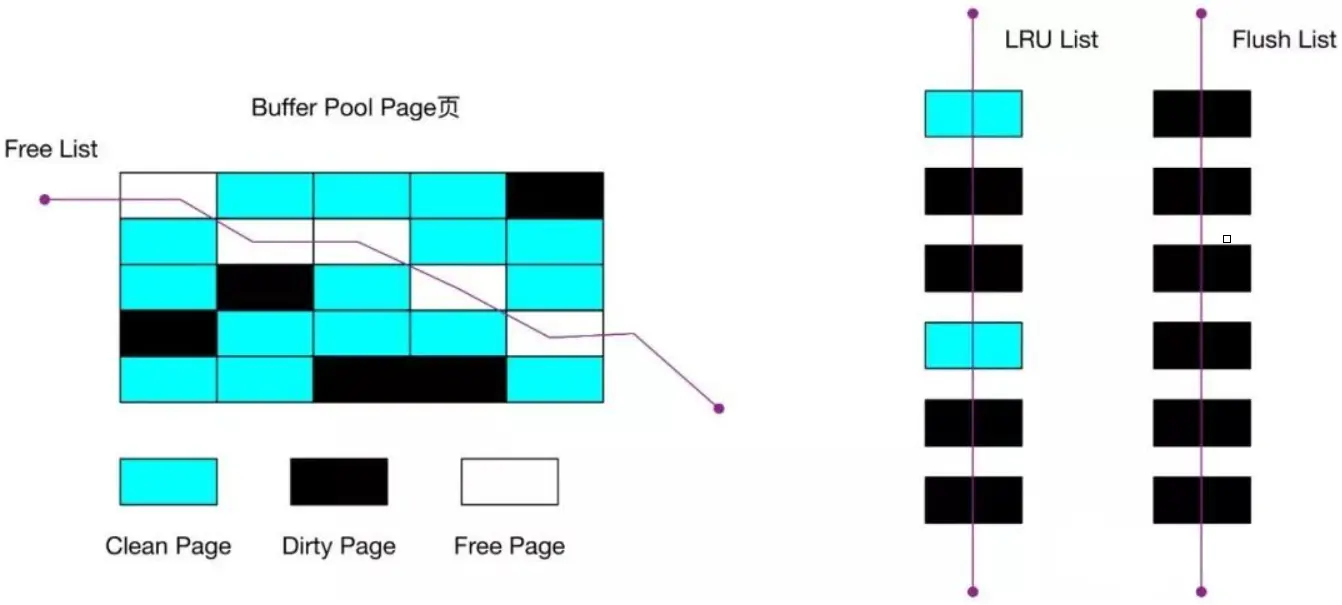
由三个链表的功能可以知道,最开始free list是满的(数据还没有读入),随后会越来越少。
Buffer Pool 的大小是有限的,对于一些频繁访问的数据我们希望可以一直留在 Buffer Pool 中,而一些很少访问的数据希望可以在某些时机可以淘汰掉,从而保证 Buffer Pool 不会因为满了而导致无法再缓存新的数据,同时还能保证常用数据留在 Buffer Pool 中。 要实现这个,最容易想到的就是 LRU(Least recently used)算法。 该算法的思路是,链表头部的节点是最近使用的,而链表末尾的节点是最久没被使用的。那么,当空间不够了,就淘汰最久没被使用的节点,从而腾出空间。 简单的 LRU 算法的实现思路是这样的:
- 当访问的页在 Buffer Pool 里,就直接把该页对应的 LRU 链表节点移动到链表的头部。
- 当访问的页不在 Buffer Pool 里,除了要把页放入到 LRU 链表的头部,还要淘汰 LRU 链表末尾的节点。
简单的LRU算法会有两个问题:预读失效和缓存污染。
MySQL解决这两个问题的基本思路:
- 解决预读失效:将缓存区分为新生代和老生代。预读的数据读入老生代(优先淘汰),如果真正使用了才会加入新生代。
- 解决缓存污染:由于预读的数据只要使用了就加入新生代,即使用一次就加入新生代,后面就算不用了新生代也全部被这些只用了一次的数据污染了。因此解决方案就是提高进入新生代的代价。
具体来说,为了解决缓存污染:MySQL 是这样做的,进入到 young 区域条件增加了一个停留在 **`old` 区域的时间判断**。 具体是这样做的,在对某个处在 old 区域的缓存页进行第一次访问时,就在它对应的控制块中记录下来这个访问时间:
- 如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该缓存页就不会被从 old 区域移动到 young 区域的头部;
- 如果后续的访问时间与第一次访问的时间不在某个时间间隔内,那么该缓存页移动到 young 区域的头部;
这个间隔时间是由 innodb_old_blocks_time控制的,默认是 1000 ms。 也就说,只有同时满足「被访问」与「在 old 区域停留时间超过 1 秒」两个条件,才会被插入到 young 区域头部,这样就解决了 Buffer Pool 污染的问题 。 另外,MySQL 针对 young 区域其实做了一个优化,为了防止 young 区域节点频繁移动到头部。young 区域前面 1/4 被访问不会移动到链表头部,只有后面的 3/4被访问了才会。
这个优化非常有意思,因为越靠前的区域就是越热点的数据,可能来回访问就是那几个热点数据,因此特别热点的数据访问就不用来回移动了hhh。
操作系统
参考:
当 CPU 访问的页面不在物理内存时,便会产生一个缺页中断,请求操作系统将所缺页调入到物理内存。 这个将所缺页调入到物理内存的过程也会涉及到内存淘汰策略。
不同的是操作系统淘汰的是页表,而MySQL淘汰的是数据页。其实本质上都是一样的hhh。 所缺页调入到物理内存的步骤大概为:
- 首先查找页表,找对应的页表项,如果页表项中的状态位为「无效的」,就触发缺页中断。
- 去磁盘找对应页面在磁盘中的位置,读取出来。
- 准备换入:物理内存中找空闲页,有就换入。没有就自然涉及了内存页面置换的一些策略了。
- 将页表项中的状态位设置为[有效的],重新执行对应的触发缺页中断的代码。
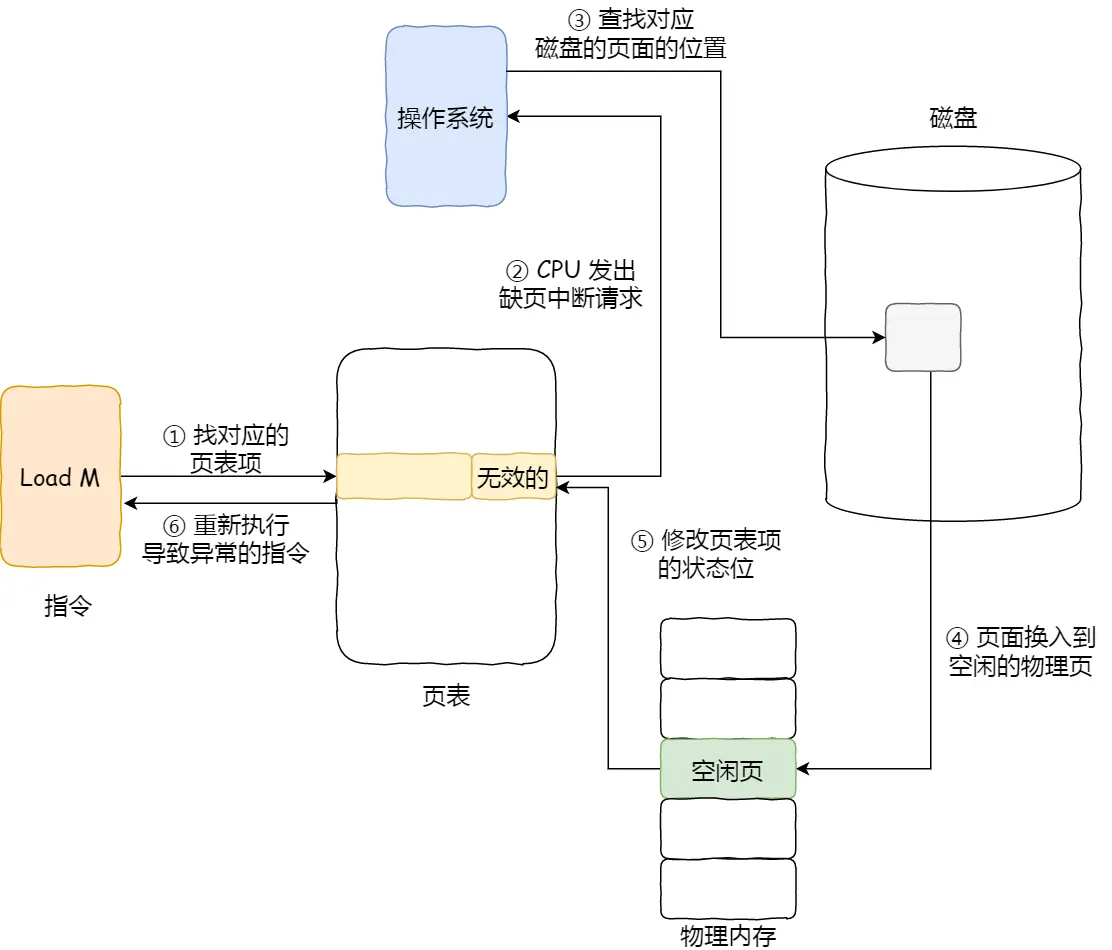
内存淘汰策略算法目标则是,尽可能减少页面的换入换出的次数,常见的页面置换算法有如下几种:
最佳页面置换算法(_OPT_):这是理论上的最优算法,因为未来不可知,所以是理论上的。它是一个页面置换算法的上限。
先进先出置换算法(_FIFO_):思想就是先入先出队列,效果差。
最近最久未使用的置换算法(_LRU_):近似最优置换算法,最优置换算法是通过「未来」的使用情况来推测要淘汰的页面,而 LRU 则是通过「历史」的使用情况来推测要淘汰的页面。使用LRU就要维护一个LRU链表(后面这几句都可以在MySQL的内存淘汰策略中有所体现),在每次访问内存时都必须要更新「整个链表」。
LRU虽然看上去不错,但是由于开销比较大,实际应用中比较少使用。MySQL用的是LRU,效果好,但是代价也是比较大的。
时钟页面置换算法(_Lock_):优化置换的次数,也能方便实现两者兼得,它跟
LRU近似,又是对FIFO的一种改进。
算法思想为:把所有的页面都保存在一个类似钟面的「环形链表」中,一个表针指向最老的页面。 当发生缺页中断时,算法首先检查表针指向的页面:遇到1则变为0,然后继续往下,知道遇到0就替换掉这个页面。
感觉是相对于
FIFO算法,每个页面多了一次的选择机会。
- 最不常用置换算法(_LFU_):当发生缺页中断时,选择「访问次数」最少的那个页面,并将其淘汰。(感觉算法名字不太贴切)。具体实现:对每个页面设置一个「访问计数器」,每当一个页面被访问时,该页面的访问计数器就累加 1。在发生缺页中断时,淘汰计数器值最小的那个页面。
要增加一个计数器来实现,这个硬件成本是比较高的,另外如果要对这个计数器查找哪个页面访问次数最小,查找链表本身,如果链表长度很大,是非常耗时的,效率不高。 但还有个问题,
LFU算法只考虑了频率问题,没考虑时间的问题,比如有些页面在过去时间里访问的频率很高,但是现在已经没有访问了,而当前频繁访问的页面由于没有这些页面访问的次数高,在发生缺页中断时,就会可能会误伤当前刚开始频繁访问,但访问次数还不高的页面。 那这个问题的解决的办法还是有的,可以定期减少访问的次数,比如当发生时间中断时,把过去时间访问的页面的访问次数除以 2,也就说,随着时间的流失,以前的高访问次数的页面会慢慢减少,相当于加大了被置换的概率。
Redis
参考:
Redis 内存淘汰策略共有八种,这八种策略大体分为「不进行数据淘汰」和「进行数据淘汰」两类策略。 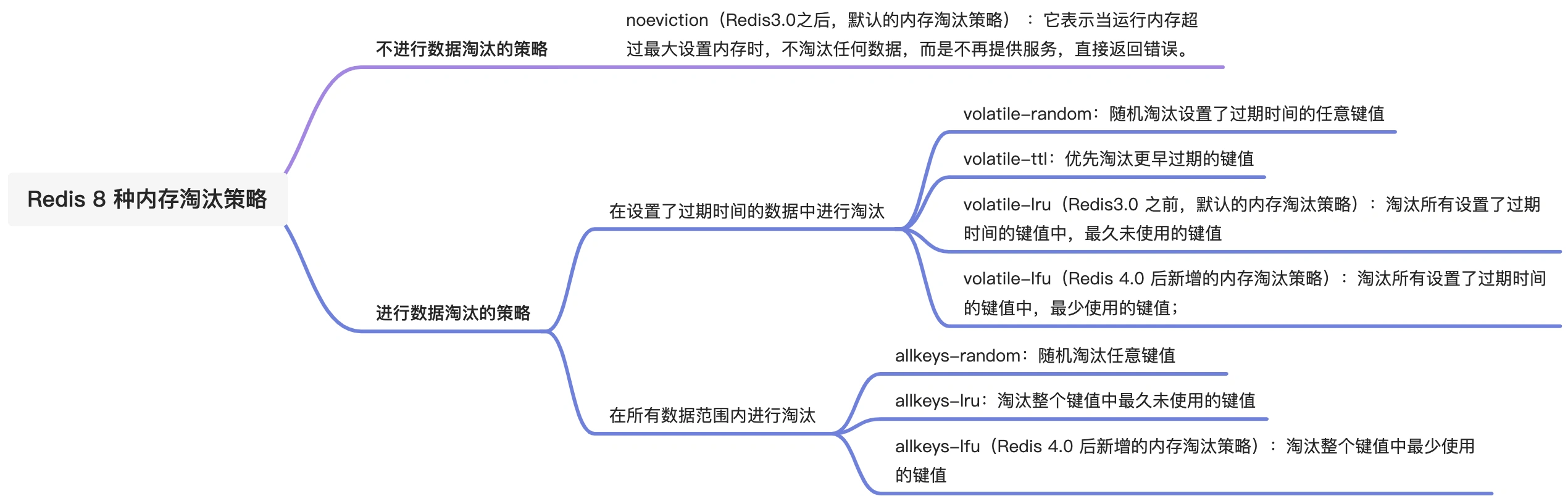 1、不进行数据淘汰的策略 noeviction(Redis3.0之后,默认的内存淘汰策略) :它表示当运行内存超过最大设置内存时,不淘汰任何数据,这时如果有新的数据写入,则会触发 OOM,但是如果没用数据写入的话,只是单纯的查询或者删除操作的话,还是可以正常工作。 2、进行数据淘汰的策略 针对「进行数据淘汰」这一类策略,又可以细分为「在设置了过期时间的数据中进行淘汰」和「在所有数据范围内进行淘汰」这两类策略。 在设置了过期时间的数据中进行淘汰:
1、不进行数据淘汰的策略 noeviction(Redis3.0之后,默认的内存淘汰策略) :它表示当运行内存超过最大设置内存时,不淘汰任何数据,这时如果有新的数据写入,则会触发 OOM,但是如果没用数据写入的话,只是单纯的查询或者删除操作的话,还是可以正常工作。 2、进行数据淘汰的策略 针对「进行数据淘汰」这一类策略,又可以细分为「在设置了过期时间的数据中进行淘汰」和「在所有数据范围内进行淘汰」这两类策略。 在设置了过期时间的数据中进行淘汰:
- volatile-random:随机淘汰设置了过期时间的任意键值;
- volatile-ttl:优先淘汰更早过期的键值。
- volatile-lru(Redis3.0 之前,默认的内存淘汰策略):淘汰所有设置了过期时间的键值中,最久未使用的键值;
- volatile-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,最少使用的键值;
在所有数据范围内进行淘汰:
- allkeys-random:随机淘汰任意键值;
- allkeys-lru:淘汰整个键值中最久未使用的键值;
- allkeys-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最少使用的键值
说白了就是LRU和LFU算法。
Redis 是如何实现 LRU 算法的?
简单的LRU算法存在什么问题?
MySQL中考虑的是LRU算法带来的预读失效和Buffer Pool污染的问题(简单LRU算法效果不好),而Redis是从LRU算法维护成本来考虑的。
- 需要用链表管理所有的缓存数据,这会带来额外的空间开销;
- 当有数据被访问时,需要在链表上把该数据移动到头端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。 当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
这样实现就自然没有了链表的开销和移动链表节点的开销了。但是多了一个额外字段(记录最后一次访问时间)的开销。
Redis 是如何实现 LFU 算法的?
可以在上文中看到操作系统实现LFU算法的问题有:1.加一个访问计数器有硬件成本 2.虽叫LFU,但是只考虑了次数,而没有考虑时间(频率)。
在LFU算法中,Redis实现相比于操作系统实现更好,真正的考虑了访问频率这个问题。 可以思考一下,为了考虑访问频率,我们至少需要哪些值。
- 当前的访问频率的值肯定是要记录的。
logc(Logistic Counter) - 上一次的访问时间,因为访问时间间隔不同,访问频率的更新值就不同。
ldt(Last Decrement Time)
在实现LRU算法的时候,不是多了一个维护上一次访问时间的字段吗?在LFU算法中肯定不能浪费呀,也是重新用到了这个字段。具体为: 在 LRU 算法中,Redis 对象头的 24 bits 的 lru 字段是用来记录 key 的访问时间戳,因此在 LRU 模式下,Redis可以根据对象头中的 lru 字段记录的值,来比较最后一次 key 的访问时间长,从而淘汰最久未被使用的 key。 在 LFU 算法中,Redis对象头的 24 bits 的 lru 字段被分成两段来存储,高 16bit 存储 ldt(Last Decrement Time),低 8bit 存储 logc(Logistic Counter)。 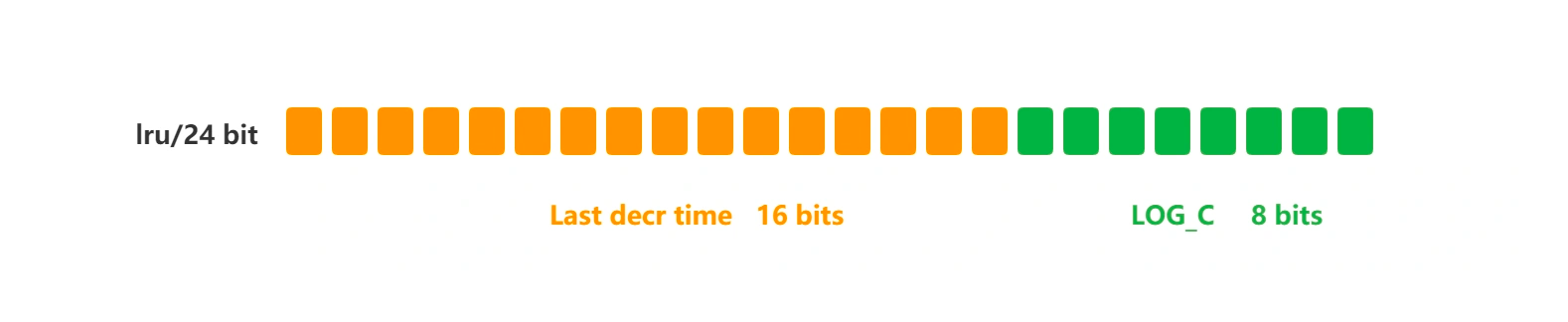
- ldt 是用来记录 key 的访问时间戳;
- logc 是用来记录 key 的访问频次,它的值越小表示使用频率越低,越容易淘汰,每个新加入的 key 的logc 初始值为 5。 ---注意是访问评次,而不是简单的访问次数。
本文由博客一文多发平台 OpenWrite 发布!














 2486
2486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









