






吞吐量、PV、QPS、TPS、RPS、I/O 负载概念。
吞吐量: 指单位时间内系统处理用户的请求数, 不同的角度评估方式也不同。
PV : 是 Page View 的缩写。来自浏览器的一次 html 内容请求会被看作一个 PV。
QPS:Queries Per Second 意思是 “每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
TPS是 Transactions Per Second 的缩写,也就是事务数 / 秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数,
RPS : 是 Requests Per Second 的缩写, 指并发数 / 平均响应时间。
I/0 负载: I/O 是 input/output 的缩写,即输入输出端口。每个设备都会有一个专用的 I/O 地址,用来处理自己的输入输出信息。一个系统要能正确工作,必须要有数据通道(data paths)的机制,软件和硬件系统都概莫能外。对于计算机系统而言,必须要有 data paths 的机制来确保 CPU, RAM 和 I/O 设备之间的信息数据能正确的流动。这些 data paths, 通常被称为总线 (BUS),是计算机内部主要的通信通道。若想深入可以参考 Understanding the Linux Kernel(https://book.douban.com/subject/1776614/)。
在技术人员的职业生涯中,总是不断开发新的系统。在设计系统的时候,因场景、时间而异。一个系统并不是开始就能设计的非常完美,绝对多数的情况是在有限的资源,优先解决核心问题。并预测可能发生的问题,通过反复迭代的逐步消除痛点。这本身是一个持久性的过程。但是早期优良的架构设计能为未来的工作带来非常大的帮助,如何去评判设计是否合理需要数据佐证。吞吐量、PV、QPS、TPS、RPS、I/O 这些指标早设计初期能为开发人员提供非常大的帮助。
参考定律
在设计系统时,应该多思考墨菲定律http://wiki.mbalib.com/wiki/%E5%A2%A8%E8%8F%B2%E5%AE%9A%E5%BE%8B
“”
任何事情都没表面看起来那么简单。
所以事情都会比你预期的时间长。
可能出错的事情总会出错。
如果你担心某一件发生,那么它就更有可能发生。
在系统划分的时,也要思考康威定律(http://www.melconway.com/Home/Conways_Law.html?spm=5176.100239.blogcont8611.8.e7792abC1tP3C)
系统架构是公司组织架构的反映。
应该按照业务闭环进行系统拆分 / 组织架构拆分, 实现闭环 / 高内聚 / 低耦合, 减少沟通成本。
在合适的时间进行系统拆分, 不要一开始就吧系统 / 服务拆分非常细。虽然闭环,但是每个人维护的系统多, 维护成本高。
—亿级流量网站架构核心技术
TPS(吞吐量)
一个系统的承压能力。单位时间内完成的工作量的量度。通常,平均响应时间越短,系统吞吐量越大;平均响应时间越长,系统吞吐量越小。但是,系统吞吐量越大,未必平均响应时间越短。因为在某些情况(例如,不增加任何硬件配置)吞吐量的增大,有时会把平均响应时间作为牺牲,来换取一段时间处理更多的请求。
影响吞吐量的几个重要参数指标
QPS、TPS、并发数、响应。
名词概述
并发数 :系统同时处理的 reqeust / 事物数。
响应时间 : 一般取 reqeust 的平均响应时间,很大程度上受客户端环境因素影响。
TPS (QPS ): 并发数 / 响应时间。
系统响应时间计算
用于测量完成一个特定请求需要花费多少时间。它是一个非常重要的度量值因为它是用户体验的一个指数。尽管这样,你必须确保你理解你测量的是什么:
系统级的反应时间。
组件级的反应时间。
它们是完全不同的,因为系统级包括像队列时间这样的变量是差别很大的。
值得注意的是,响应时间同时也是不容易测量的度量值,因为它比其它的度量值更容易变化。因此你必需了解反应时间的分布。如果应用对你大部分用户的反应时间是 2 秒钟,而对 10%用户的反应时间却是 10 秒钟,在这种情况下,你必须知道这个反应时间的分布,才能精确地评估该问题和解决它。这就要测量它们的反应时间并且得到它们的标准偏差,理想的情况是用一个柱状图把反应时间的分布显示出来。
举个???? 场景:
一位用户通过浏览器访问网站查看新闻。栗子中每个操作用别名代替,比如客户请求服务器过程、时间同称 N1。
实线(请求),虚线(响应)。
网络传输时间: N1+N2 。
应用服务器处理时间: A1 + A11 OR A2 + A22。
数据库服务器处理时间: D1 + D11 OR D2 + D22。
响应时间 N1+N2+A1+A11+D1+D11 OR N1 + N2 + A2 + A22 + D2 + D22。
假设参数耗时 :
N1 = 150ms ; N2 = 200ms。
A1 = 10ms ; A11 = 10ms ; A2 = 10ms ;A22 = 10ms 。
D1 = 10ms ; D11 = 20ms ; D2 = 20ms ; D22 = 30。
单次 reqeust 。
耗时T1 = N1 + A1 + D1 + D11 + A11 + N2。
流程P1 = N1– A1 – D1 – D11 – A11 – N2。
请求一次网站首页响应时间:150 + 200 + 10 + 10 + 10 + 20 = 400,也就是客户请求网站地址的那一刻到看到网站至少需要 400ms(半秒)。
并发用户数的计算公式
系统用户数: 系统额定的用户数量,如一个 OA 系统,可能使用该系统的用户总数是 4000 个,那么这个数量,就是系统用户数。
同时在线用户数: 在一定的时间范围内,最大的同时在线用户数量。
同时在线用户数 = 每秒请求数 RPS(吞吐量) + 并发连接数 + 平均用户思考时间。
平均并发用户数的计算: C = nL / T
C 是平均的并发用户数。
n 是平均每天访问用户数 (login session)。
L 是一天内用户从登录到退出的平均时间 (login session 的平均时间)。
T 是考察时间长度 (一天内多长时间有用户使用系统)。
并发用户数峰值计算: C^ 约等于 C + 3* 根号 C 其中 C^ 是并发用户峰值,C 是平均并发用户数,该公式遵循泊松分布理论。
吞吐量的计算公式
从业务角度看
请求数 / 秒。
页面数 / 秒。
人数 / 天或处理业务数 / 小时等单位来衡量。
吞吐量可以用
从网络角度看,吞吐量可以用:
字节 / 秒来衡量
对于交互式应用来说,吞吐量指标反映的是服务器承受的压力,他能够说明系统的负载能力。
以不同方式表达的吞吐量可以说明不同层次的问题,例如:
以字节数 / 秒方式可以表示数要受网络基础设施、服务器架构、应用服务器制约等方面的瓶颈。
已请求数 / 秒的方式表示主要是受应用服务器和应用代码的制约体现出的瓶颈。
思考时间的计算公式
Think Time,从业务角度来看,这个时间指用户进行操作时每个请求之间的时间间隔,为了模拟这样的时间间隔,引入了思考时间这个概念,来更加真实的模拟用户的操作。在吞吐量这个公式中 F = VU * R / T 说明吞吐量 F 是 VU 数量、每个用户发出的请求数 R 和时间 T 的函数,而其中的 R 又可以用时间 T 和用户思考时间 TS 来计算:R = T / TS 下面给出一个计算思考时间的一般步骤:
首先计算出系统的并发用户数
C = nL / TF = R × C
统计出系统平均的吞吐量
F= VU * R / T R × C = VU * R / T
统计出平均每个用户发出的请求数量
R= u_C_T / VU
根据公式计算出思考时间
TS= T / R
因素(指标)
资源利用率
这里所谓的资源是对于系统中的一个抽象的概念,它包括很多方面
reqeust 对 cpu 的消耗:单个 reqeust 对 CPU 消耗越高,外部系统接口、IO 影响速度越慢,系统吞吐能力越低,反之越高。
内存负载:系统对系统内存、vm 虚拟内存、swap 交换区的使用情况。
iO 负载消耗 (这里的 IO 负载是指硬盘 IO ,并不是网络 IO): 系统在运行中常常会涉及到大量的磁盘读写操作。磁盘有两个重要的参数: Seek time、 Rotational latency。正常的 I/O 计数为:1000/(Seek time+Rotational latency)*0.75 在此范围内属正常。当达到 85%的 I/O 计数以上时则基本认为已经存在 I/O 瓶劲。理论情况下,磁盘的随机读计数为 125、顺序读计数为 225。对于数据文件而言是随机读写,日志文件是顺序读写。
外部接口
一个系统会将系统内的功能封装成接口 (RESTFUL、SOAP) 的形式向外部提供,这些外部接口和内部的代码处理逻辑是强关联的。比如使用到支付包,在一个支付 reqeust 中需要发起对支付接口的请求完成整个业务流程。
2、PV
PV(page view)即页面浏览量,通常是衡量一个网络新闻频道或网站甚至一条网络新闻的主要指标。网页浏览数(page view)是评价网站流量最常用的指标之一,简称为 PV。搜索引擎会根据网站的 PV 来判断网站的好与坏,是影响网站排名的重要因素之一。
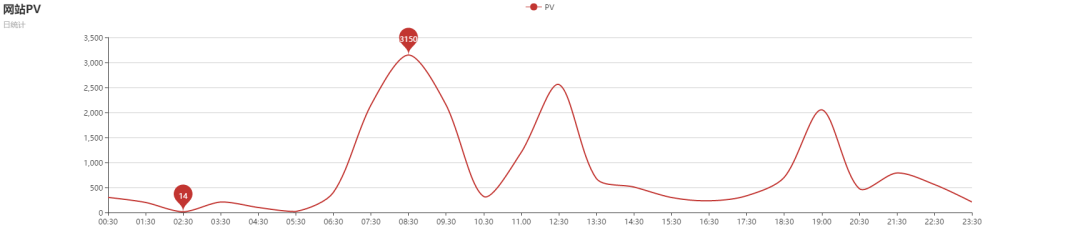
一般看新闻也就集中在早上、中午、晚上。假设早上 7:30 - 8:30 网站有会很大访问量大概 3500 左右。
3、QPS、TPS
每秒钟 request / 事务数量,一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。
事务可以从客户端角度进行定义。如:
一个登录的 POST 请求可定义为一个事务。
一个文件上传下载的动作也可定义为一个事务。
一组连续的请求操作也可定义一个事务。
事务也可从服务器端定义,如:
理解了事务,再理解 TPS,TPS 需要结合性能测试场景来说明:
多种模块一起进行测试,更符合真实场景,便于对服务器的整体处理能力进行评估。
TPS = 单个事务的 TPS 总和。
本次测试只测登录这一功能,便于分析和寻找瓶颈。
也可做并发测试。
TPS = 总事务数 / 总时间 (秒)。
单体
混合
执行一个数据库事务。
执行一段存储过程。
执行一个服务器请求等。
大多数情况下,我们使用加权协函数平均方法来计算客户机的得分,利用客户机的这些信息使用加权协函数平均方法来计算服务器端的整体 TPS 得分。
5、RPS
每秒请求数,这里还有两个我们通常认为和 RPS 相等的名词,arrival rate、TPS。
作者:小峰同学
来源链接:
https://z201.cn/2019/03/20/%E5%90%8E%E7%AB%AF%E5%BA%94%E7%94%A8%E6%80%A7%E8%83%BD%E6%8C%87%E6%A0%87/
















 466
466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









