






一. 使用DataStream API方式开发Flink程序
1. 创建工程并添加依赖
1.1 创建一个maven工程,添加依赖
我们需要添加的依赖最重要的就是 Flink 的相关组件,包括 flink-java、flink-streaming-java,以及 flink-clients(客户端,也可以省略)。
<properties>
<flink.version>1.13.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
1.2 配置日志管理
在目录 src/main/resources 下添加文件:log4j.properties,内容配置如下:
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
2. 编写代码
我会用一个最简单的示例来说明 Flink 代码怎样编写:统计一段文字中,每个单词出现的频次。这就是传说中的WordCount 程序,尽管 Flink 自身的定位是流式处理引擎,但它同样拥有批处理的能力。下面是针对不同的处理模式、不同的输入数据形式,分别编写WordCount 代码的实现。
2.1 批处理实现
2.1.1 首先在工程根目录下新建一个 input 文件夹,并在下面创建文本文件 words.txt,并输入一些单词
hello world
hello flink
hello java
2.1.2 新建 Java 类 BatchWordCount,编写代码
package com.learn;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @Author wangkeshuai
* @Date 2023/4/7 10:18
* @Description 使用Flink进行批处理
*/
public class BatchWordCount {
public static void main(String[] args) throws Exception{
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件读取数据 按行读取(存储的元素就是每行的文本)
DataSource<String> lineDS = env.readTextFile("input/words.txt");
// 3. 转换数据格式
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS
.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
})
.returns(Types.TUPLE(Types.STRING, Types.LONG)); //当 Lambda 表达式使用 Java 泛型的时候, 由于泛型擦除的存在, 需要显示的声明类型信息
// 4. 按照 word 进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG =
wordAndOne.groupBy(0);
// 5. 分组内聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);
// 6. 打印结果
sum.print();
}
}
2.1.3 运行程序,控制台会打印出结果:
(flink,1)
(world,1)
(hello,3)
(java,1)
2.2 流处理实现
2.2.1 新建一个 Java 类 StreamWordCount,具体代码实现如下:
package com.learn;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* @Author wangkeshuai
* @Date 2023/4/7 10:37
* @Description 使用Flink进行无界流处理
*/
public class StreamWordCount {
public static void main(String[] args) throws Exception{
//1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2. 使用socket方式读取文本流,用 nc -lk 7777进行输入
DataStreamSource<String> lineDSS = env.socketTextStream("localhost", 7777);
//3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
//4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne.keyBy(t -> t.f0);
//5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS.sum(1);
//6. 打印
result.print();
//7. 执行
env.execute();
}
}
2.2.2 运行代码,并在主机上,执行下列命令,发送数据进行测试
wangkeshuai@wangkeshuaideMacBook-Air ~ % nc -lk 7777
hello flink
hello world
hello java
2.2.3 代码控制台输出如下
7> (flink,1)
3> (hello,1)
5> (world,1)
3> (hello,2)
3> (hello,3)
2> (java,1)
3. 本地启动Flink,提交作业至Flink执行
3.1 启动Flink
3.1.1 下载压缩包
进入 Flink 官网,下载 1.16.0 版本安装包 flink-1.16.0-bin-scala_2.12.tgz,注意此处选用对应 scala 版本为 scala 2.12 的安装包。
3.1.2 解压
tar -zxvf flink-1.16.0-bin-scala_2.12.tgz -C /opt/module/
3.1.3 启动
cd flink-1.16.0/
bin/start-cluster.sh
3.1.4 访问web UI http://localhost:8081/
3.2 提交作业
3.2.1 项目打包
执行maven的package命令将项目进行打包,打 包 完 成 后 , 在 target 目 录 下 即 可 找 到 所 需 JAR 包 , JAR 包 会 有 两 个 ,FlinkTutorial-1.0-SNAPSHOT.jar 和 FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar,因为集群中已经具备任务运行所需的所有依赖,所以建议使用 FlinkTutorial-1.0-SNAPSHOT.jar。
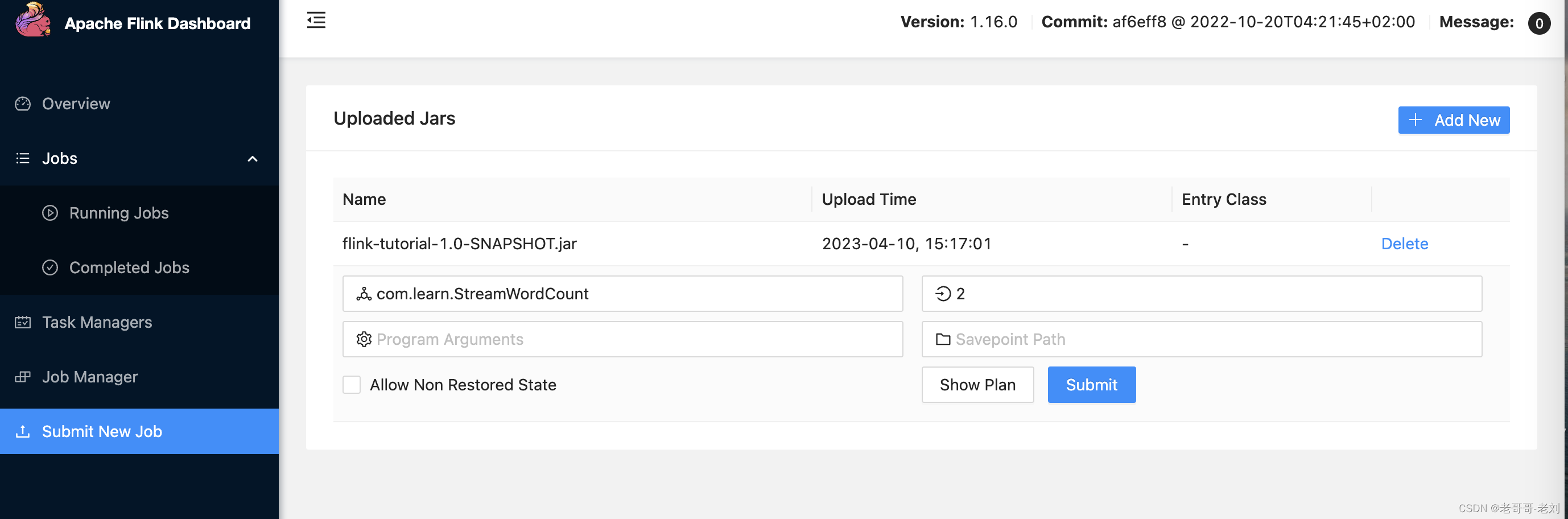
3.2.2 在web UI上提交作业
任务打包完成后,首先执行nc -lk 7777,然后打开 Flink 的 WEB UI 页面,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的 JAR 包,点击该 JAR 包,出现任务配置页面,进行相应配置,主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行.
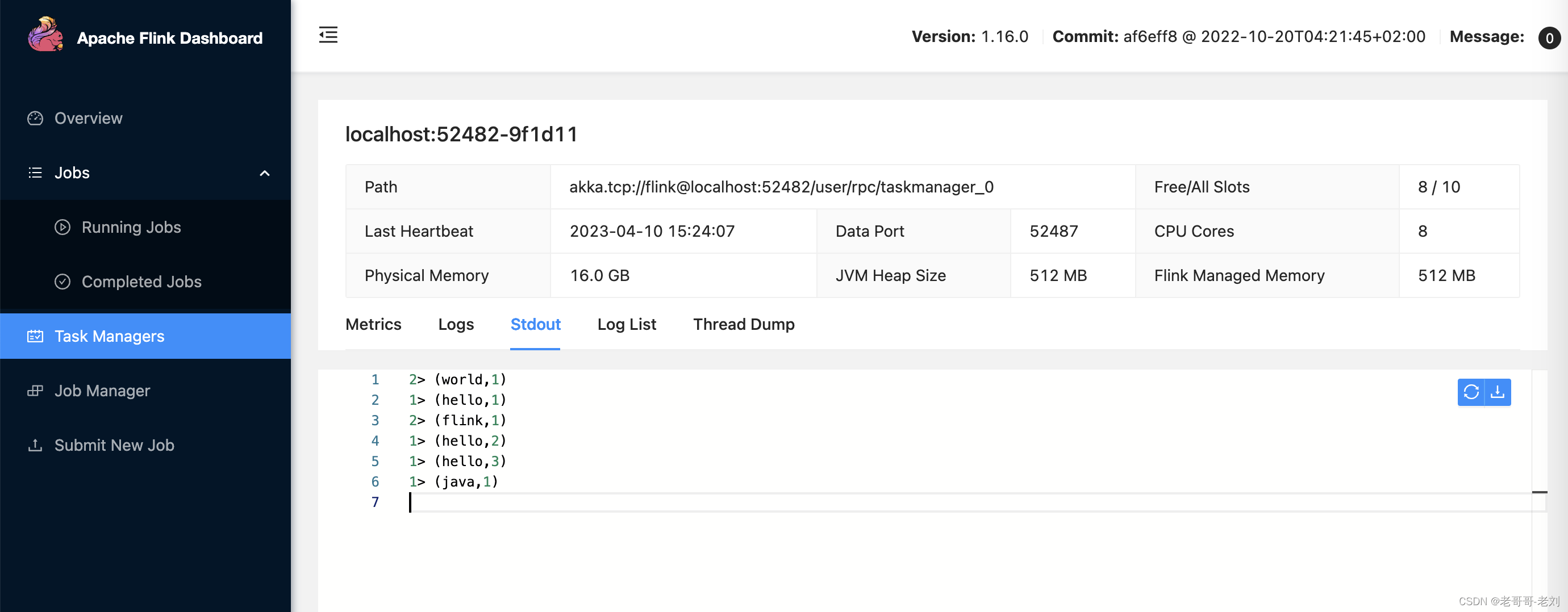
3.2.3 在nc上输入单词,并在web UI进行查看
二、使用Table API和SQL方式开发Flink程序
1. Flink的多层API
在 Flink 提供的多层级 API 中,核心是 DataStream API,这是我们开发流处理应用的基本途径;底层则是所谓的处理函数(process function),可以访问事件的时间信息、注册定时器、自定义状态,进行有状态的流处理。DataStream API 和处理函数比较通用,有了这些 API,理论上我们就可以实现所有场景的需求了。
不过在企业实际应用中,往往会面对大量类似的处理逻辑,所以一般会将底层 API 包装成更加具体的应用级接口。怎样的接口风格最容易让大家接收呢?作为大数据工程师,我们最为熟悉的数据统计方式,当然就是写 SQL 了。
SQL 是结构化查询语言(Structured Query Language)的缩写,是我们对关系型数据库进行查询和修改的通用编程语言。在关系型数据库中,数据是以表(table)的形式组织起来的,所以也可以认为 SQL 是用来对表进行处理的工具语言。无论是传统架构中进行数据存储的MySQL、PostgreSQL,还是大数据应用中的 Hive,都少不了 SQL 的身影;而 Spark 作为大数据处理引擎,为了更好地支持在 Hive 中的 SQL 查询,也提供了 Spark SQL 作为入口。
Flink 同样提供了对于“表”处理的支持,这就是更高层级的应用 API,在 Flink 中被称为Table API 和 SQL。Table API 顾名思义,就是基于“表”(Table)的一套 API,它是内嵌在 Java、Scala 等语言中的一种声明式领域特定语言(DSL),也就是专门为处理表而设计的;在此基础上,Flink 还基于 Apache Calcite 实现了对 SQL 的支持。这样一来,我们就可以在 Flink 程序中直接写 SQL 来实现处理需求了。

2. 编写代码
2.1 导入依赖
我们想要在代码中使用 Table API,必须引入相关的依赖
<!-- 本地使用Flink Table API需要引入的依赖 -->
<!-- 这里的依赖是一个 Java 的“桥接器”(bridge),主要就是负责 Table API 和下层 DataStream API 的连接支持-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 这里主要添加的依赖是一个“计划器”(planner),它是 Table API 的核心组件,负责提供运行时环境,并生成程序的执行计划。由于 Flink 安装包的 lib 目录下会自带 planner,所以在生产集群环境中提交的作业不需要打包这个依赖。-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 在 Table API 的内部实现上,部分相关的代码是用 Scala 实现的,所以还需要额外添加一个 Scala 版流处理的相关依赖。 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 如果想实现自定义的数据格式来做序列化,可以引入下面的依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
2.2 代码中具体实现
import com.pojo.Event;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @Author wangkeshuai
* @Date 2023/4/10 15:46
* @Description 测试Table API和SQL的使用
*/
public class TableExample {
public static void main(String[] args) throws Exception{
//获取流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//读取数据源
DataStreamSource<Event> eventStream = env.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=7", 105 * 1000L)
);
//获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//将数据流转换为表
Table eventTable = tableEnv.fromDataStream(eventStream);
//用执行sql的方式提取数据
Table visitTable = tableEnv.sqlQuery("select url, user from " + eventTable);
//将表转换为数据流,打印输出
tableEnv.toDataStream(visitTable).print();
//执行程序
env.execute();
}
}
2.3 执行结果
+I[./home, Alice]
+I[./cart, Bob]
+I[./prod?id=1, Alice]
+I[./home, Cary]
+I[./prod?id=3, Bob]
+I[./prod?id=7, Alice]















 1940
1940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









