









title: 实验七 DataStream API编程实践
date: 2024-04-09 00:35:49
description: 大数据flink基础作业
cover: https://elik-1307874295.cos.ap-guangzhou.myqcloud.com/images/md_picture/bigdata/large-895567_1280.webp?imageSlim
aside: true
categories:
- spark
- flink
tags: - spark
- flink
实验七 DataStream API编程实践
一、实验目的
- 熟悉Flink的DataStream API基本操作;
- 熟悉使用Flink编程解决实际具体问题的方法。
二、实验平台
- 操作系统:Ubuntu22.04.5
- Java IDE:IntelliJ IDEA
- Flink版本:1.11.2
- Scala版本:2.12
三、实验内容
1. DataStream转换算子基本操作
(1) Tom同学的总成绩平均分是多少;
(2) Mary选了多少门课;
(3) 各门课程的平均分是多少;
(4) 该系DataBase课程共有多少人选修;
(5) 列出及格(分数大于60)的学生、课程及成绩
2. Kafka作为数据输入输出源基本操作
将题目1中的数据通过Kafka作为输入源,经过Flink处理后,将结果输出到Kafka,模拟流处理过程。
3. 状态编程
结合Flink中的状态编程,求出每个学生的所有科目中的最高成绩及其对应的科目名称和成绩录入时间。输入数据通过Kafka输入,处理结果使用Kafka输出显示(将最高成绩作为状态保存、更新)。
4. 窗口内数据统计
结合Flink中窗口相关知识,编写Flink应用程序,每15秒统计一次每个窗口内每个学生的最高成绩及其对应的科目名称和成绩录入时间。观察输出结果,与题目3结果进行比较(使用Kafka作为输入输出源)。
5. 窗口与水位线基本操作
结合Flink中窗口与水位线相关知识,编写Flink应用程序,每15秒统计一次每个窗口内每个学生的最高成绩及其对应的科目名称和成绩录入时间。观察输出结果,理解窗口与水位线的处理流程(使用Kafka作为输入输出源,设置延迟时间为3秒,且能够处理迟到30秒的数据)。
三、实验过程
| 实验步骤 | 实验内容 |
|---|---|
| 1 | 1. DataStream转换算子基本操作代码 |
| 2 | 2. Kafka作为数据输入输出源基本操作代码 |
| 3 | 3. 状态编程代码 |
| 4 | 4. 窗口内数据统计代码 |
| 5 | 5. 窗口与水位线基本操作代码 |
1-DataStream转换算子基本操作代码
package com.huangbin
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.TimeCharacteristic
/*问题解决: Flink 是流式处理框架,它会根据数据到达的顺序来进行计算。在您提供的数据中,Tom 的数据是以事件时间(timestamp)顺序排列的,但是在 Flink 中默认是按照事件时间(Event Time)来进行处理的,而不是按照数据顺序。*/
object StudentGradeAnalysis {
case class GradeRecord(studentId: String, subject: String, score: Int, timestamp: Long)
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val inputDataStream = env.fromElements(
"Jack Math 86 1602727715",
"Jack Algorithm 81 1602727716",
"Jack Flink 90 1602727717",
"Rose Math 77 1602727718",
"Jack Database 63 1602727719",
"Rose Algorithm 51 1602727720",
"Tom Database 73 1602727721",
"Tom Datastructure 62 1602727722",
"Rose Database 61 1602727723",
"Rose Datastructure 43 1602727724",
"Tom Math 57 1602727725",
"Jack Datastructure 51 1602727726",
"Tom Algorithm 43 1602727727",
"Jim Math 80 1602727728",
"Jim Algorithm 90 1602727729",
"Jim Database 85 1602727730",
"Jim Datastructure 89 1602727735",
"Harry Database 43 1602727740",
"Harry Datastructure 70 1602727745",
"Mary Math 89 1602727750",
"Mary Algorithm 91 1602727755",
"Mary Database 85 1602727760",
"Mary Datastructure 87 1602727765",
"Peter Math 77 1602727770",
"Peter Algorithm 79 1602727775",
"Peter Database 31 1602727780",
"Peter Datastructure 51 1602727785",
"Harry Math 51 1602727790",
"Harry Algorithm 62 1602727795"
)
var continue = true
while (continue) {
println("Please select an option:")
println("1. Calculate the average score of Tom.")
println("2. Count the number of courses Mary selected.")
println("3. Calculate the average score of each course.")
println("4. Count the number of students who chose the Database course.")
println("5. List the students, courses, and scores of those who passed (score > 60).")
println("6. Exit")
val choice = scala.io.StdIn.readLine()
choice match {
case "1" =>
calculateAverageScoreOfTom(inputDataStream)
case "2" =>
countCoursesSelectedByMary(inputDataStream)
case "3" =>
calculateAverageScoreOfEachCourse(inputDataStream)
case "4" =>
countStudentsChoosingDatabaseCourse(inputDataStream)
case "5" =>
listPassedStudentsAndScores(inputDataStream)
case "6" =>
continue = false
case _ =>
println("Invalid choice. Please enter a valid option.")
}
env.execute("StudentGradeAnalysis")
}
env.execute("StudentGradeAnalysis")
}
def calculateAverageScoreOfTom(inputDataStream: DataStream[String]): Unit = {
val avgStream = inputDataStream
.filter(data => data.split(" ")(0) == "Tom")
.map(data => (data.split(" ")(0), data.split(" ")(2).toDouble, 1))
.keyBy(0)
.reduce((data1, data2) => (data1._1, data1._2 + data2._2, data1._3 + data2._3))
.map(data => (data._1, data._2 / data._3))
avgStream.print("Average Score")
}
def countCoursesSelectedByMary(inputDataStream: DataStream[String]): Unit = {
val courseNumStream = inputDataStream
.map(data => (data.split(" ")(0), data.split(" ")(1), 1))
.keyBy(0)
.reduce((data1, data2) => (data1._1, null, data1._3 + data2._3))
.map(data => (data._1, data._3))
.filter(data => data._1 == "Mary")
courseNumStream.print("Mary selected courses count:")
}
def calculateAverageScoreOfEachCourse(inputDataStream: DataStream[String]): Unit = {
val avgOfCourseStream = inputDataStream
.map(data => (data.split(" ")(1), data.split(" ")(2).toDouble, 1))
.keyBy(0)
.reduce((data1, data2) => (data1._1, data1._2 + data2._2, data1._3 + data2._3))
.map(data => (data._1, data._2 / data._3))
avgOfCourseStream.print("Average score of each course:")
}
def countStudentsChoosingDatabaseCourse(inputDataStream: DataStream[String]): Unit = {
val numOfChoosenStream = inputDataStream
.map(data => (data.split(" ")(1), 1))
.filter(_._1 == "Database")
.keyBy(0)
.sum(1)
numOfChoosenStream.print("Number of students choosing Database course:")
}
def listPassedStudentsAndScores(inputDataStream: DataStream[String]): Unit = {
val dataStream = inputDataStream
.map(data => (data.split(" ")(0), data.split(" ")(1), data.split(" ")(2).toInt))
.filter(_._3 > 60)
dataStream.print("Passed students, courses, and scores:")
}
}
截图

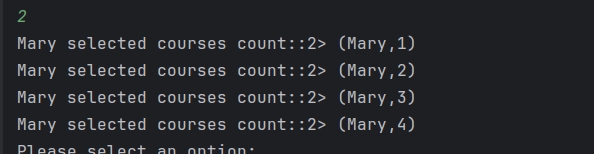
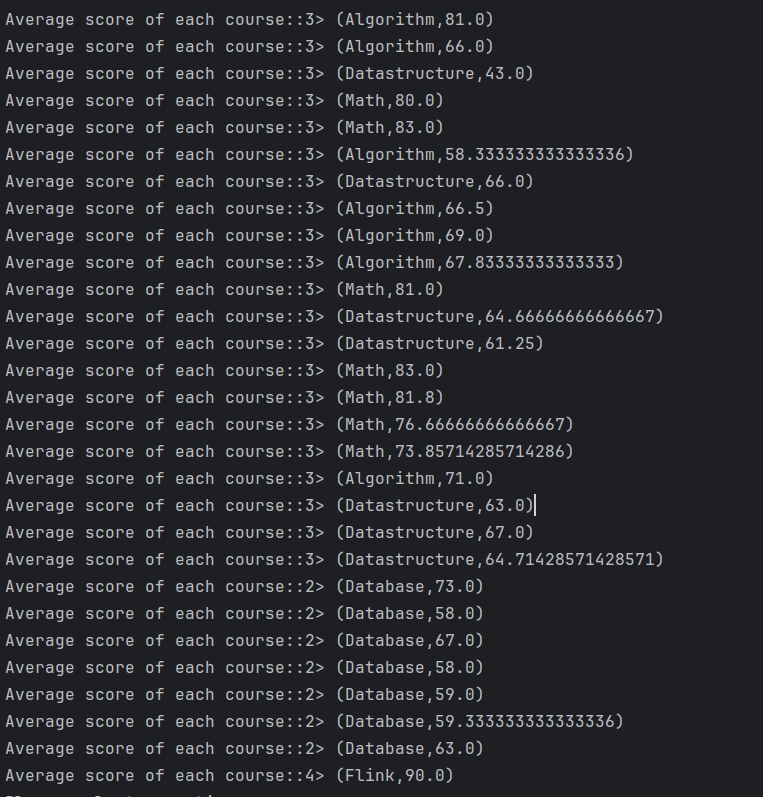
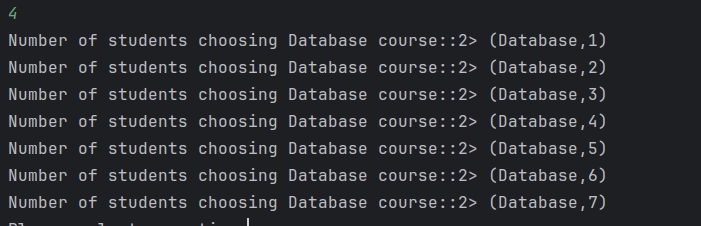
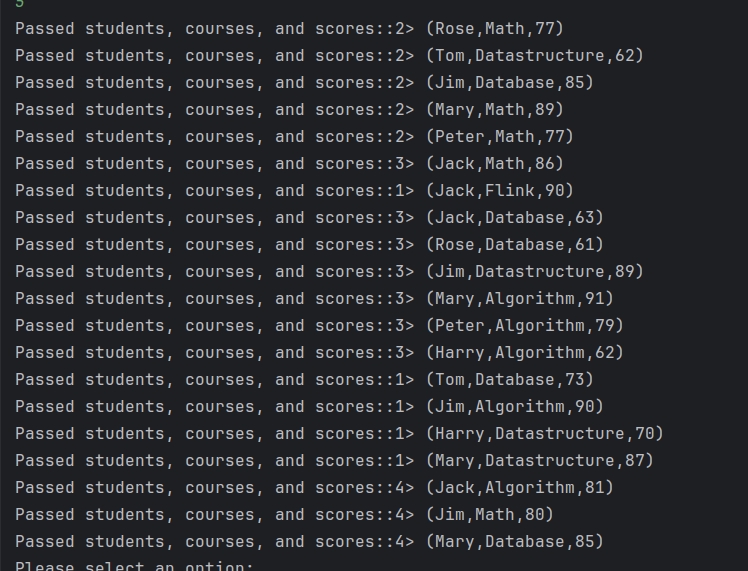
2-Kafka作为数据输入输出源基本操作代码
package com.huangbin.kafka
import java.util.Properties
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka._
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
object Test2 {
def main(args: Array[String]): Unit = {
// 1.创建流处理执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2.设置Kafka相关参数
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
// 3.从Kafka中读取数据
val stream = env.addSource(new FlinkKafkaConsumer[String]("scoreInput", new SimpleStringSchema(), properties))
// 4. 对读取的数据进行处理
val dataStream = stream
.map(data => (data.split(" ")(0), data.split(" ")(1), data.split(" ")(2).toDouble))
.keyBy(0)
.split(data =>{
if(data._3 >= 60.0)
Seq("pass")
else Seq("fail")
})
.select("pass")
.map(data => data.toString())
// 5.设置Kafka输出
dataStream.addSink(new FlinkKafkaProducer[String]("localhost:9092", "scoreOutput", new SimpleStringSchema()))
// 6.在Console中输出
dataStream.print()
env.execute("Test2")
}
}
运行程序后
接着:
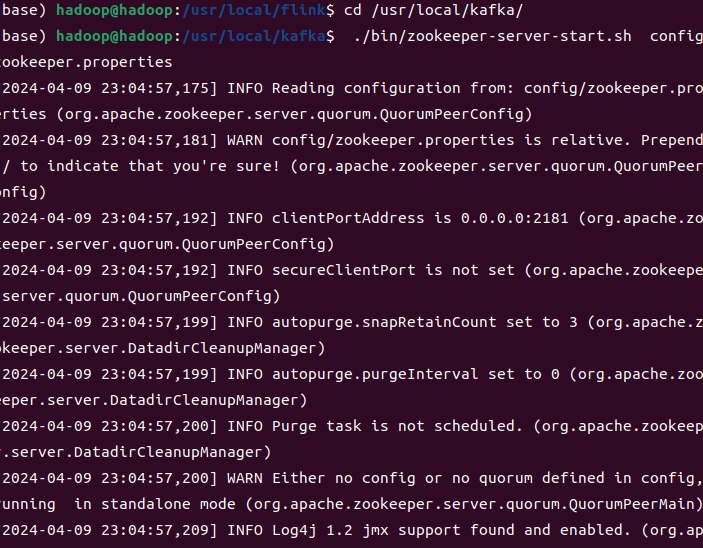
1.打开一个终端,输入下面命令启动Zookeeper服务:
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties
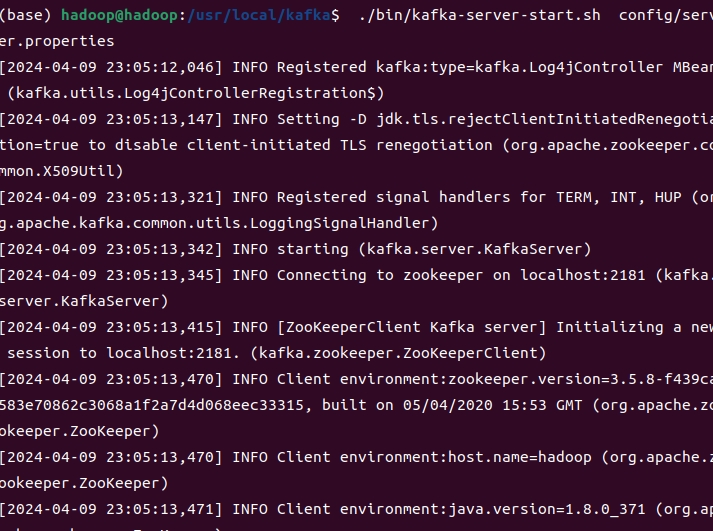
2.打开第二个终端,然后输入下面命令启动Kafka服务:
cd /usr/local/kafka
./bin/kafka-server-start.sh config/server.properties
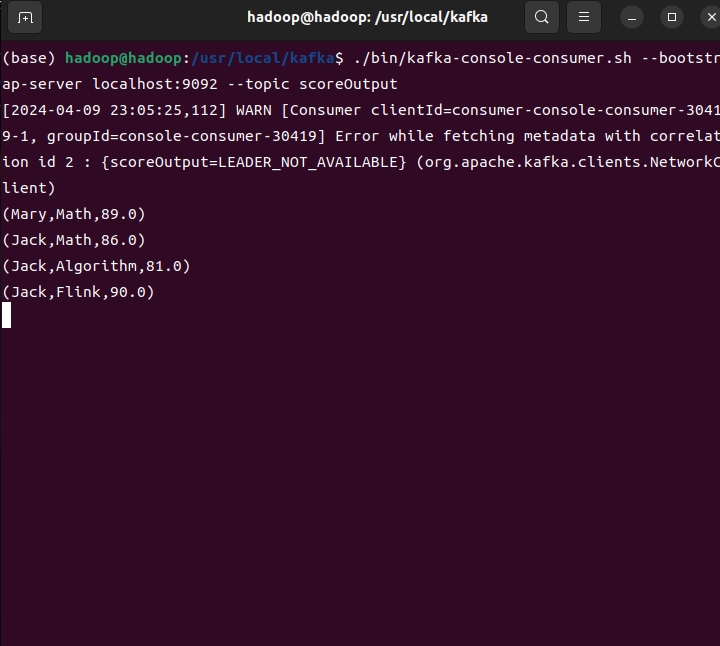
3.在Kafka安装目录下,输入命令:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic scoreOutput
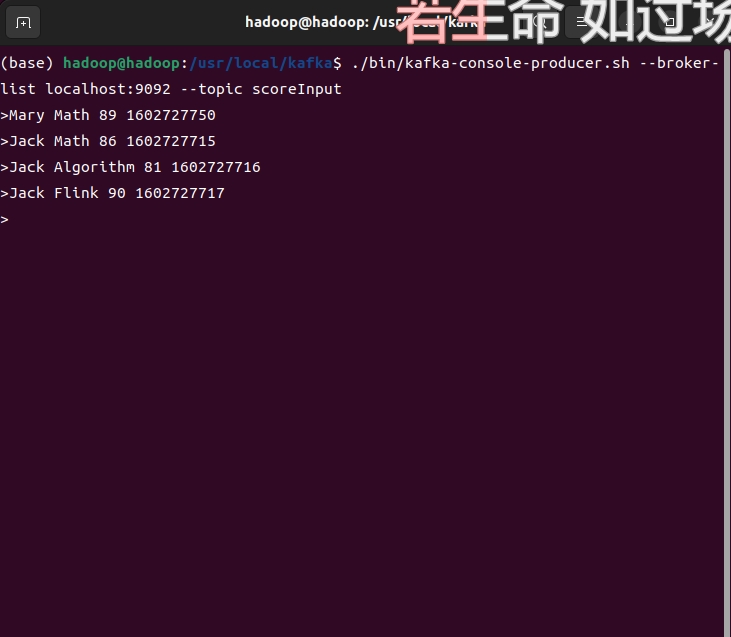
4.重新开启一个窗口,在Kafka安装目录下,输入命令:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic scoreInput
此终端作为数据的输入终端。
5.输入完命令,回车,光标会移动到下一行等待数据输入。按照要求输入数据,在输出终端会看到数据的处理结果。
截图:
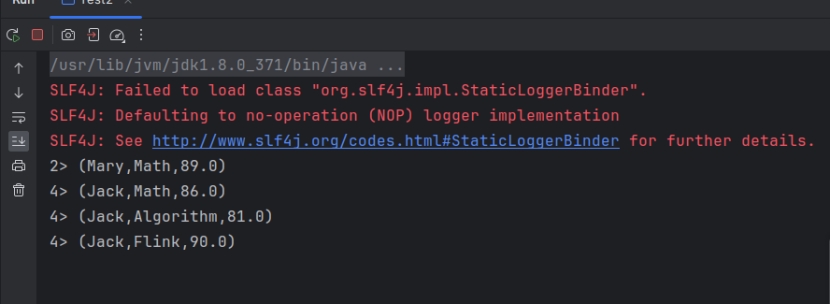
3-状态编程代码
package com.huangbin.Stateful_programming
import java.util.Properties
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.api.common.state._
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka._
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.flink.util.Collector
/*程序解释:将数据流按照姓名进行分区。
使用 RichFlatMapFunction 实现自定义的 flatMap 函数,在该函数中,每次接收到一个 Score 对象时,与上一次的成绩进行比较,如果当前成绩高于上一次成绩,则输出该成绩,并更新状态保存当前成绩。
将计算得到的最高分数数据流写入 Kafka 主题 "scoreOutput"。
在控制台打印最高分数数据流。made by bin*/
case class Score(name: String, course: String, score: Double, timestamp: Long)
object KafkaTest {
def main(args: Array[String]): Unit = {
// 1.创建流处理执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2.设置Kafka所需的参数
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
// 3.从Kafka中获取数据
val stream = env.addSource(new FlinkKafkaConsumer[String]("scoreInput",new SimpleStringSchema(),properties))
// 4.转换成样例类类型
val dataStream = stream
.map(data => {
val arr = data.split(" ")
Score(arr(0), arr(1), arr(2).toInt,arr(3).toLong)
})
// 5.进行流处理
val maxScoreStream = dataStream
.keyBy(_.name) // 按照姓名进行分区
.flatMap(new MaxScore())
.map(data => data.toString)
// 6.设置Kafka输出
maxScoreStream.addSink( new FlinkKafkaProducer[String]("localhost:9092", "scoreOutput", new SimpleStringSchema()))
// 7.在Console中输出
maxScoreStream.print()
env.execute("Test3")
}
}
class MaxScore() extends RichFlatMapFunction[Score, (String, String, Int)]{
// 定义状态,保存上一次的分数值
private var lastTempState: ValueState[Int] = _
// 使用open函数创建state变量
override def open(parameters: Configuration): Unit = {
// 获取StateDescriptor
val lastScoreDescriptor = new ValueStateDescriptor[Int]("lastTemp",classOf[Int])
// 通过RuntimeContext注册StateDescriptor,同时StateDescriptor以状态state的名字和存储的数据类型为参数
lastTempState = getRuntimeContext.getState[Int](lastScoreDescriptor)
}
/* override def flatMap(value: Score, out: Collector[(String, String, Int)]): Unit = {
// 获取上一次的成绩
val lastScore = lastTempState.value()
// 跟最新输入的成绩做比较
val scoreDiff = (value.score - lastScore)
if(scoreDiff > 0)
out.collect(value.name, value.course, value.score)
// 更新状态
lastTempState.update(value.score)
}*/
override def flatMap(value: Score, out: Collector[(String, String, Int)]): Unit = {
// 获取上一次的成绩
val lastScore = lastTempState.value()
// 跟最新输入的成绩做比较
val scoreDiff = value.score - lastScore
if(scoreDiff > 0)
out.collect(value.name, value.course, value.score.toInt)
// 更新状态
lastTempState.update(value.score.toInt)
}
}
运行程序后
接着:不要隔得久
1.打开一个终端,输入下面命令启动Zookeeper服务:
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties
2.打开第二个终端,然后输入下面命令启动Kafka服务:
cd /usr/local/kafka
./bin/kafka-server-start.sh config/server.properties
3.在Kafka安装目录下,输入命令:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic scoreOutput
4.重新开启一个窗口,在Kafka安装目录下,输入命令:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic scoreInput
此终端作为数据的输入终端。
5.输入完命令,回车,光标会移动到下一行等待数据输入。按照要求输入数据,在输出终端会看到数据的处理结果。
6.输入示例数据
>Alice Math 80 1617913200
>Bob English 75 1617913220
>Alice Math 85 1617913240
>Bob English 78 1617913260
>Alice Math 77 1617913280
>Bob English 65 1617913300
截图:
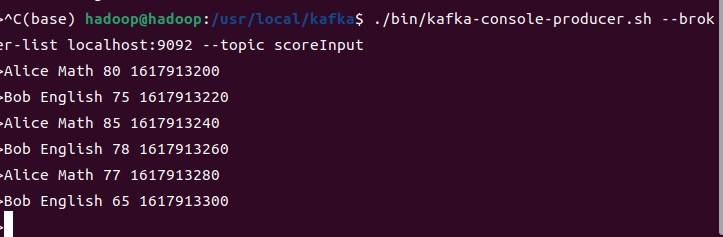
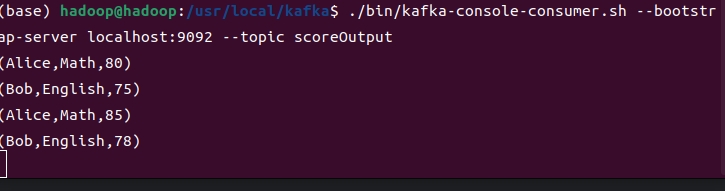
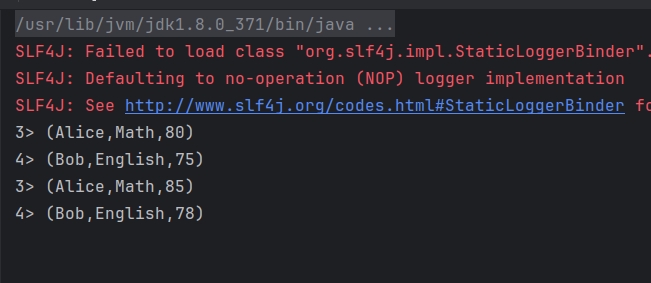
4-窗口内数据统计代码
package com.huangbin.Windowed_Data_Analytis
import java.util.Properties
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, FlinkKafkaProducer, FlinkKafkaProducer011}
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
case class Score(name: String, course: String, score: Double, timestamp: Long)
object Test4 {
def main(args: Array[String]): Unit = {
// 1.创建流处理执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2.设置Kafka所需的参数
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
// 3.从Kafka中获取数据
val stream = env.addSource(new FlinkKafkaConsumer[String]("scoreInput", new SimpleStringSchema(), properties))
// 4.转换成样例类类型
val dataStream = stream
.map(data => {
val arr = data.split(" ")
Score(arr(0), arr(1), arr(2).toDouble, arr(3).toLong)
})
// 5. 对读取的数据进行处理
val resultStream = dataStream
.keyBy(_.name)
.timeWindow(Time.seconds(20))
.reduce(new ReduceFunction[Score] {
override def reduce(value1: Score, value2: Score): Score = {
if (value1.score > value2.score)
Score(value1.name, value1.course, value1.score, value1.timestamp)
else
Score(value2.name, value2.course, value2.score, value2.timestamp)
}
})
.map(data => data.toString)
// 6.设置Kafka输出
resultStream.addSink( new FlinkKafkaProducer[String]("localhost:9092", "scoreOutput", new SimpleStringSchema()))
// 7.在Console中输出
resultStream.print()
env.execute("Test4")
}
}
接着:
1.打开一个终端,输入下面命令启动Zookeeper服务:
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties
2.打开第二个终端,然后输入下面命令启动Kafka服务:
cd /usr/local/kafka
./bin/kafka-server-start.sh config/server.properties
3.在Kafka安装目录下,输入命令:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic scoreOutput
4.重新开启一个窗口,在Kafka安装目录下,输入命令:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic scoreInput
此终端作为数据的输入终端。
5.输入完命令,回车,光标会移动到下一行等待数据输入。按照要求输入数据,在输出终端会看到数据的处理结果。
输入示例数据
>Jack Math 86 1602727715
>Jack Algorithm 81 1602727716
>Tom Database 99 1602727721
第1s
 第20s后我有新数据进来了,统计
第20s后我有新数据进来了,统计
5-窗口与水位线基本操作代码
package com.huangbin.Watermark
import java.text.SimpleDateFormat
import java.util.Properties
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, TimestampAssigner, TimestampAssignerSupplier, Watermark, WatermarkGenerator, WatermarkGeneratorSupplier, WatermarkOutput, WatermarkStrategy}
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, FlinkKafkaProducer, FlinkKafkaProducer011}
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
case class Score(name: String, course: String, score: Double, timestamp: Long)
object Test5 {
def main(args: Array[String]): Unit = {
// 1.创建流处理执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2.设定时间特性为事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 3.设置Kafka所需的参数
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
// 4.从Kafka中获取数据
val stream = env.addSource(new FlinkKafkaConsumer[String]("scoreInput", new SimpleStringSchema(), properties))
// 5.转换成样例类类型
val dataStream = stream
.map(data => {
val arr = data.split(" ")
Score(arr(0), arr(1), arr(2).toDouble, arr(3).toLong)
})
// 为数据流分配时间戳和水位线
val newWatermarkStream = dataStream.assignTimestampsAndWatermarks(new NewWatermarkStrategy)
// 6.对读取的数据进行处理
val resultDataStream = newWatermarkStream
.keyBy(0)
// 设置窗口
.timeWindow(Time.seconds(15))
// 设置窗口30秒的延迟时间
.allowedLateness(Time.seconds(30))
.reduce(new ReduceFunction[Score] {
override def reduce(value1: Score, value2: Score): Score = {
if (value1.score > value2.score)
Score(value1.name, value1.course, value1.score, value1.timestamp)
else
Score(value2.name, value2.course, value2.score, value2.timestamp)
}
})
.map(data => data.toString)
// 7.设置Kafka输出
resultDataStream.addSink(new FlinkKafkaProducer[String]("localhost:9092", "scoreOutput", new SimpleStringSchema()))
// 8.在Console中输出
resultDataStream.print("test5")
env.execute("Test5")
}
class NewWatermarkStrategy extends WatermarkStrategy[Score] {
override def createTimestampAssigner(context: TimestampAssignerSupplier.Context): TimestampAssigner[Score] = {
new SerializableTimestampAssigner[Score] {
// 从数据中获取时间戳
override def extractTimestamp(element: Score, recordTimestamp: Long): Long = {
element.timestamp * 1000L
}
}
}
override def createWatermarkGenerator(context: WatermarkGeneratorSupplier.Context): WatermarkGenerator[Score] = {
new WatermarkGenerator[Score] {
// 允许数据乱序延迟为3秒
val maxOutOfOrderness = 3000L
var currentMaxTimestamp = 0L
var watermark: Watermark = _
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
override def onEvent(event: Score, eventTimestamp: Long, output: WatermarkOutput): Unit = {
// 获取最大的时间戳
currentMaxTimestamp = Math.max(eventTimestamp, currentMaxTimestamp)
// 设置新的Watermark
watermark = new Watermark(currentMaxTimestamp - maxOutOfOrderness)
output.emitWatermark(watermark)
println((event.name, event.course, event.score) + "timestamp:" + event.timestamp * 1000L + "|" + format.format(event.timestamp * 1000L) + ","
+ currentMaxTimestamp + "|" + format.format(currentMaxTimestamp) + "," + watermark.toString)
}
override def onPeriodicEmit(output: WatermarkOutput): Unit = {
}
}
}
}
}
接着:
1.打开一个终端,输入下面命令启动Zookeeper服务:
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties
2.打开第二个终端,然后输入下面命令启动Kafka服务:
cd /usr/local/kafka
./bin/kafka-server-start.sh config/server.properties
3.在Kafka安装目录下,输入命令:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic scoreOutput
4.重新开启一个窗口,在Kafka安装目录下,输入命令:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic scoreInput
此终端作为数据的输入终端。
5.输入完命令,回车,光标会移动到下一行等待数据输入。按照要求输入数据,在输出终端会看到数据的处理结果。
输入示例数据
Jack Math 86 1602727715
Jack Algorithm 81 1602727716
Jack Flink 90 1602727717
Rose Math 77 1602727718
Jack Database 63 1602727719
Rose Algorithm 51 1602727720
Tom Database 73 1602727721
Tom Datastructure 62 1602727722
Rose Database 61 1602727723
Rose Datastructure 43 1602727724
Tom Math 57 1602727725
Jack Datastructure 51 1602727726
Tom Algorithm 43 1602727727
依次输入
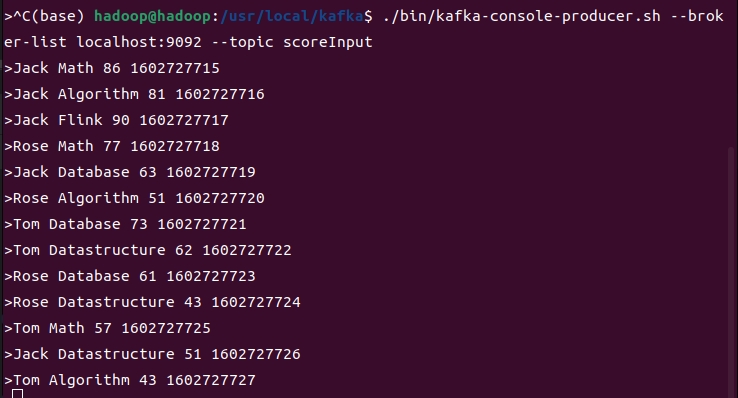

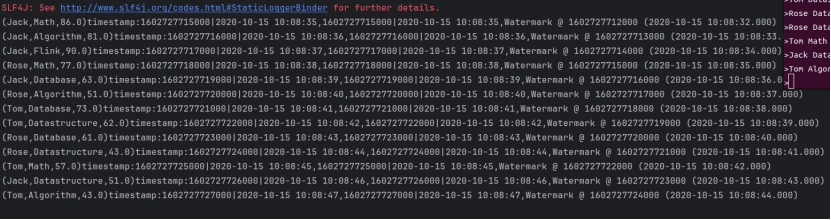 在Kafka输出终端无任何输出。 当输入下一个时间戳的数据
在Kafka输出终端无任何输出。 当输入下一个时间戳的数据

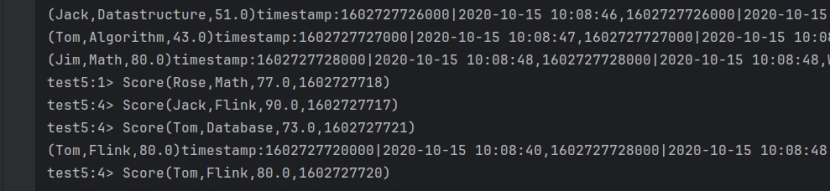
终端输出结果
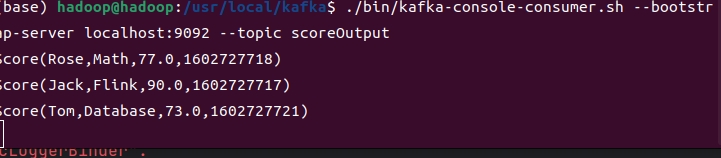
 所以此时的Watermark为1602727725,窗口的大小为15秒,所以窗口[1602727710, 1602727725)开始执行,区间是左闭右开,不会处理时间戳为1602727725的数据,同时代码里设置窗口延迟关闭的时间为30秒,所以即使该窗口输出显示数据,但依旧开放。所以我们输入旧数据,测试一下,假设延迟
所以此时的Watermark为1602727725,窗口的大小为15秒,所以窗口[1602727710, 1602727725)开始执行,区间是左闭右开,不会处理时间戳为1602727725的数据,同时代码里设置窗口延迟关闭的时间为30秒,所以即使该窗口输出显示数据,但依旧开放。所以我们输入旧数据,测试一下,假设延迟
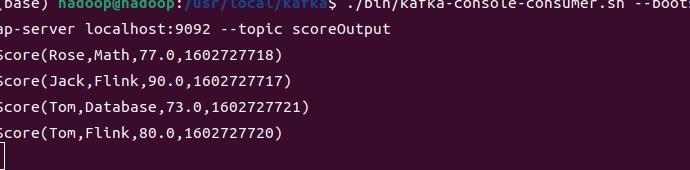
数据还是进行了更新
















 307
307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











