







1.如何定位元素
1.1 直接提取
soup('标签名')
soup.find('标签名') --直接是值
soup.find_all('标签名') --列表
1.2 CSS定位器
(1)class定位元素
soup.select(div.属性)
(2)id定位
soup.select(div#属性)
(3)嵌套定位
soup.select(div > ul > li)
举例
sentence = soup.select('div.left > div.sons > div.cont')
#提取出来的tag组成了一个列表,即sentence是一个列表,它里面有50个tag数据
print(len(sentence))
print(type(sentence[0]))

2. 如何提取文本
上面方法提取的结果都是tag类型,因此提取文本都是从tag中提取。
tag.get_text()
3. 如何提取属性
tag.get('属性名')
4. 实例
以爬取古诗词网名句栏目前5页(共250句)及其各名句所链接的古诗词原文(5*50=250首)为例
https://so.gushiwen.org/mingju/
import requests
import re
from lxml import etree
from bs4 import BeautifulSoup
import time
#函数1:请求网页
def page_def(url,ua):
resp = requests.get(url,headers = ua)
#print("请求状态:%d"%(resp.status_code))
html = resp.content.decode('utf-8')
return html
#函数2:解析网页
def info_def(html):
soup = BeautifulSoup(html,'html.parser') #html.parser 为解析器
title = soup('title')
#soup.find('标签名') --直接是值
#soup.find_all('标签名') --列表
sentence = soup.select('div.left > div.sons > div.cont > a:nth-of-type(1)')
#提取出来的tag组成了一个列表,即sentence是一个列表,它里面有50个tag数据
poet = soup.select('div.left > div.sons > div.cont > a:nth-of-type(2)')
sentence_list=[]
href_list=[]
for i in range(len(sentence)):
temp = sentence[i].get_text()+ "---"+poet[i].get_text()
sentence_list.append(temp)
href = sentence[i].get('href')
href_list.append("https://so.gushiwen.org"+href)
return [href_list,sentence_list]
#函数3:写入文本文件
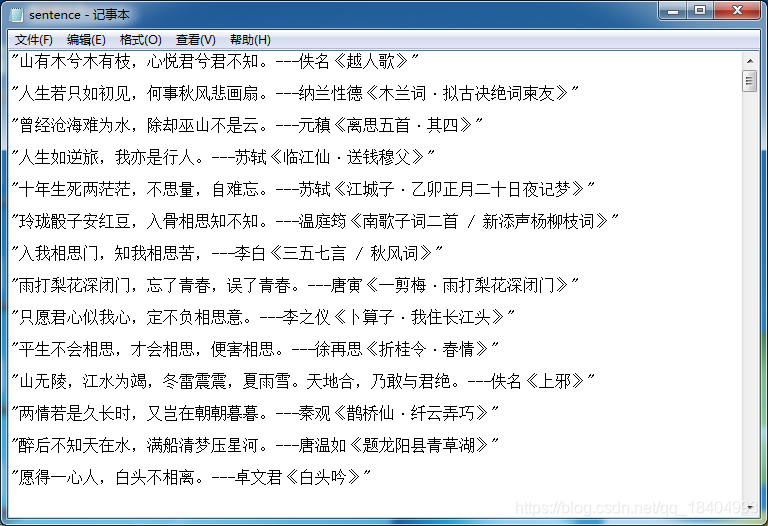
def txt_def(info_list):
import json
with open(r'C:\Users\HP\Desktop\sentence.txt','a',encoding='utf-8') as df:
for one in info_list[1]:
df.write(json.dumps(one,ensure_ascii=False)+'\n\n')
#子网页处理函数:进入并解析子网页/请求子网页
def request_sub_page(info_list):
subpage_urls = info_list[0]
#print(subpage_urls)
ua = {'User-Agent':'User-Agent:Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'}
sub_html = []
for url in subpage_urls:
html = page_def(url,ua)
sub_html.append(html)
return sub_html
#子网页处理函数:解析子网页,爬去诗句内容
def sub_page_def(sub_html):
poem_list=[]
for html in sub_html:
soup = BeautifulSoup(html,'html.parser')
poem = soup.select('div.left > div.sons > div.cont > div.contson')
poem = poem[0].get_text()
poem_list.append(poem.strip())
return poem_list
#子网页处理函数:保存诗句到txt
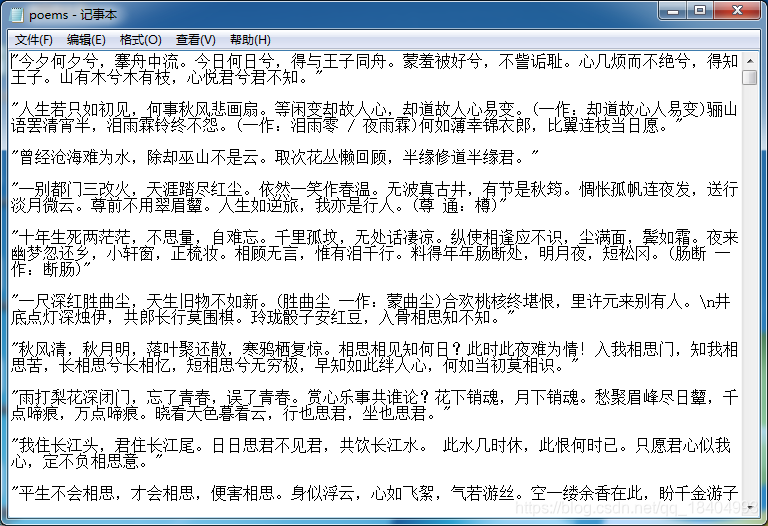
def sub_page_save(poem_list):
import json
with open(r'C:\Users\HP\Desktop\poems.txt','a',encoding='utf-8') as df:
for one in poem_list:
df.write(json.dumps(one,ensure_ascii=False)+'\n\n')
if __name__ == '__main__':
print("**************开始古诗文网站爬虫********************")
ua = {'User-Agent':'User-Agent:Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'}
for i in range(1,6):
url = 'https://so.gushiwen.org/mingju/default.aspx?p=%d&c=&t='%(i)
time.sleep(1)
html = page_def(url,ua)
info_list = info_def(html)
txt_def(info_list)
#print(info_list)
#开始处理子网页
print("开始解析第%d"%(i)+"页")
#开始解析名句子网页
sub_html = request_sub_page(info_list)
poem_list = sub_page_def(sub_html)
sub_page_save(poem_list)
print("****************爬取完成***********************")
print("共爬取%d"%(i*50)+"个古诗词名句,保存在如下路径:C:\\Users\\HP\\Desktop\\sentence.txt")
print("共爬取%d"%(i*50)+"个古诗词,保存在如下路径:C:\\Users\\HP\\Desktop\\poem.txt")















 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









