



作为一名专注于本地化大模型应用的开发者,深知从模型部署到实现工具调用能力的全流程复杂度极高 —— 既要完成推理引擎配置,还需处理外部服务接口适配,更要实现模型与工具的联动逻辑。OpenStation 的模型服务部署、MCP 工具、Agent 管理三个模块,恰好形成一套完整的技术闭环,让搭建具备工具调用能力的 AI 智能体具备可落地性。本文将从技术实操角度,详细介绍这三个模块的协同逻辑,并通过实例展示完整搭建过程。
一、模型服务部署:Agent的“大脑”搭建
模型服务是Agent的基础算力单元,相当于智能体的“大脑”。OpenStation的模型服务部署模块,解决了本地化部署中最核心的“模型 - 资源 - 引擎”匹配问题,让开发者无需深入底层优化就能快速上线高性能推理服务。
部署流程的技术细节
部署一个可用的模型服务,核心是实现“模型来源 - 节点资源 - 推理引擎”的三角匹配。由于个人本地资源有限,本文以部署 Qwen3-0.6B较小的蒸馏模型为例,步骤拆解如下:
-
模型来源选择:支持从平台模型库下载或本地路径上传模型文件(需确保文件结构完整)。本地部署时,个人更倾向于从模型库选择,避免因文件缺失导致部署失败。
-
节点资源评估:平台会自动检测节点的CPU核心数、GPU型号(如NVIDIA A100-PCIE-40GB)、显存总量,并与模型需求(如Qwen3-0.6B 需约3GB显存)匹配。多节点部署时,平台会采用张量并行 + 流水线并行的分布式策略。
-
推理引擎自动适配:根据节点配置,平台会按预设策略选择引擎(如下表所示),这对开发者极为友好 —— 无需记忆不同引擎的适用场景:
节点数
节点类型
推理引擎
核心优势
1
CPU
vLLM(CPU-only)
纯 CPU 环境下的高效推理
1
GPU
SGLang(GPU)
单卡环境低延迟响应
≥2
GPU
vLLM(GPU)
分布式部署,支持张量 / 流水线并行
-
高级参数调优:若需自定义,可在 “高级设置” 中修改推理引擎(如GPU节点强制用vLLM替代SGLang)或添加启动参数(如--dtype bf16节省显存、--max-num-batched-tokens 8192提升并发)。这些参数直接影响推理性能,建议根据模型大小和业务负载调整。
实例管理与弹性扩展
模型服务部署后,通过模型服务详情中新增或者删除实例实现弹性扩缩容:
-
新增实例:当请求量激增时,在服务详情页点击“新增实例”,选择空闲节点,平台会自动复用原部署配置(模型路径、引擎参数),新实例上线后立即纳入负载均衡池,不影响现有服务。
-
删除实例:负载降低时,删除冗余实例释放资源,若删除最后一个实例,服务将停止但配置保留(便于后续重启)。
对开发者而言,这种弹性能力意味着可以根据业务峰谷动态调整资源,避免算力浪费。已经部署好的Qwen3-0.6B模型服务如下图:
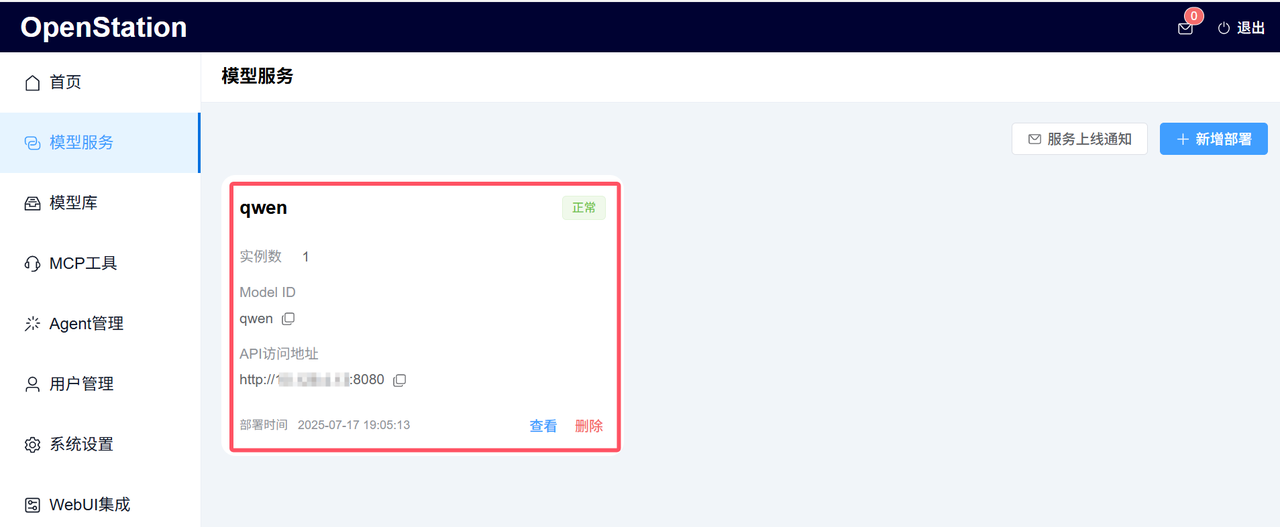
二、Mcp工具:Agent的 “工具库” 搭建
MCP 工具是 OpenStation 连接外部服务的中间层,相当于 Agent 的 “工具库”。它解决了本地化大模型面临的核心难题 —— 如何让模型便捷调用外部 API(如天气查询、代码仓库、Web 搜索等),无需开发者重复开发适配逻辑。
预置工具的快速开通
平台内置了Tavily(网络检索)、Github(在线代码管理平台)、彩云天气(天气数据服务)等预置工具,且开通流程标准化:
以开通Tavily工具为例(提供实时的网络信息访问和领域特定的搜索,是很多Agent的基础能力):
-
在“MCP工具”页面找到 “Tavily”卡片,点击“开通”;
-
按提示获取 API Key(根据页面提示,注册账户,获取个人API Key);
-
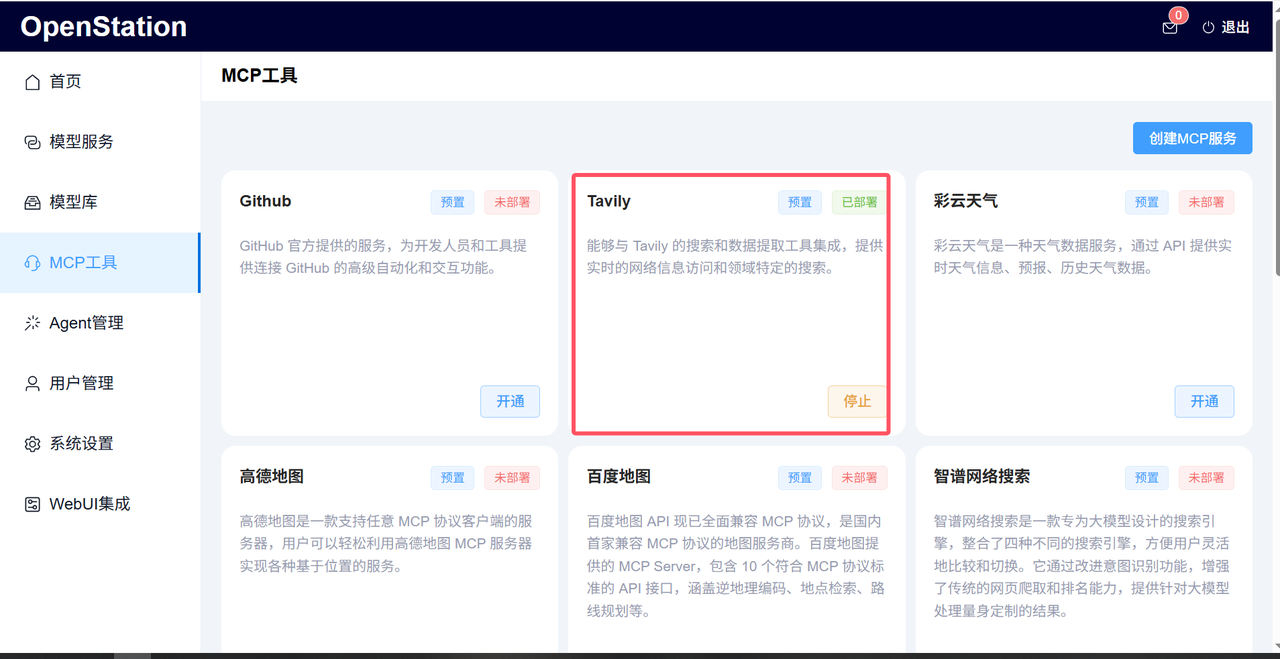
弹窗确认后,工具状态变为“已部署”,此时可在“工具”标签页查看其接口定义(如tavily-extract方法需传入urls参数,类型为字符串,如"https://example.com/article")。
技术细节上,预置工具的接口已与OpenAI函数调用格式对齐,返回结果结构化(JSON),确保模型能正确解析。这对开发者而言,意味着无需手动处理格式转换,可直接调用。预置的Tavily工具部署完成后如下图:
自定义工具的灵活创建
例如,若需创建获取本地时间的工具,可通过 “创建MCP服务” 自定义工具:
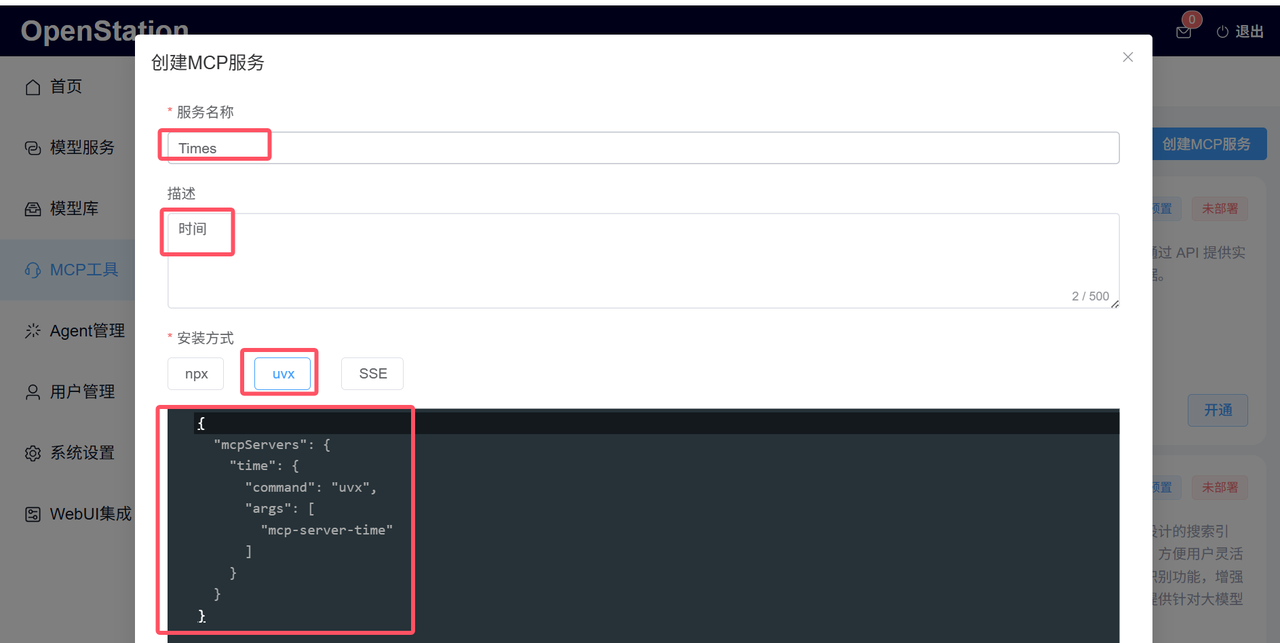
1. 基础信息配置:
- 服务名称:需唯一(如 “Time”);
- 描述:简要说明功能(如 “时间”);
- 安装方式:根据服务类型选择(npx 适用于 Node.js 工具,uvx 适用于 Python 工具,SSE 适用于流式响应服务)。
- 服务配置定义:需按平台规范填写JSON配置,示例如下(创建时间工具):
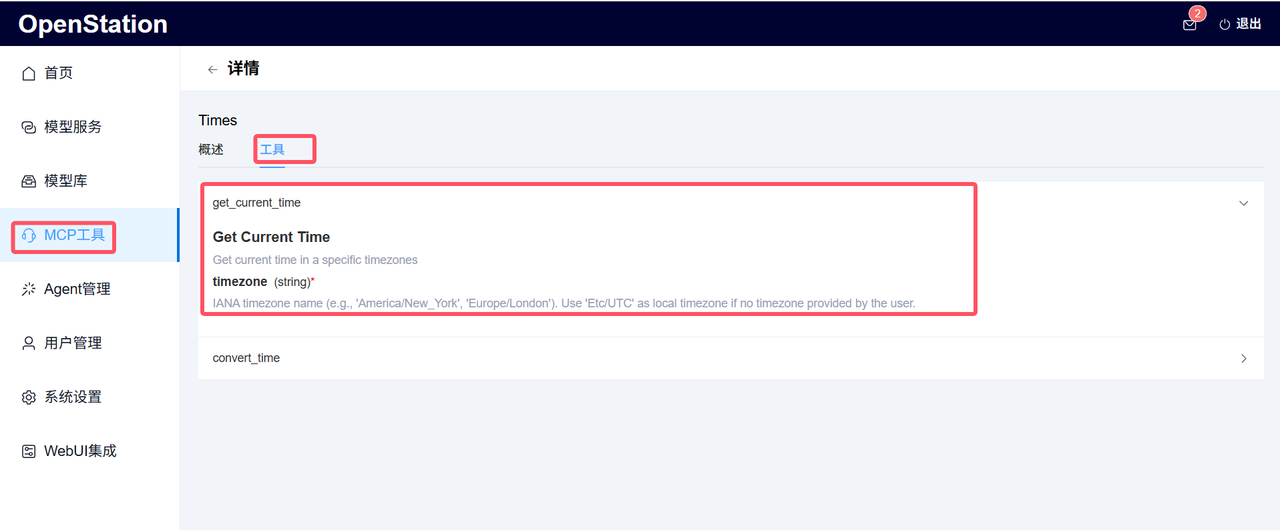
2. 部署与验证:点击“部署”后,平台会在节点上启动服务,并自动检测端口连通性。部署成功后,可在“工具”页查看自定义方法(如get_current_time),如下图所示:
工具的生命周期管理
Mcp预置工具为防止误操作和降低风险成本,仅支持开通和停止服务操作,不支持删除操作;
Mcp自定义工具支持全生命周期管理:
-
停止服务:释放资源(如临时不需要 Time 工具时),后续可重新部署;
-
编辑配置:未部署状态可修改所有参数,已部署状态仅能修改名称和描述(需改核心配置需先停止);
-
删除工具:彻底移除配置(不可恢复),建议删除前备份配置 JSON。
三、Agent 管理:将 “大脑” 与 “工具库” 联动
Agent管理模块的核心作用,是将已部署的模型服务(大脑)与MCP工具(工具库)绑定,使模型具备 “自主决策调用工具” 的能力 —— 这正是智能体的核心竞争力。
Agent 的创建流程
创建 Agent 需依赖两个前置条件:① 至少 1 个已部署的模型服务;② 至少 1 个已部署的Mcp工具。本次以创建能够提供天气查询、网络检索和显示时间的智能体服务为例,具体步骤如下:
1. 进入“Agent 管理”,点击 “部署 Agent”;
2. 填写核心信息:
-
名称:如 “Weather-Search-Time”(此处以所提供功能命名);
-
选择模型:需从已部署的模型中选取(如之前部署的Qwen模型);
-
选择工具:可多选已部署的 Mcp 工具(如自定义“Time”工具 + 预置的“Tavily”工具 + 预置的“彩云天气”工具);
-
提示词:支持填写所需的Prompt(非必填);
-
描述:说明 Agent 的应用场景(如 "提供天气查询、网络检索和时间的智能体")。
-
最后点击“部署”,平台会自动完成Agent服务部署并生成API服务地址等信息,核心信息如下图所示:
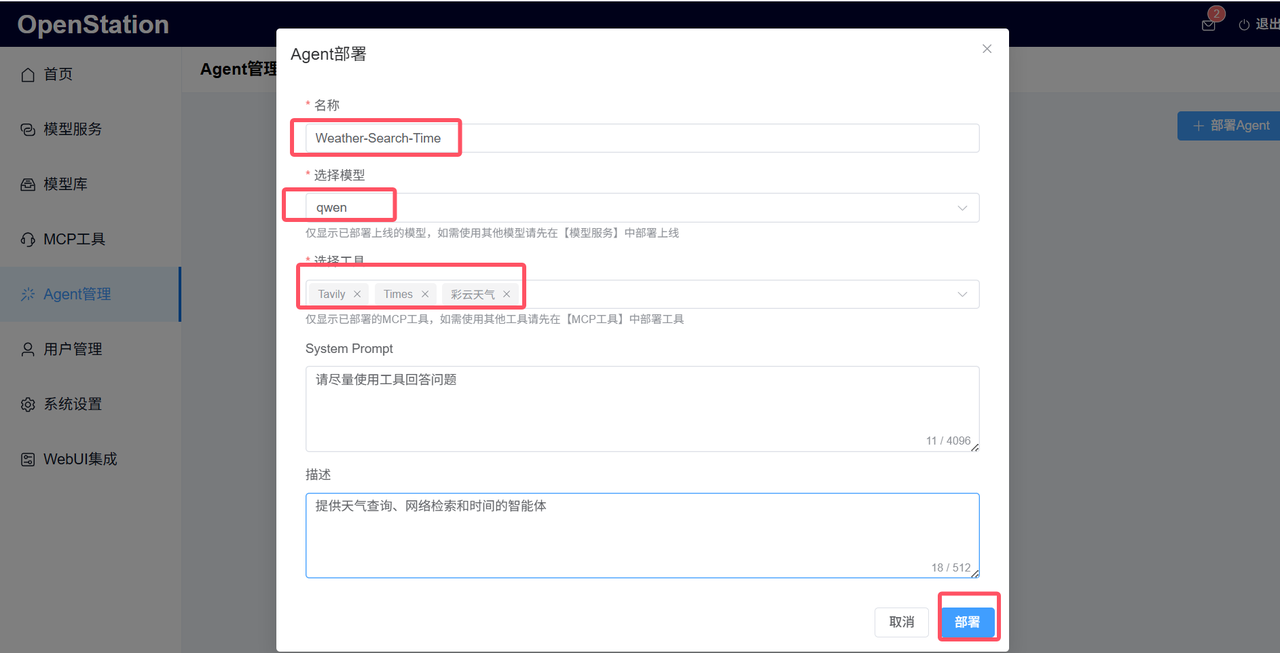
“Weather-Search-Time”智能体部署完成后如下图所示:
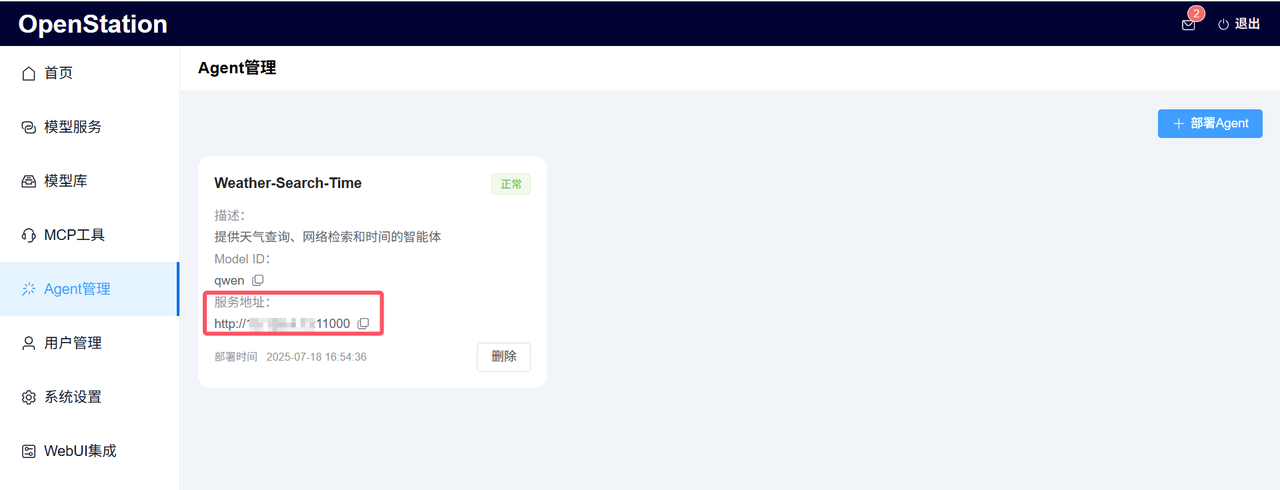
Agent 对接客户端及验证
部署完成后,Agent的使用与普通模型服务类似,但增加了工具调用能力:
-
服务地址:从部署的Agent详情页获取(如http://部署节点IP地址:11000),兼容 OpenAI API 格式,可直接接入 ChatBox 等客户端,如下图所示;
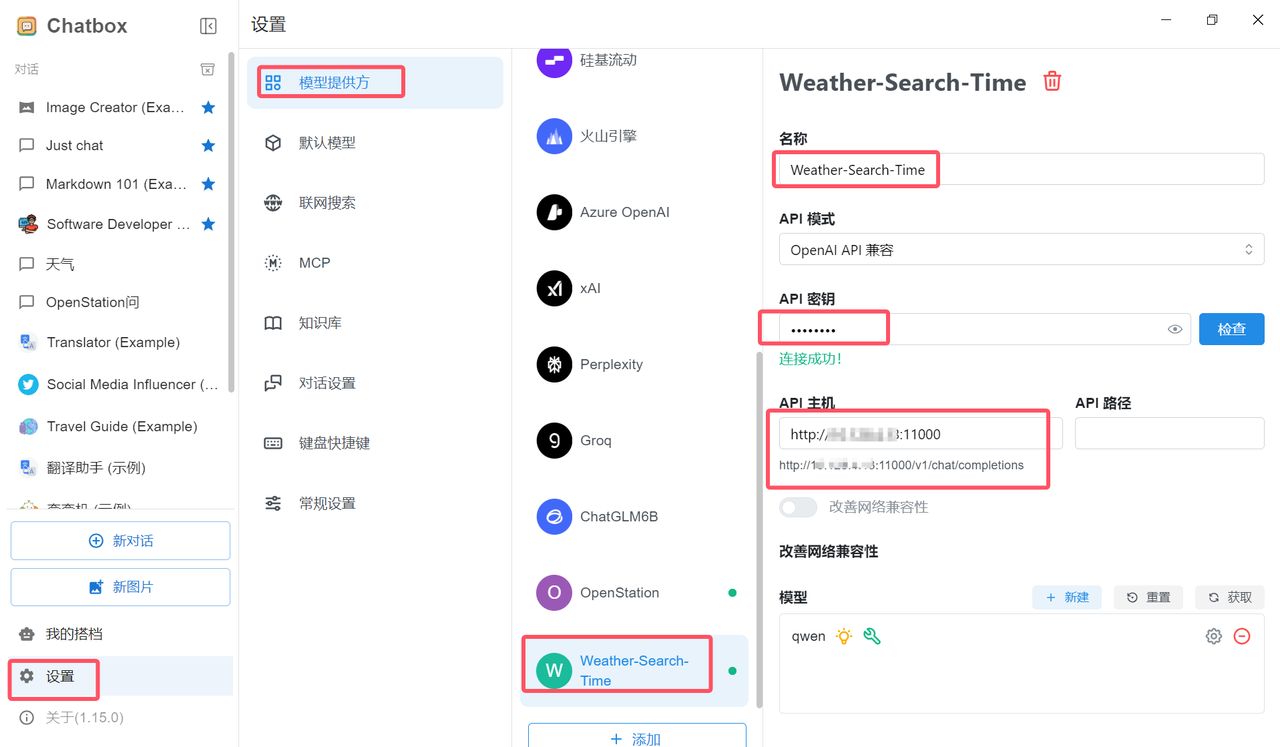
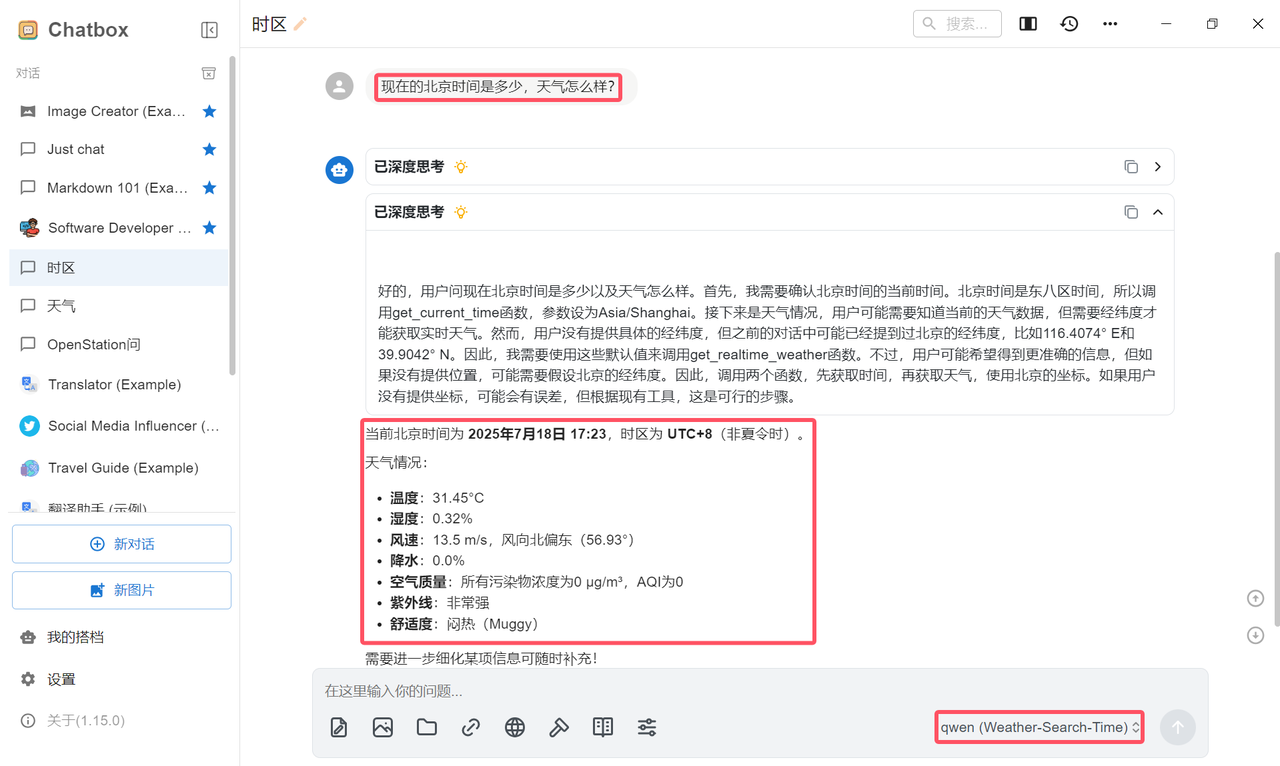
在 ChatBox 中完成“Weather-Search-Time”智能体服务配置后(须填写API 地址 + API Key),即可正式体验智能体,如下图所示:
四、部署指南:如何快速上手
OpenStation 部署步骤
项目地址:https://github.com/fastaistack/OpenStation
1. 在线安装(支持Ubuntu22.04 / 20.04 / 18.04系列及Centos7系列)
curl -O https://fastaistack.oss-cn-beijing.aliyuncs.com/openstation/openstation-install-online.sh
bash openstation-install-online.sh --version 0.6.6也可直接下载在线安装包(openstation-pkg-online-v0.6.6.tar.gz),上传至Linux服务器后执行:
tar -xvzf openstation-pkg-online-v0.6.6.tar.gz
cd openstation-pkg-online-v0.6.6/deploy
bash install.sh true2. 离线安装(仅支持Ubuntu 22.04.2/20.04.6/18.04.6)
点击「离线 OpenStation 安装包下载」,参考官方离线安装文档。
部署完成后,登录页面如下:
结论:技术价值总结
对开发者而言,OpenStation平台的模型服务部署、MCP工具和Agent管理形成了完整的Agent开发闭环:
-
模型服务部署:解决了本地化推理的性能与弹性问题,支持从单机到分布式的平滑扩展;
-
MCP工具:标准化外部服务接入,降低工具适配成本,预置 + 自定义结合满足多样化需求;
-
Agent管理:简化模型与工具的联动逻辑,让开发者聚焦业务场景,而非底层集成。
这种模块化设计的优势在于——无需重复开发基础组件,能快速将本地化大模型从“对话能力”升级为“实用智能体”,这正是OpenStation在本地化部署领域的核心竞争力。

















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









