







文章目录
Python爬虫(十)——股票定向爬虫
- 目标:获取上交所和深交所的所有股票的名称和交易信息
- 输出:保存到文件中
- 技术路线:requests-bs4-re
候选网站
新浪股票:http://finance.sina.com.cn/stock/
百度股票:http://gupiao.baidu.com/stock/
选择
- 选取原则:股票信息静态存在于HTML页面中,非js代码生成,没有Robots协议限制。
- 选取方法:通过开发者模式或查看源代码。
- 选取心态:多找几个网站尝试。
因此我们观察新浪的网页代码,发现股票的信息都是引用的js代码,然后百度股票已经关闭了网页版。所以我们在查阅了其他各种股票网站以后选择了中财网这个网站(http://quote.cfi.cn/)。
程序的结构设计
步骤
- 从东方财富网获取股票列表
- 根据股票列表逐个到中财网获取个股信息
- 将结果存储到文件
方法
getHTMLText(url, code=‘utf-8’)
在这里我们预设encoding为’utf-8’从而节省判断编码的时间。
代码:
def getHTMLText(url, code='utf-8'):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = code # 判断编码时间会消耗很多时间,所以我们提前去网站上了解编码类型
return r.text
except:
return ""
getStockList(lst, stockUrl)
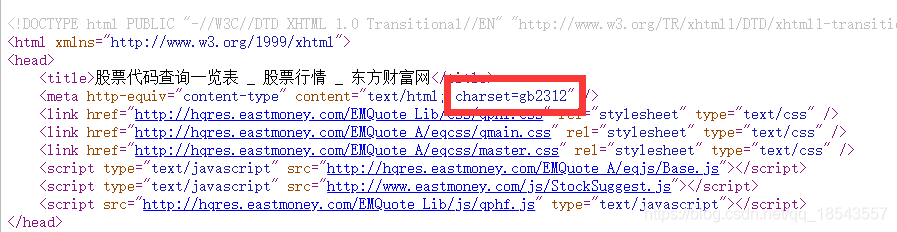
我们先得到股票列表。通过观察网页源代码,我们发现上证和深证的股票编码可以用以下的正则表达式表示:
r'[s][hz]\d{6}'
然后我们查询网站的编码类型:
代码:
def getStockList(lst, stockUrl):
html = getHTMLText(stockUrl, 'GB2312') # 填上在网页代码中看到的编码方式
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r'[s][hz]\d{6}', href)[0][2:])
except:
continue
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5266
5266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









