







前言
Kafka,作为目前在大数据领域应用最为广泛的消息队列,其内部实现和设计有很多值得深入研究和分析的地方,使用kafka首先需要接触到producer的开发,然后是consumer开发,自0.8.2.x版本以后,kafka提供了java 版本的producer以代替以前scala版本的producer,下面进行producer的解析。
Producer 概要设计
发送简略流程图

KafkaProducer首先使用序列化器将需要发送的数据进行序列化,让后通过分区器(partitioner)确定该数据需要发送的Topic的分区,kafka提供了一个默认的分区器,如果消息指定了key,那么partitioner会根据key的hash值来确定目标分区,如果没有指定key,那么将使用轮询的方式确定目标分区,这样可以最大程度的均衡每个分区的消息,确定分区之后,将会进一步确认该分区的leader节点(处理该分区消息读写的主节点),消息会进入缓冲池进行缓冲,然后等消息到达一定数量或者大小后进行批量发送
Producer 程序开发
- producer同步发送消息
package com.huawei.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* @author: xuqiangnj@163.com
* @date: 2019/4/15 21:59
* @description:
*/
public class SynKafkaProducer {
public static final Properties props = new Properties();
static {
props.put("bootstrap.servers", "192.168.142.139:9092");
// 0:producer不会等待broker发送ack
// 1:当leader接收到消息后发送ack
// -1:当所有的follower都同步消息成功后发送ack
props.put("acks", "-1");//
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
}
final KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);
private String topicName;
public SynKafkaProducer(String topicName) {
this.topicName = topicName;
}
public RecordMetadata send(String key, String value) {
RecordMetadata recordMetadata = null;
try {
recordMetadata = kafkaProducer.send(new ProducerRecord<String, String>(topicName,
key, value)).get();//get方法将阻塞,直到返回结果RecordMetadata
} catch (InterruptedException e) {
//进行日志记录或者异常处理
} catch (ExecutionException e) {
//进行日志记录或者异常处理
}
return recordMetadata;
}
public void close() {
if (kafkaProducer != null) {
kafkaProducer.close();
}
}
public static void main(String[] args) {
SynKafkaProducer synKafkaProducer = new SynKafkaProducer("kafka-test");
for (int i = 0; i < 10; i++) {
RecordMetadata metadata = synKafkaProducer.send(String.valueOf(i), "This is " + i +
" message");
System.out.println("TopicName : " + metadata.topic() + " Partiton : " + metadata
.partition() + " Offset : " + metadata.offset());
}
synKafkaProducer.close();
}
}
运行结果
- producer异步发送消息
package com.huawei.kafka.producer;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* @author: xuqiangnj@163.com
* @date: 2019/4/15 21:59
* @description:
*/
public class AsynKafkaProducer {
public static final Properties props = new Properties();
static {
props.put("bootstrap.servers", "192.168.142.139:9092");
// 0:producer不会等待broker发送ack
// 1:当leader接收到消息后发送ack
// -1:当所有的follower都同步消息成功后发送ack
props.put("acks", "1");//
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
}
final KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);
private String topicName;
public AsynKafkaProducer(String topicName) {
this.topicName = topicName;
}
public void send(String key, String value) {
kafkaProducer.send(new ProducerRecord<String, String>(topicName,
key, value), new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null){
System.out.println("TopicName : " + metadata.topic() + " Partiton : " + metadata
.partition() + " Offset : " + metadata.offset());
}
else {
//进行异常处理
}
}
});
}
public void close() {
if (kafkaProducer != null) {
kafkaProducer.close();
}
}
public static void main(String[] args) {
AsynKafkaProducer synKafkaProducer = new AsynKafkaProducer("kafka-test");
for (int i = 0; i < 10; i++) {
synKafkaProducer.send(String.valueOf(i), "This is " + i + " message");
}
try {
Thread.sleep(2000);//这里阻塞两秒钟 等待回调函数打印结果
} catch (InterruptedException e) {
e.printStackTrace();
}
synKafkaProducer.close();
}
}
运行结果

同步发送消息
优点:可以保证每条消息准确无误的写入了broker,对于立即需要发送结果的情况非常适用,在producer故障或者宕机的情况也可以保证结果的正确性
缺点:由于同步发送需要每条消息都需要及时发送到broker,没有缓冲批量操作,性能较低
异步发送消息
优点:可以通过缓冲池对消息进行缓冲,然后进行消息的批量发送,大量减少了和broker的交互频率,性能极高,可以通过回调机制获取发送结果
缺点:在producer直接断电或者重启等故障,将有可能丢失消息发送结果,对消息准确性要求很高的场景不适用
producer使用非常简单
1.配置producer参数
2.构造ProducerRecord消息
3.调用send方法进行发送
4.最后关闭producer资源
Producer参数说明
- bootstrap.servers:Kafka群集信息列表,用于连接kafka集群,如果集群中机器数很多,只需要指定部分的机器主机的信息即可,不管指定多少台,producer都会通过其中一台机器发现集群中所有的broker,一般指定3台机器的信息即可,格式为 hostname1:port,hostname2:port,hostname3:port
- key.serializer:任何消息发送到broker格式都是字节数组,因此在发送到broker之前需要进行序列化,该参数用于对ProducerRecord中的key进行序列化
- value.serializer:该参数用于对ProducerRecord中的value进行序列化
kafka默认提供了常用的序列化类,也可以通过实现org.apache.kafka.common.serialization.Serializer实现定义的序列化,在下面说明消息序列化详细列出
- acks:ack具有3个取值 0、1和-1(all)
acks=0:发送消息时,完全不用等待broker的处理结果,即可进行下一次发送,吞吐量最高
acks=-1或all:不仅需要leader broker将消息持久化,同时还需要等待ISR副本(in-sync replica 即与leader节点保持消息同步的副本集合)全部都成功持久化消息后,才返回响应结果,吞吐量最低
ack=1:是前面两个的折中,只需要leader broker持久化后,便响应结果
- buffer.memory:该参数用于设置发送缓冲池的内存大小,单位是字节。默认值33554432KB(32M)
- compression.type:压缩类型,目前kafka支持四种种压缩类型gzip、snappy、lz4、zstd,性能依次递增。默认值none(不压缩)
- retries:重试次数,0表示不进行重试。默认值2147483647
- batch.size:批次处理大小,通常增加该参数,可以提升producer的吞吐量
- linger.ms:发送时延,和batch.size任满足其一条件,就会进行发送
- max.block.ms:当producer缓冲满了之后,阻塞的时间
- max.request.size:控制producer发送请求的大小
- receive.buffer.bytes:读取数据时要使用的TCP接收缓冲区(SO_RCVBUF)的大小。如果值为-1,则将使用OS默认值。默认值32768
- send. buffer.bytes:发送数据时使用的TCP发送缓冲区(SO_SNDBUF)的大小。如果值为-1,则将使用OS默认值。默认值131072
- request.timeout.ms:生产者发送数据时等待服务器返回响应的时间。默认值30000ms
消息分区机制
- 消息分区策略:kafka发送消息到broker之前需要确定该消息的具体分区信息,kafka默认提供分区器,该分区机制为如果在ProducerRecord中指定了key,那么将根据key的值进行hash计算,如果没有则采用轮询方式进行,除此之外,还可以在构造ProducerRecord的时候指定分区信息,Kafka将优先使用指定的分区信息,避免进行计算提升了性能,但是客户端在指定分区信息时需要考虑数据均衡问题。
- 自定义分区机制:可以通过实现org.apache.kafka.clients.producer.Partitioner自定分区策略,在构造KafkaProducer是配置参数partitioner.class为自定义的分区类即可
消息序列化
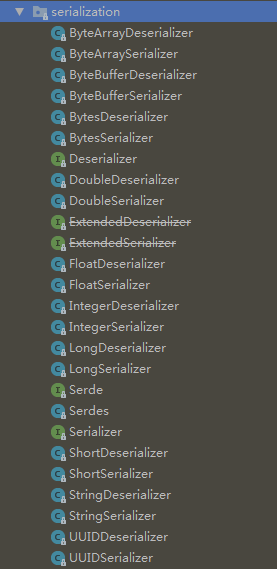
- 默认序列化:下图为kafka实现的默认序列化与反序列器,主要为常用类型序列化器
- 自定义序列化:可以通过org.apache.kafka.common.serialization.Serializer来自定义序列化器
消息压缩
- 压缩类型:kafka压缩类型有5个有效值 none(默认值)、gzip、snappy、lz4、zstd
- 性能比较(压缩比和压缩速率): gzip << snappy << lz4 << zstd
多线程处理
producer实例是线程安全的,在多线程环境,一般有两种使用方式
- 多线程单实例:实现简单,所有线程共用一个KafkaProducer实例,内存开销小(使用一个内存缓冲区),但是如果某个线程发送阻塞或则崩溃将会影响到所有线程的正常发送。
- 多线程多实例:可以使用一对一(即一个线程一个实例)或者M对N(即M个线程共同使用N个实例)两种方式,一对一方式每个线程维护自己的KafkaProducer实例,管理简单,一个线程崩溃,不会影响到其他,M对N方式可以达到资源利用率最大化,根据实际线程数来调整KafkaProducer实例资源的个数,而且在某个KafkaProducer崩溃,还可以切换到其他实例上,总体上更佳,它们相比于单实例需要消耗更多的内存资源并且实现更为复杂。
Producer发送流程源码解析
从上面使用producer代码示例可以看出,producer发送消息就是调用send方法
producer send()方法实现
// 异步向一个 topic 发送数据
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return send(record, null);
}
// 异步向一个 topic 发送数据,并注册回调函数,在回调函数中接受发送响应
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}send() 方法通过重载实现带回调和不带回调的参数,最终调用 doSend() 方法
producer doSend()方法实现
//实现异步发送消息到对应topic
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
//1、检查producer实例是否已关闭,如果关闭则抛出异常
throwIfProducerClosed();
ClusterAndWaitTime clusterAndWaitTime;
try {
//2、确保topic的元数据(metadata)是可用的
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
//3、序列化key
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
//4、序列化value
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
//5、获取分区信息,如果ProducerRecord指定了分区信息就使用该指定分区否则通过计算获取
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
//6、估算消息的字节大小
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
//7、确保消息大小不超过发送请求最大值(max.request.size)或者发送缓冲池发小(buffer.memory)
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
// producer callback will make sure to call both 'callback' and interceptor callback
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
//8、是否使用事务
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);
//9、向 accumulator 中追加数据
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
//10、如果 batch 已经满了,唤醒 sender 线程发送数据
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (ApiException e) {
.............
}
..........
}doSend()方法主要分为10步完成:
1.检查producer实例是否已关闭,如果关闭则抛出异常
2.确保topic的元数据(metadata)是可用的
3.序列化ProducerRecord中的key
4.序列化ProducerRecord中的value
5.确定分区信息,如果构造ProducerRecord指定了分区信息就使用该指定分区否则通过计算获取
6.估算整条消息的字节大小
7.确保消息大小不超过发送请求最大值(max.request.size)或者发送缓冲池发小(buffer.memory),如果超过则抛出异常
8.是否使用事务,如果使用则按照事务流程进行
9.向 accumulator 中追加数据
10.如果 batch 已经满了,唤醒 sender 线程发送数据
发送过程详解
获取 topic 的 metadata 信息
Producer 通过 waitOnMetadata() 方法来获取对应 topic 的 metadata 信息,具体实现如下
//如果元数据Topic列表中还没有该Topic,则将其添加到元数据Topic列表中,并重置过期时间
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long maxWaitMs) throws InterruptedException {
//首先从元数据中获取集群信息
Cluster cluster = metadata.fetch();
//集群的无效topic列表包含该topic那么抛出异常
if (cluster.invalidTopics().contains(topic))
throw new InvalidTopicException(topic);
//否则将topic添加到Topic列表中
metadata.add(topic);
//获取该topic的分区数
Integer partitionsCount = cluster.partitionCountForTopic(topic);
//如果存在缓存的元数据,并且未指定分区的或者在已知分区范围内,那么返回缓存的元数据
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
long begin = time.milliseconds();
long remainingWaitMs = maxWaitMs;
long elapsed;
// Issue metadata requests until we have metadata for the topic and the requested partition,
// or until maxWaitTimeMs is exceeded. This is necessary in case the metadata
// is stale and the number of partitions for this topic has increased in the meantime.
//发出元数据请求,直到主题和所请求分区的元数据出现,或者超过maxWaitTimeMs为止。
//同时可以有效检测元数据已经过期或者主题的分区数量增加。
do {
if (partition != null) {
log.trace("Requesting metadata update for partition {} of topic {}.", partition, topic);
} else {
log.trace("Requesting metadata update for topic {}.", topic);
}
metadata.add(topic);
int version = metadata.requestUpdate();
sender.wakeup();
try {
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
// Rethrow with original maxWaitMs to prevent logging exception with remainingWaitMs
throw new TimeoutException(
String.format("Topic %s not present in metadata after %d ms.",
topic, maxWaitMs));
}
cluster = metadata.fetch();
elapsed = time.milliseconds() - begin;
if (elapsed >= maxWaitMs) {
throw new TimeoutException(partitionsCount == null ?
String.format("Topic %s not present in metadata after %d ms.",
topic, maxWaitMs) :
String.format("Partition %d of topic %s with partition count %d is not present in metadata after %d ms.",
partition, topic, partitionsCount, maxWaitMs));
}
if (cluster.unauthorizedTopics().contains(topic))
throw new TopicAuthorizationException(topic);
if (cluster.invalidTopics().contains(topic))
throw new InvalidTopicException(topic);
remainingWaitMs = maxWaitMs - elapsed;
partitionsCount = cluster.partitionCountForTopic(topic);
} while (partitionsCount == null || (partition != null && partition >= partitionsCount));
//返回集群信息和获取信息等待的时间
return new ClusterAndWaitTime(cluster, elapsed);
}key 和 value 的序列化
对于发送到broker的信息都需要进行序列化,根据在构造Producer的参数中指定或者构造方法中指定序列化方式
确定partition值
关于 partition 值的计算,分为三种情况:
- 指明 partition 的情况下,直接将指定的值直接作为 partiton 值;
- 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
- 既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的轮询算法。
具体实现如下
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
//如果指定了partition,那么直接使用该值 否则使用分区器计算
return partition != null ? partition : partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
//默认使用的 partitioner是org.apache.kafka.clients.producer.internals.DefaultPartitioner,分区实现为
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
//不指定key时,根据 topic 获取对应的整数变量
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
//指定key时,通过key进行hash运算然后对该topic分区总数取余
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
//第一次随机生成一个数
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
//以后每次递增
return counter.getAndIncrement();
}估算消息大小并检查
校验消息是为了防止消息过大或者数量过多,导致内存异常,具体实现
//估算消息大小
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
//确保消息大小在有效范围内
ensureValidRecordSize(serializedSize);
private void ensureValidRecordSize(int size) {
//是否超过最大请求的限制,如果超过抛出异常
if (size > this.maxRequestSize)
throw new RecordTooLargeException("The message is " + size +
" bytes when serialized which is larger than the maximum request size you have configured with the " +
ProducerConfig.MAX_REQUEST_SIZE_CONFIG +
" configuration.");
//是否超过最大内存缓冲池大小,如果超过抛出异常
if (size > this.totalMemorySize)
throw new RecordTooLargeException("The message is " + size +
" bytes when serialized which is larger than the total memory buffer you have configured with the " +
ProducerConfig.BUFFER_MEMORY_CONFIG +
" configuration.");
}向 accumulator 写数据
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
// We keep track of the number of appending thread to make sure we do not miss batches in
// abortIncompleteBatches().
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
// 当前tp有对应queue时直接返回,否则新建一个返回
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
// 在对一个 queue 进行操作时,会保证线程安全
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
// 为 topic-partition 创建一个新的 RecordBatch
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
// 给这个 RecordBatch 初始化一个 buffer
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
// 如果突然发现这个 queue 已经存在,那么就释放这个已经分配的空间
return appendResult;
}
// 给 topic-partition 创建一个 RecordBatch
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
// 向新的 RecordBatch 中追加数据
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
// 将 RecordBatch 添加到对应的 queue 中
dq.addLast(batch);
// 向未 ack 的 batch 集合添加这个 batch
incomplete.add(batch);
buffer = null;
// 如果 dp.size()>1 就证明这个 queue 有一个 batch 是可以发送了
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
if (buffer != null)
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
}使用sender线程批量发送
//开始启动KafkaProducer I/O线程
public void run() {
while (running) {
try {
//执行IO线程逻辑
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
// 累加器中可能仍然有请求,或者等待确认,等待他们完成就停止接受请求
while (!forceClose && (this.accumulator.hasUndrained() || this.client.inFlightRequestCount() > 0)) {
try {
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
if (forceClose) {
this.accumulator.abortIncompleteBatches();
}
try {
this.client.close();
} catch (Exception e) {
log.error("Failed to close network client", e);
}
}
void run(long now) {
//首先还是判断是否使用事务发送
if (transactionManager != null) {
try {
if (transactionManager.shouldResetProducerStateAfterResolvingSequences())
transactionManager.resetProducerId();
if (!transactionManager.isTransactional()) {
maybeWaitForProducerId();
} else if (transactionManager.hasUnresolvedSequences() && !transactionManager.hasFatalError()) {
transactionManager.transitionToFatalError(
new KafkaException("The client hasn't received acknowledgment for " +
"some previously sent messages and can no longer retry them. It isn't safe to continue."));
} else if (transactionManager.hasInFlightTransactionalRequest() || maybeSendTransactionalRequest(now)) {
// as long as there are outstanding transactional requests, we simply wait for them to return
client.poll(retryBackoffMs, now);
return;
}
//如果事务管理器转态错误 或者producer没有id 将停止进行发送
if (transactionManager.hasFatalError() || !transactionManager.hasProducerId()) {
RuntimeException lastError = transactionManager.lastError();
if (lastError != null)
maybeAbortBatches(lastError);
client.poll(retryBackoffMs, now);
return;
} else if (transactionManager.hasAbortableError()) {
accumulator.abortUndrainedBatches(transactionManager.lastError());
}
} catch (AuthenticationException e) {
transactionManager.authenticationFailed(e);
}
}
//发送Producer数据
long pollTimeout = sendProducerData(now);
client.poll(pollTimeout, now);
}
private long sendProducerData(long now) {
Cluster cluster = metadata.fetch();
// 获取准备发送数据的分区列表
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
//如果有分区leader信息是未知的,那么就强制更新metadata
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
this.metadata.requestUpdate();
}
// 移除没有准备好发送的Node
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
}
}
//创建Producer请求内容
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
addToInflightBatches(batches);
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
// 累加器充值下一批次过期时间
accumulator.resetNextBatchExpiryTime();
List<ProducerBatch> expiredInflightBatches = getExpiredInflightBatches(now);
List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(now);
expiredBatches.addAll(expiredInflightBatches);
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for " + expiredBatch.topicPartition
+ ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";
failBatch(expiredBatch, -1, NO_TIMESTAMP, new TimeoutException(errorMessage), false);
if (transactionManager != null && expiredBatch.inRetry()) {
// This ensures that no new batches are drained until the current in flight batches are fully resolved.
transactionManager.markSequenceUnresolved(expiredBatch.topicPartition);
}
}
sensors.updateProduceRequestMetrics(batches);
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);
pollTimeout = Math.max(pollTimeout, 0);
if (!result.readyNodes.isEmpty()) {
pollTimeout = 0;
}
//发送ProduceRequest
sendProduceRequests(batches, now);
return pollTimeout;
}
private void sendProduceRequests(Map<Integer, List<ProducerBatch>> collated, long now) {
for (Map.Entry<Integer, List<ProducerBatch>> entry : collated.entrySet())
sendProduceRequest(now, entry.getKey(), acks, requestTimeoutMs, entry.getValue());
}
private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {
if (batches.isEmpty())
return;
Map<TopicPartition, MemoryRecords> produceRecordsByPartition = new HashMap<>(batches.size());
final Map<TopicPartition, ProducerBatch> recordsByPartition = new HashMap<>(batches.size());
// 找到创建记录集时使用的最小版本
byte minUsedMagic = apiVersions.maxUsableProduceMagic();
for (ProducerBatch batch : batches) {
if (batch.magic() < minUsedMagic)
minUsedMagic = batch.magic();
}
for (ProducerBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
MemoryRecords records = batch.records();
if (!records.hasMatchingMagic(minUsedMagic))
records = batch.records().downConvert(minUsedMagic, 0, time).records();
produceRecordsByPartition.put(tp, records);
recordsByPartition.put(tp, batch);
}
String transactionalId = null;
if (transactionManager != null && transactionManager.isTransactional()) {
transactionalId = transactionManager.transactionalId();
}
ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout,
produceRecordsByPartition, transactionalId);
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
String nodeId = Integer.toString(destination);
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,
requestTimeoutMs, callback);
//发送数据
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}总结
kafka在发送端的设计非常的精妙,这也是为什么kafka能够达到如此高的性能,我们可以在实际项目中借鉴其中的思想,提高整体业务的效率
参考 :
kafka官方文档
《Apache Kafka实战》
(转载请注明出处)














 4353
4353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









