






一、开源历程
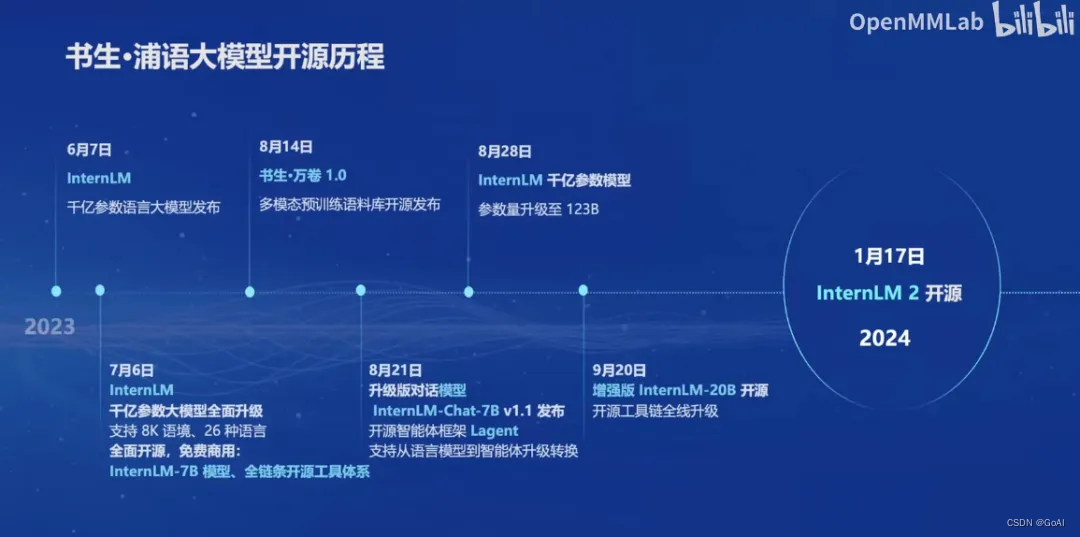
自本世纪初以来,研究人员一直在专用模型上进行集中工作,以解决特定领域的任务。近几年来,人们逐渐转向通用大模型发展,即从“一对一”到“一个模型对多种任务多种模态”的转变。2023年6月7日,InternLM千亿参数语言大模型发布,并于2023年7月6日全面升级为支持8K语境、26种语言的版本,同时开源并免费商用。此外,还有书生万卷1.0多模态预训练语料库和升级版对话模型InternLM-Chat-7B v1.1发布,支持从语言模型到智能体升级转换。
2023年8月28日,InternLM千亿参数模型参数量升级到了123B,并于2023年9月20日开源了增强型InternLM-20B以及全线升级的工具链。最后,在2024年1月17日,InternLM2正式开源,其中包括InternLM2-7B和InternLM2-20B规格,每个规格包含三个模型版本,分别为InternLM2-Base、InternLM2和InternLM2-Chat。这一系列的发展使得大规模语言模型在推理、数学、代码等方面性能有了显著提升,并且具有强大的内生计算能力。!
二、InternLM2介绍
InternLM2根据规格分类分为7B和20B两种模型,其中20B综合性能更强,可以支持更加复杂的使用场景。而按使用需求分类,则有InternLM2-Base、InternLM2和InternLM2-Chat三种。其中,InternLM2在Base基础上进行了多个能力方向的强化,而Chat版本则经过SFT和RLHF优化,具备指令遵循、共情聊天和调用工具等能力。
书生浦语2.0主要亮点包括超长上下文、综合性能、对话和创作体验、工具调用能力以及数理能力和数据分析功能。其中,InternLM2-Chat-20B在重点评测上甚至可以达到比肩ChatGPT GPT3.5水平。
三、应用
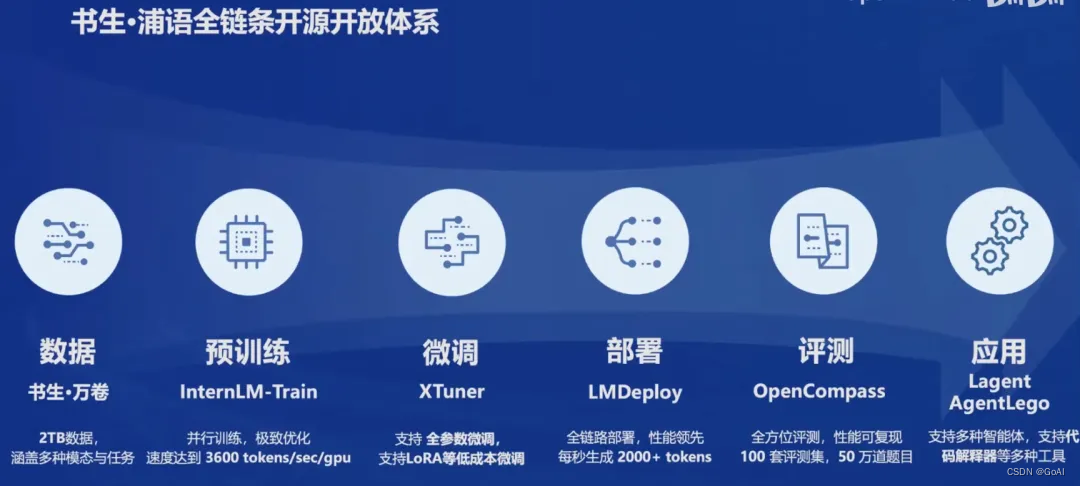
完整的应用流程是模型选型(OpenCompass思南大模型)—数据集(书生·万卷)—参数微调(XTuner)—构建智能体(Lagent和Agentlego)—模型评测(OpenCompass)—模型部署(LMDeploy)。其中,微调方式包括Prefix Tuning,Prompt Tuning,P-tuning,LoRA,QLoRA,以及Adapter Tuning等,这些方法各有特点和适用场景,选择合适的微调方法可以有效地将预训练模型适配到特定的任务或数据集上。
1、数据集

书生·浦语大模型的数据集名为"书生·万卷",将于 2023 年 8 月 14 日发布。这个多语种高质量数据集包含 1.6 万亿个 token,涵盖多种模态和任务。具体来说,它包括:
- 文本数据:超过 50 亿个文档,总数据量超过 1TB。
- 图像-文本数据集:超过 2200 万个文件,总数据量超过 140GB。
- 视频数据:超过 1000 个文件,总数据量超过 900GB。
这个数据集为模型的训练提供了丰富的语言信息和知识基础。
2、预训练和微调
书生·浦语大模型采用了InternLM-Train进行预训练。InternLM-Train是一个基于Transformer架构的预训练模型,拥有1040亿参数。通过在书生·万卷数据集上进行训练,模型具备了强大的语言理解和生成能力。它支持从8卡到千卡的训练,千卡训练效率高达92%,并且可以无缝接入HuggingFace等技术生态,支持各种轻量化技术。
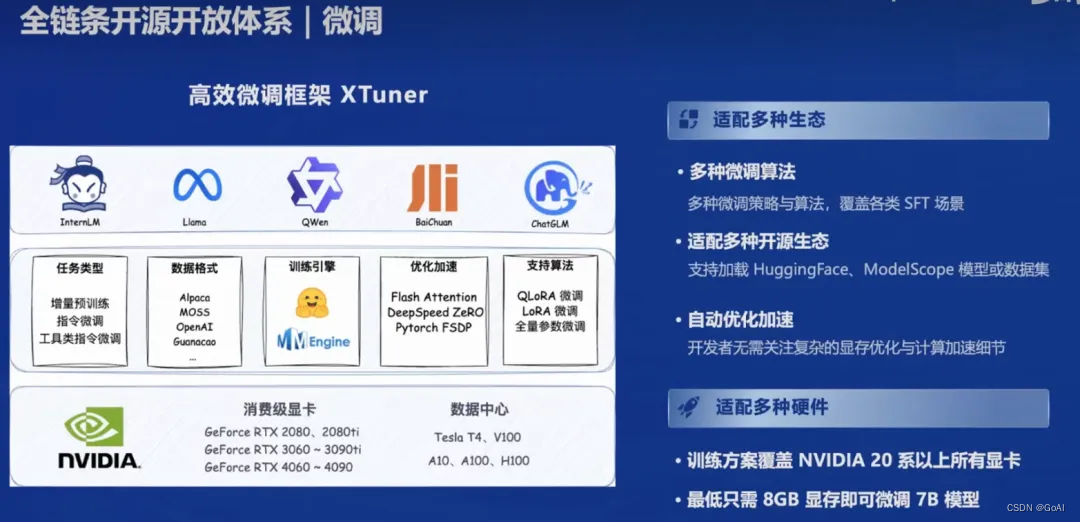
为了进一步提升模型性能并适应特定任务,可以利用XTuner微调框架。XTuner能够根据不同任务需求对大模型进行微调,使其在特定领域或任务上表现更加出色。XTuner具有以下特点:
- 支持多种任务类型:包括增量预训练、指令微调和工具类指令微调。
- 多种微调方式:支持全量参数、LoRA、QLoRA等低成本微调,覆盖各种SFT场景。
- 兼容多种大语言模型:如InternLM、Llama、QWen、BaiChuan、ChatGLM等,适配多种开源生态,支持HuggingFace、ModelScope模型或数据集。
- 自动优化加速:如Flash Attention、DeepSpeed ZeRO,使开发者无需关注复杂的优化与计算加速细节。
- 支持多种硬件:覆盖NVIDIA 20系以上所有显卡,最低只需8GB显存即可微调7B模型。
- 多种数据格式:支持Alpaca、MOSS、OpenAI、Guanacao等数据格式。
通过结合预训练和微调,书生·浦语大模型能够在多种任务和领域中展现出色的性能。
3、部署
在模型应用方面,书生·浦语大模型使用了LMDeploy部署框架。LMDeploy提供了大模型在GPU上的全流程部署解决方案,包括模型轻量化、推理和服务。它能够将大模型快速部署到各种计算平台上,实现实时推理和应用。LMDeploy的主要特点包括:
- 接口支持:支持Python、GRPC和RESTful接口,方便开发者集成。
- 量化支持:支持4bit和8bit量化,提升模型推理效率。
- 推理引擎:支持turbomind和PyTorch,提供灵活的推理选择。
- 服务:支持openai-server、gradio和triton inference server,满足不同的服务需求

在评测方面,书生·浦语大模型使用了OpenCompass评测框架。OpenCompass包含80套评测集,共40万道题目,能够对模型在多个任务和数据集上的表现进行全面评估。评测内容涵盖以下六大维度:
- 学科:包括初中考试、中国高考、大学考试、语言能力考试和职业资格考试。
- 语言:包括字词释义、成语习语、语义相似、指代消解和翻译。
- 知识:包括知识问答和多语种知识问答。
- 理解:包括阅读理解、内容分析和内容总结。
- 推理:包括因果推理、常识推理、代码推理和数学推理。
- 安全:包括偏见、有害性、公平性、隐私性、真实性和合法性。
通过LMDeploy和OpenCompass,书生·浦语大模型不仅能够高效部署和应用,还能在多个维度上进行全面评估,确保模型在实际应用中的可靠性和性能。
4、应用
在应用方面,书生·浦语大模型开发了Lagent和AgentLego多模态智能体工具箱,帮助开发者构建和训练多模态智能体,实现图文混合创作和多模态对话等应用场景。
Lagent
Lagent是一个轻量级智能体框架,具有以下特点:
- 多种智能体能力:支持ReAct、ReWoo、AutoGPT等多种类型的智能体能力。
- 灵活支持多种大语言模型:包括OpenAI的GPT-3.5/4、上海人工智能实验室的InternLM、Hugging Face的Transformers、Meta的Llama等。
- 简单易拓展:支持丰富的工具,如AI工具(文生图、文生语音、图片描述)、能力拓展(搜索、计算器、代码解释器)、RapidAPI(出行API、财经API、体育咨询API)等。
AgentLego
AgentLego是一个多模态智能体工具箱,具有以下特色:
- 丰富的工具集合:提供大量视觉和多模态相关领域的前沿算法功能。
- 支持多个主流智能体系统:如Lagent、LangChain、Transformers Agent等。
- 灵活的多模态工具调用接口:支持各类输入输出格式的工具函数。
- 一键式远程工具部署:轻松使用和调试大模型智能体。
通过Lagent和AgentLego,开发者可以更方便地构建和部署多模态智能体,满足各种复杂的应用需求。这些工具箱不仅提供了强大的功能支持,还简化了开发和部署流程,使得多模态智能体的应用更加高效和便捷。















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









