







Thank Zhihao Tao for your hard work. The document spent countless nights and weekends, using his hard work to make it convenient for everyone.
If you have any questions, please send a email to zhihao.tao@outlook.com
文章目录
1. 概述
BPF是Linux内核中高度灵活且高效的类虚拟机的构造,允许以安全的方式在各个hook点执行字节码。它被用于许多Linux内核子系统中,最主要的是网络,跟踪和安全(例如沙箱)。Brendan Gregg宣称BPF是linux的超能力。
如今,Linux内核仅运行eBPF (extended BPF),并且在程序执行之前,已加载的cBPF (classic BPF)字节码在内核中透明地转换为eBPF表示形式。
原始的BPF设计用于捕获和过滤与特定规则匹配的网络数据包。筛选器被实现为要在基于寄存器的虚拟机上运行的程序。
如今用于许多Linux内核子系统中,最主要的是网络,跟踪和安全:
- 高性能负载平衡
- DDoS防护
- 防火墙
- 内核和用户空间代码的安全检测
- 网络数据路径(XDP)
- 内核探针
- 性能事件等
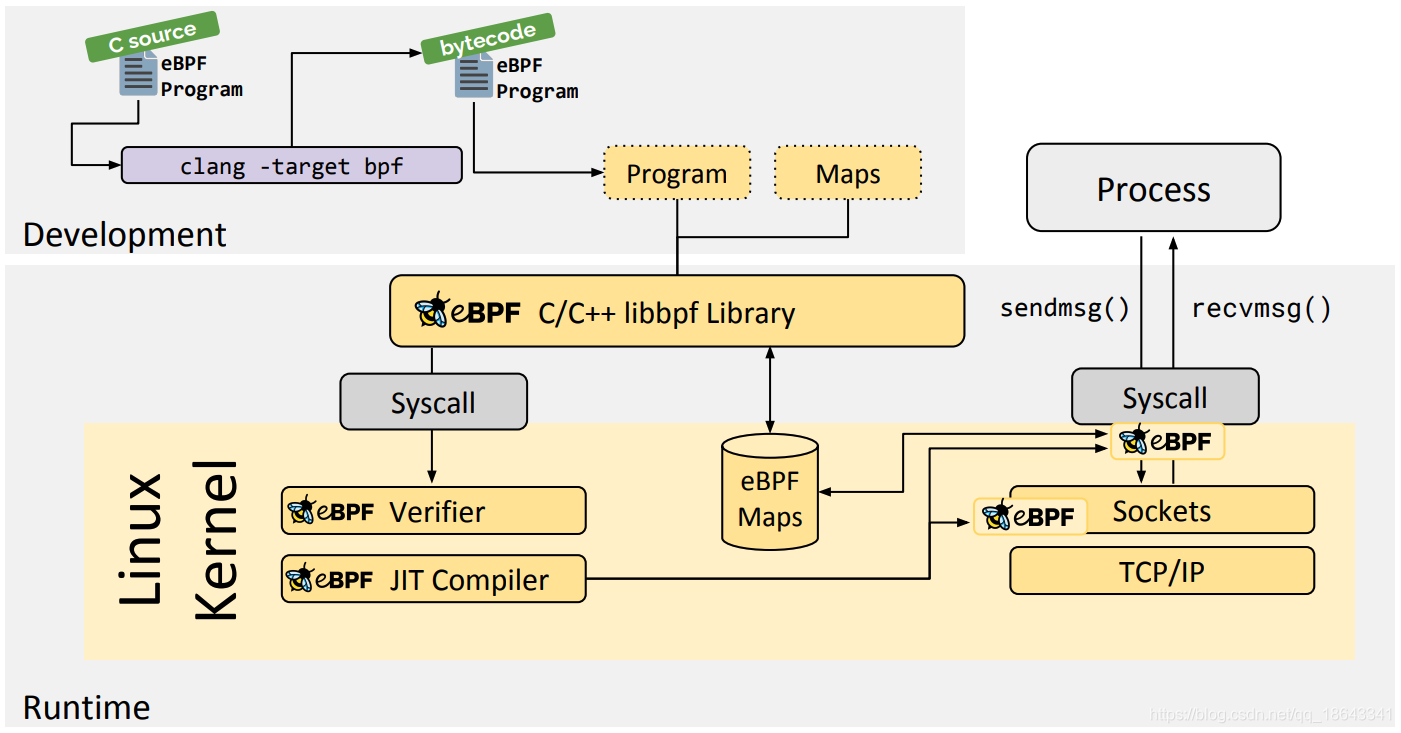
eBPF程序所经历的过程可以分为三个不同的部分:
-
创建eBPF程序作为字节码。
- 创建eBPF程序的方法是将它们编写为C代码,然后让LLVM将其编译为驻留在ELF文件中的eBPF字节代码。
- 将程序加载到内核中并创建必要的eBPF映射。是使用bpfLinux中的syscall完成的。此syscall允许加载字节码以及正在加载的eBPF程序类型的声明
- eBPF程序的MAP重要方面是共享收集的信息和存储状态的能力。为此,eBPF程序可以利用eBPF映射的概念来存储和检索各种数据结构中的数据。可以通过系统调用从eBPF程序以及用户空间中的应用程序访问eBPF映射。。
-
将加载的程序附加到系统。
- 验证步骤可确保eBPF程序可以安全运行。验证程序需要满足几个条件:
- 加载eBPF程序的过程包含所需的功能(特权)。除非启用了非特权eBPF,否则只有特权进程才能加载eBPF程序。
- 该程序不会崩溃或以其他方式损害系统。
- 程序始终运行到完成状态(即程序不会永远处于循环状态,从而阻止了进一步的处理)。
- JIT编译即时(JIT)编译步骤将程序的通用字节码转换为特定于机器的指令集,以优化程序的执行速度。
- 这使得eBPF程序的运行效率与本地编译的内核代码或作为内核模块加载的代码一样有效。
- 验证步骤可确保eBPF程序可以安全运行。验证程序需要满足几个条件:
-
每种eBPF程序类型都有不同的过程来附加到其相应的系统。附加程序后,程序将变为活动状态,并开始过滤,分析或捕获信息,具体取决于创建该程序的目的。
1.1 发展
| 时间点 | 事件 |
|---|---|
| 1992年 | BPF技术诞生(cBPF) |
| 2014年 | eBPF暴露到用户空间 |
| 2015年 | BPF Map/Prog持久化 |
| 2016年 | XDP引入 |
| 2017年 | cgroup + bpf的多程序支持 |
| 2020年 | 实现BPF环形缓冲区和验证程序支持 |
1.2 优势
BPF是通用的RISC指令集,最初是为了在C的子集中编写程序而设计的,可以通过编译器后端(例如LLVM)将其编译成BPF指令,内核可以稍后通过内核内JIT编译器将它们映射为本机操作码,从而在内核内获得最佳执行性能。将这些指令推入内核的优势包括:
-
使内核可编程(不需要直接修改内核代码进行开发),而不必跨越内核/用户空间边界。
- 例如,与网络相关的BPF程序可以实现灵活的容器策略,负载平衡和其他方式,而不必将数据包移至用户空间并移回内核。必要时,BPF程序与内核/用户空间之间的状态仍然可以通过映射共享。
-
鉴于可编程数据路径的灵活性,还可以通过编译程序解决的用例所不需要的功能,对程序的性能进行重大优化。
- 例如,如果容器不需要IPv4,则可以将BPF程序构建为仅处理IPv6,以节省快速路径中的资源。
-
在网络中(例如tc和XDP),可以自动更新BPF程序,而不必重新启动内核,系统服务或容器,也不会造成流量中断。此外,还可以通过BPF映射在整个更新过程中保持任何程序状态。
-
BPF为用户空间提供了稳定的ABI,并且不需要任何第三方内核模块。
- BPF是Linux内核的核心部分,随处可见,并保证现有的BPF程序可以在较新的内核版本上运行。此保证与内核为用户空间应用程序提供系统调用的保证相同。
-
BPF程序与内核协同工作,它们利用现有的内核基础结构(例如驱动程序,网络设备,隧道,协议栈,套接字)和工具(例如iproute2)。
- 例如,XDP程序重用现有的内核内驱动程序并在提供的DMA缓冲区上运行包含数据包帧,而不会像其他模型中那样将它们或整个驱动程序暴露给用户空间。
- 此外,XDP程序重用现有协议栈,而不是绕过它。
- BPF可被视为内核工具的通用“胶水代码”,用于编写程序来解决特定的用例。
-
具有强大的系统安全性。
- 与内核模块不同,BPF验证器(verifier)会对BPF程序进行验证,以确保它们不会使内核崩溃,总是终止等。
-
BPF程序的高性能。
- JIT编译器HU会将编译BPF程序生成的是通用的字节码
- 可跨不同体系结构移植,可以在x86和ARM等任意CPU架构上加载。
-
BPF程序的可持续交付。
- JIT编译后的程序附加到内核中各种钩子(hook)上,可以在不影响系统运行的情况下,BPF程序的内核热更新。
内核内部BPF程序的执行始终是事件驱动的!
例子:
- 一旦接收到数据包,在其入口路径上附加了BPF程序的网络设备将触发该程序的执行。
- 一旦执行了kprobe并附加了BPF程序的内核地址,该地址就会被捕获,然后将调用kprobe的回调函数进行检测,随后触发所附加的BPF程序的执行。
1.3 限制
每个程序的最大指令限制为4096 BPF指令,这在设计上意味着任何程序都会迅速终止。对于高于5.1的内核,此限制提高到了100万个BPF指令。尽管指令集包含向前跳转和向后跳转,但内核BPF验证程序将禁止循环,以便始终保证终止。
由于BPF程序在内核中运行,因此验证程序的工作是确保它们可以安全运行,而不影响系统的稳定性。这意味着从指令集的角度来看,可以实现循环,但是验证程序将对此加以限制。
但是,还有一种尾部调用的概念,它允许一个BPF程序跳入另一个程序。同样,它的嵌套上限为33个调用。
1.4 基于eBPF的项目
1.4.1 bcc
https://github.com/iovisor/bcc
BCC代表BPF编译器集合,其主要功能是提供一套易于使用且高效的内核跟踪实用程序,这些实用程序均基于BPF程序,这些程序基于kprobes,kretprobes,tracepoint,uprobes,uretprobes和USDT探针等连接到内核基础结构。
该集合提供了近百种工具,这些工具针对从应用程序,系统库到各种不同的内核子系统的整个堆栈的不同层,以分析系统的性能特征或问题。此外,BCC提供了一个API,以便用作其他项目的库。
1.4.2 bpftrace
https://github.com/ajor/bpftrace
bpftrace是用于Linux的DTrace样式动态跟踪工具,它使用LLVM作为后端将脚本编译为BPF字节码,并利用BCC与内核的BPF跟踪基础结构进行交互。与原生BCC相比,它提供了用于实现跟踪脚本的高级语言。
1.4.3 perf
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/tools/perf
由Linux内核社区开发的perf工具是内核源代码树的一部分,它提供了一种通过常规perf record子命令来加载跟踪BPF程序的方法,例如,可以从perf.data(通过perf脚本和其他方式)中检索和后期处理来自BPF的聚合数据。
1.4.4 systemtap
https://sourceware.org/git/gitweb.cgi?p=systemtap.git;a=summary
systemtap是一种脚本语言和工具,用于提取,过滤和汇总数据以诊断和分析性能或功能问题。它带有一个称为stapbpf的BPF后端,该后端无需额外的编译器即可将脚本直接转换为BPF,并将探针注入内核。因此,与stap的内核模块不同,它既没有外部依赖性,也不需要加载内核模块。
1.4.5 Cilium
https://github.com/cilium/cilium
Cilium提供并透明地保护应用程序工作负载(例如应用程序容器或进程)之间的网络连接和负载平衡。Cilium在第3/4层运行以提供传统的网络和安全服务,在第7层运行以保护和保护现代应用程序协议(例如HTTP,gRPC和Kafka)的使用。它被集成到诸如Kubernetes和Mesos的业务流程框架中,而BPF是Cilium的基础部分,它在内核的网络数据路径中运行。
1.4.6 suricata
https://suricata-ids.org/
Suricata是网络IDS,IPS和NSM引擎,在三个不同的领域中使用BPF和XDP,即作为BPF过滤器以处理或绕过某些数据包,作为基于BPF的负载均衡器以允许可编程负载平衡,并让XDP以高数据包速率实现旁路或丢弃机制。
1.4.7 systemd
http://0pointer.net/blog/ip-accounting-and-access-lists-with-systemd.html
https://github.com/systemd/systemd
systemd允许进行IPv4/IPv6记录,并基于BPF的cgroup入口和出口钩子对其systemd单元实施网络访问控制。记录基于数据包/字节,并且可以将ACL指定为允许/拒绝规则的地址前缀。
1.4.8 iproute2
https://git.kernel.org/pub/scm/network/iproute2/iproute2.git/
iproute2能够将BPF程序(LLVM生成的ELF文件)加载到内核中。iproute2通过公共BPF加载程序后端支持XDP BPF程序和tc BPF程序。tc和ip命令行实用程序为用户启用了加载程序和自检功能。
1.4.9 clang/LLVM
https://llvm.org/
clang/LLVM提供了BPF后端,以便将C BPF程序编译为ELF文件中包含的BPF指令。LLVM BPF后端与Linux内核中的BPF核心基础结构一起开发,并由同一社区维护。clang/LLVM是开发BPF程序的工具链中的关键部分。
1.4.10 libbpf
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/tools/lib/bpf
libbpf是一个通用的BPF库,由Linux内核社区作为内核源代码树的一部分开发,并允许将LLVM生成的ELF文件中的BPF程序加载并附加到内核中。该库供其他内核项目(例如perf和bpftool)使用。
1.4.11 bpftool
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/tools/bpf/bpftool
bpftool是用于自检和调试BPF程序和BPF MAP的主要工具,就像libbpf是由Linux内核社区开发的。它允许转储系统中所有活动的BPF程序和映射,转储和反汇编程序中的BPF或JITed BPF指令,以及转储和处理系统中的BPF映射。bpftool支持与BPF文件系统的交互,将各种程序类型从目标文件加载到内核等。
1.4 参考文档
- Linux Socket Filtering aka Berkeley Packet Filter (BPF)
- BPF and XDP Reference Guide
- A New Architecture for User-level Packet Capture
- A thorough introduction to eBPF
- BPF: the universal in-kernel virtual machine
- BPF: A Tour of Program Types
- kprobes
- tracepoints
- perf
- uprobetracer
- kprobetrace
- Lightweight & flow based tunneling
- https://www.ferrisellis.com/content/ebpf_past_present_future/
- https://ebpf.io/zh-cn/
2. 功能点
2.1 BPF程序类型
/* Note that tracing related programs such as
* BPF_PROG_TYPE_{KPROBE,TRACEPOINT,PERF_EVENT,RAW_TRACEPOINT}
* are not subject to a stable API since kernel internal data
* structures can change from release to release and may
* therefore break existing tracing BPF programs. Tracing BPF
* programs correspond to /a/ specific kernel which is to be
* analyzed, and not /a/ specific kernel /and/ all future ones.
*/
enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC,
BPF_PROG_TYPE_SOCKET_FILTER,
BPF_PROG_TYPE_KPROBE,
BPF_PROG_TYPE_SCHED_CLS,
BPF_PROG_TYPE_SCHED_ACT,
BPF_PROG_TYPE_TRACEPOINT,
BPF_PROG_TYPE_XDP,
BPF_PROG_TYPE_PERF_EVENT,
BPF_PROG_TYPE_CGROUP_SKB,
BPF_PROG_TYPE_CGROUP_SOCK,
BPF_PROG_TYPE_LWT_IN,
BPF_PROG_TYPE_LWT_OUT,
BPF_PROG_TYPE_LWT_XMIT,
BPF_PROG_TYPE_SOCK_OPS,
BPF_PROG_TYPE_SK_SKB,
BPF_PROG_TYPE_CGROUP_DEVICE,
BPF_PROG_TYPE_SK_MSG,
BPF_PROG_TYPE_RAW_TRACEPOINT,
BPF_PROG_TYPE_CGROUP_SOCK_ADDR,
BPF_PROG_TYPE_LWT_SEG6LOCAL,
BPF_PROG_TYPE_LIRC_MODE2,
BPF_PROG_TYPE_SK_REUSEPORT,
BPF_PROG_TYPE_FLOW_DISSECTOR,
BPF_PROG_TYPE_CGROUP_SYSCTL,
BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE,
BPF_PROG_TYPE_CGROUP_SOCKOPT,
BPF_PROG_TYPE_TRACING,
BPF_PROG_TYPE_STRUCT_OPS,
BPF_PROG_TYPE_EXT,
BPF_PROG_TYPE_LSM,
BPF_PROG_TYPE_SK_LOOKUP,
};
由此可见linux内核支持众多BPF程序类型。这里以其中几个为例进行讲解。
2.1.1 与套接字相关的程序类型
套接字相关的程序类型允许我们过滤,重定向socket数据和监视socket事件。
| 类型 | 描述 |
|---|---|
| BPF_PROG_TYPE_SOCKET_FILTER | 丢弃数据包或修剪数据包 |
| BPF_PROG_TYPE_SOCK_OPS | 捕获套接字操作,例如连接建立,重传超时等 |
| BPF_PROG_TYPE_SK_SKB | 访问skb和套接字详细信息,例如端口和IP地址,以支持套接字之间skb的重定向 |
2.1.1.1 BPF_PROG_TYPE_SOCKET_FILTER
BPF_PROG_TYPE_SOCKET_FILTER与BPF的起源有关。当我们对网络进行监控时,我们只希望看到其中的一部分网络流量,例如,来自故障系统的所有流量。
FILTER用于描述我们希望看到的流量,理想情况下,
- 希望它是快速的
- 希望为用户提供一组开放式的过滤选项
- 希望尽早丢弃不需要的数据
- 希望在内核上下文中进行过滤。
- 因为将数据包复制到用户空间并在其中进行过滤的成本是非常昂贵的,特别是如果我们只希望看到一部分网络流量并丢弃其余部分的话。
为实现此目的,发明了一种安全的迷你语言,可以将高级过滤器转换为内核可以识别并使用的字节码程序(称为经典BPF,cBPF)。该语言的目的是支持:
- 一组灵活的过滤选项,
- 又快速又安全。
- 参考文档:A New Architecture for User-level Packet Capture
可以使用诸如tcpdump之类的用户空间程序来完成编写,以完成内核中的过滤。
2.1.1.1.1 编程介绍
对于SOCKET_FILTER,常见的情况是将其附加到SOCK_RAW,例如:
#include <sys/socket.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <linux/if_ether.h>
...
struct sock_filter code[] = {
{ 0x28, 0, 0, 0x0000000c },
{ 0x15, 0, 5, 0x000086dd },
{ 0x30, 0, 0, 0x00000014 },
{ 0x15, 6, 0, 0x00000006 },
{ 0x15, 0, 6, 0x0000002c },
{ 0x30, 0, 0, 0x00000036 },
{ 0x15, 3, 4, 0x00000006 },
{ 0x15, 0, 3, 0x00000800 },
{ 0x30, 0, 0, 0x00000017 },
{ 0x15, 0, 1, 0x00000006 },
{ 0x6, 0, 0, 0x00040000 },
{ 0x6, 0, 0, 0x00000000 },
};
struct sock_fprog bpf = {
.len = ARRAY_SIZE(code),
.filter = code,
};
sock = socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL));
...
ret = setsockopt(sock, SOL_SOCKET, SO_ATTACH_FILTER, &bpf, sizeof(bpf));
...
close(sock);
原始数据包的接收是通过raw_local_deliver函数实现的。在调用相关IP协议的处理程序之前,ip_local_deliver_finish调用了该方法,该处理程序是将数据包传递到TCP,UDP,ICMP等进行处理。
2.1.1.1.2 数据结构
- 数据结构头文件<linux/filter.h>
/*
* Try and keep these values and structures similar to BSD, especially
* the BPF code definitions which need to match so you can share filters
*/
struct sock_filter { /* Filter block */
__u16 code; /* Actual filter code */
__u8 jt; /* Jump true */
__u8 jf; /* Jump false */
__u32 k; /* Generic multiuse field */
};
struct sock_fprog { /* Required for SO_ATTACH_FILTER. */
unsigned short len; /* Number of filter blocks */
struct sock_filter __user *filter;
};
filter是由一个由4个元组组成的数组,其中包含一个code,jt,jf和k值。jt和jf是要用于提供的代码的跳转偏移量和k为通用值。
参考资料:networking-filter
- 示例
tcpdump的-d选项可以查看生成的cBPF字节码,libpcap中提供直接的api调用。
例如我想在lo接口上运行tcpdump且仅过滤TCP流量:
[root@bogon workspace]# tcpdump -i lo -d 'tcp'
(000) ldh [12]
(001) jeq #0x86dd jt 2 jf 7
(002) ldb [20]
(003) jeq #0x6 jt 10 jf 4
(004) jeq #0x2c jt 5 jf 11
(005) ldb [54]
(006) jeq #0x6 jt 10 jf 11
(007) jeq #0x800 jt 8 jf 11
(008) ldb [23]
(009) jeq #0x6 jt 10 jf 11
(010) ret #262144
(011) ret #0
[root@bogon workspace]# tcpdump -i lo -dd 'tcp'
{ 0x28, 0, 0, 0x0000000c },
{ 0x15, 0, 5, 0x000086dd },
{ 0x30, 0, 0, 0x00000014 },
{ 0x15, 6, 0, 0x00000006 },
{ 0x15, 0, 6, 0x0000002c },
{ 0x30, 0, 0, 0x00000036 },
{ 0x15, 3, 4, 0x00000006 },
{ 0x15, 0, 3, 0x00000800 },
{ 0x30, 0, 0, 0x00000017 },
{ 0x15, 0, 1, 0x00000006 },
{ 0x6, 0, 0, 0x00040000 },
{ 0x6, 0, 0, 0x00000000 },
- 第000行,以太网帧头的偏移量+12;得到以太网帧头协议类型。
- 第001行,如果它与ETH_P_IPv6(0x86dd)(jt 2)相匹配,则跳至002,否则,如果为false(jf 7),则跳至007(处理IPv4情况)。
- 第003行,如果IPv6协议(偏移量+ 20)为6(IPPROTO_TCP)跳到010
- 010行返回65535,这是最大长度,因此我们接受数据包。
- 否则,跳到004。在这里,将其与0x2c进行比较,这表明存在一个IPv6片段标头。如果是这样,我们检查片段头(偏移量54)是否将下一个协议值指定为IPPROTO_TCP,如果是,则跳至10(成功)或11(失败)。返回0表示丢弃数据包以进行过滤。
- 第007行上,我们检查ETH_P_IPV4,如果找到,则验证IPPROTO是否为TCP。
注意:这是cBPF;eBPF具有类似于x86_64和其他寄存器的扩展指令/操作集。
2.1.1.1.3 与Netfilter对比
Netfilter使用NF_HOOK定义了自己的钩子集,基于netfilter的技术(例如ipfilter)也可以用来过滤流量。bpfilter在较新的Linux内核中取代了ipfilter。
2.1.2 Xpress数据路径的程序类型
XDP的主要设计目标是在网络数据路径中引入可编程性。目的是提供尽可能靠近设备的XDP HOOK(在OS创建sk_buff元数据之前),以便在支持跨设备的通用基础结构的同时实现性能最大化。
2.1.2.1 BPF_PROG_TYPE_XDP
XDP允许在分配分组元数据(结构sk_buff)之前尽早访问分组数据。因此,这是进行DDoS缓解或负载平衡。
XDP旨在通过BPF HOOK来支持内核的运行时编程,但要与内核本身协同工作。即不是内核旁路机制。支持的动作包括:
- XDP_PASS(照常进入网络处理)
- XDP_DROP(丢弃)
- XDP_TX(发送)
- XDP_REDIRECT
Real-XDP是在驱动程序级别实现,并且为XDP使用预留了发送/接收环资源。对于驱动程序不支持XDP的情况,可以选择使用net/core/dev.c中实现的generic-XDP。缺点是我们不绕过skb分配,它只允许我们将XDP用于此类设备。
2.1.3 调试相关的程序类型
2.1.3.1 kprobes
kprobes允许检测特定函数。利用kprobes技术,内核开发人员可以在内核的绝大多数指定函数中动态的插入探测点来收集所需的调试状态信息而基本不影响内核原有的执行流程。当启用这些探针之一时,将保存启用点处的代码,并用断点指令替换。当遇到此断点时,将生成陷阱指令,保存寄存器,然后跳转到相关的检测处理程序。
2.1.3.2 tracepoints
tracepoint是内核静态跟踪点,它与kprobe类程序的主要区别在于tracepoint由内核开发人员在内核中编写和修改。
2.1.3.3 perf
Perf事件是调试相关的程序类型的eBPF支持的基础。BPF基本上依靠现有的事件采样基础设施,使我们可以将程序附加到感兴趣的perf事件上,这些事件包括kprobes,uprobes,tracepoint等以及其他软件事件,并且实际上也可以监视硬件事件。
这些检测点使BPF能够成为通用的跟踪工具,并成为支持原始的以网络为中心的用例(如套接字过滤)的手段。
2.1.4 与cgroups相关的程序类型
CGroup用于处理资源分配,允许或拒绝进程组对系统资源(如CPU,网络带宽等)的访问。cgroup的一个关键用例是容器。容器的资源访问通过cgroups进行限制,而其活动却被各种名称空间类别(网络名称空间,进程ID空间等)隔离。
在BPF上下文中,我们可以创建允许或拒绝访问的eBPF程序。
2.1.4.1 BPF_PROG_TYPE_CGROUP_SKB
允许或拒绝IP出口/入口(BPF_CGROUP_INET_INGRESS / BPF_CGROUP_INET_EGRESS)上的网络访问。BPF程序应返回1以允许访问。任何其他值都会导致函数__cgroup_bpf_run_filter_skb()返回-EPERM,该值将传输到调用方,从而丢弃该数据包。
2.1.4.2 BPF_PROG_TYPE_CGROUP_SOCK
在各种与套接字相关的事件(BPF_CGROUP_INET_SOCK_CREATE,BPF_CGROUP_SOCK_OPS)上允许或拒绝网络访问。如上所述,BPF程序应返回1以允许访问。任何其他值都会导致函数__cgroup_bpf_run_filter_sk()返回-EPERM,该值将传播到调用方,从而丢弃该数据包。
2.1.5 轻量级隧道程序类型
轻型隧道是通过将封装指令附加到路由来进行隧道的一种简单方法。
2.1.5.1 BPF_PROG_TYPE_LWT_XMIT
为传输中的轻型隧道实现封装/重定向。
2.2 BPF Maps
BPF Map本质上是以「键/值」方式存储在内核中的数据结构,可以从BPF程序访问它们,以保持多个BPF程序调用之间的状态。它们也可以通过用户空间中的文件描述符进行访问,并且可以与其他BPF程序或用户空间应用程序任意共享。
彼此共享MAP的BPF程序不需要具有相同的程序类型,例如,跟踪程序可以与网络程序共享MAP。当前一个BPF程序可以直接访问多达64个不同的MAP。
3. BPF验证器
BPF验证器会在BPF程序加载到内核之前分析程序。
3.1 参考资料
3.2 检查流程
3.2.1 第一步
BPF验证器执行的第一项检查是对BPF虚拟机加载的代码进行静态分析,目的是确保程序能够按照预期结束。验证器在进行第一项检查时所做工作为:
- 程序不包含控制循环;根据最新更新,现在允许有界循环
- 程序不会执行超过内核允许的最大指令数;程序不能大于4096指令
- 程序不包含任何无法到达的指令;
- 程序不会超出程序界限。
也就是程序必须为有向无环图(DAG - Directed Acyclic Graph)。BPF程序必须没有任何向后分支,它必须是有向图。但是,程序的不同部分可以前进到同一点。因此,它不是一棵“树”。
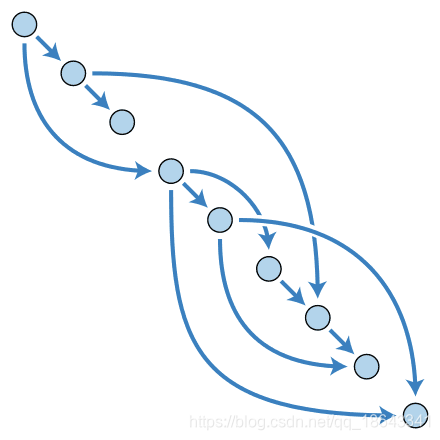
3.2.2 第二步
BPF验证器执行的第二项检查是对BPF程序进行预运行,所做工作为:verifier.c
验证程序将尝试BPF代码的每个路径。每当遇到某种情况时,它都会探索一条路径,并将另一条路径的指令压入堆栈。如果达到bpf_exit()而没有任何问题,并且具有R0值,则验证程序将开始接受指令并检查堆栈中的其他任何代码路径(这是LIFO,因此将从上次推送开始)。















 4108
4108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











