







术语
算子状态、键控状态、状态一致性、检查点、保存点、状态后端。
状态管理
流式计算分为无状态和有状态两种情况。无状态的计算观察每个独立事件,并根据最后一个事件输出结果。例如,流处理应用程序从传感器接收温度读数,并在温度超过 90 度时发出警告。有状态的计算则会基于多个事件输出结果。
状态分为两类:
- 算子状态(operator state)
算子状态的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。算子状态不能由相同或不同算子的另一个任务访问。 - 键控状态(keyed state)
键控状态是根据输入数据流中定义的键(key)来维护和访问的。Flink 为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个 key 对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key。因此,具有相同 key 的所有数据都会访问相同的状态。Keyed State 很类似于一个分布式的 key-value map 数据结构,只能用于 KeyedStream(keyBy 算子处理之后)。
算子状态提供了三种类型的数据结构:
- 列表状态(List state)
将状态表示为一组数据的列表。 - 联合列表状态(Union list state)
也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。 - 广播状态(Broadcast state)
如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
键控状态支持的数据类型:
- ValueState保存单个的值,值的类型为 T
- ListState保存一个列表,列表里的元素的数据类型为 T。
- MapState<K, V>保存 Key-Value 对。
- ReducingState
- AggregatingState<I, O>
容错机制
状态一致性
- at-most-once: 至多一次,这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可能丢失。
- at-least-once: 至少一次,这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算。
- exactly-once: 精确一次,这指的是系统保证在发生故障后得到的计数结果与正确值一致。
检查点(checkpoint)
Flink 具体如何保证 exactly-once 呢? 它使用一种被称为"检查点"(checkpoint)的特性,在出现故障时将系统重置回正确状态。Flink 检查点的核心作用是确保状态正确,即使遇到程序中断,也要正确。
- 分界线(barrier)
保存点(savepoint)
保存点,主要用来手动保存Checkpoint,用于集群的迁移,升级,任务重启。
以我个人目前的理解:
checkpoint,主要是用来做故障恢复。而savepoint,主要用户做主动恢复。前者是防止因为各种原因造成了任务执行中断,重启后尽量从某个时刻开始执行。savepoint,主要是认为触发,属于主动意图,与前者不同。
状态后端(state backend)
- MemoryStateBackend
内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在 TaskManager 的 JVM 堆上;而将 checkpoint 存储在 JobManager 的内存中。 - FsStateBackend
将 checkpoint 存到远程的持久化文件系统(FileSystem)上。而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上。 - RocksDBStateBackend
将所有状态序列化后,存入本地的 RocksDB 中存储。传送门–深入了解
总结:FsStateBackend、 RocksDBStateBackend主要用于生产环境,都是将checkpoint保存到指定的文件系统,但是区别在于FsStateBackend受限于JVM对内存能报错的状态数据容量,RocksDBStateBackend不受限与堆内存,而受限于本地磁盘容量。
案例
- 停止集群,从检查点恢复
- 保存检查点,从保存检查点恢复
- 准备一个计算程序
程序逻辑很简单,计算输入的单词总个数
/**
* 计算输入的单词总数量
*/
public class KeyStateTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ExecutionConfig config = env.getConfig();
config.setAutoWatermarkInterval(0);
env.setParallelism(1);
//设置状态后端
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:8020/flink/checkpoint"));
// env.getCheckpointConfig().setCheckpointStorage("file:///E:\\BaiduNetdiskDownload\\大数据\\尚硅谷大数据技术之Flink(Java版)\\checkpoint\\totalWC");
//检查点执行周期,单位毫秒
env.enableCheckpointing(1000);
//精确一次
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//检查点运行超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);
//检查点最小间隔时间
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//检查点并发数量,1:不允许并行多个检查点
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//是否优先使用查检查点恢复,官方标记过时,不建议使用,可能造成数据丢失或者重复输出
env.getCheckpointConfig().setPreferCheckpointForRecovery(false);
//容忍检查点失败次数
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(0);
//设置检查点重启策略,重试6次,每次间隔5分钟
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(6,60*1000*5));
DataStream<String> dataStream = env.socketTextStream("hadoop101", 9999);
dataStream
.flatMap((FlatMapFunction<String, Tuple2<String, Long>>) (value, out) -> {
if (StringUtils.isNotBlank(value)) {
String[] split = value.split("\\s+");
for (int i = 0; i < split.length; i++) {
String word = split[i];
out.collect(new Tuple2<>(word, 1L));
}
}
})
//lamda表达式,泛型擦除,需要声明返回类型
.returns(Types.TUPLE(Types.STRING, Types.LONG))
.keyBy(data -> "all")
.map(new RichMapFunction<Tuple2<String, Long>, Tuple2<String, Long>>() {
private ValueState<Long> totalCountState;
@Override
public void open(Configuration parameters) throws Exception {
this.totalCountState = getRuntimeContext().getState(new ValueStateDescriptor<>("totalCount",Long.class));
}
@Override
public Tuple2<String, Long> map(Tuple2<String, Long> value) throws Exception {
Long totalCount = totalCountState.value();
if(totalCount == null){
totalCount = 0L;
}
totalCount += value.f1;
totalCountState.update(totalCount);
return new Tuple2<>(value.f0,totalCount);
}
})
.print();
env.execute();
}
}
- 部署到yarn集群
bin/flink run -t yarn-per-job \
-c com.xbz.bigdata.study.flink.state.KeyStateTest \
/opt/module/flink-1.13.2/myjobs/flink-study-1.0.0.jar
- 在hadoop101:9999输入一些数据,让state出现数据
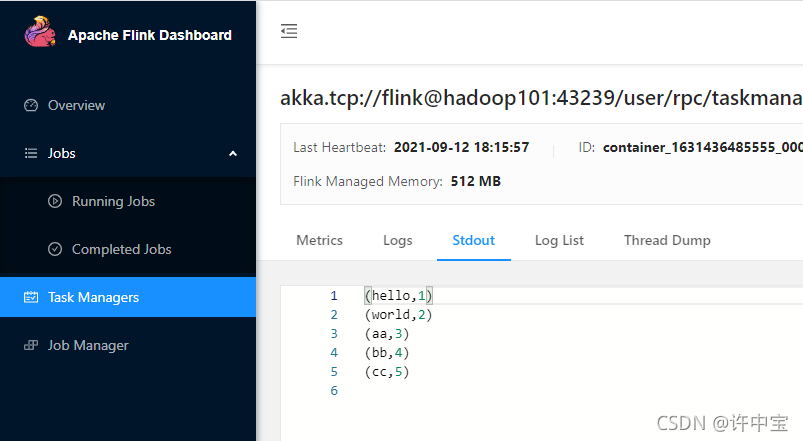
hello world
aa bb cc
次数的总次数状态应该是5
- 停止集群(注意不要使用
yarn application --killorflink cancel因为正常的停止flink应用,checkpoint数据会清空。–>这里是模拟故障
# 无法继续写数据
stop-dfs.sh
# 停止yarn
stop-yarn.sh
此时我们发现任务目录下存在chk-XX,有数据
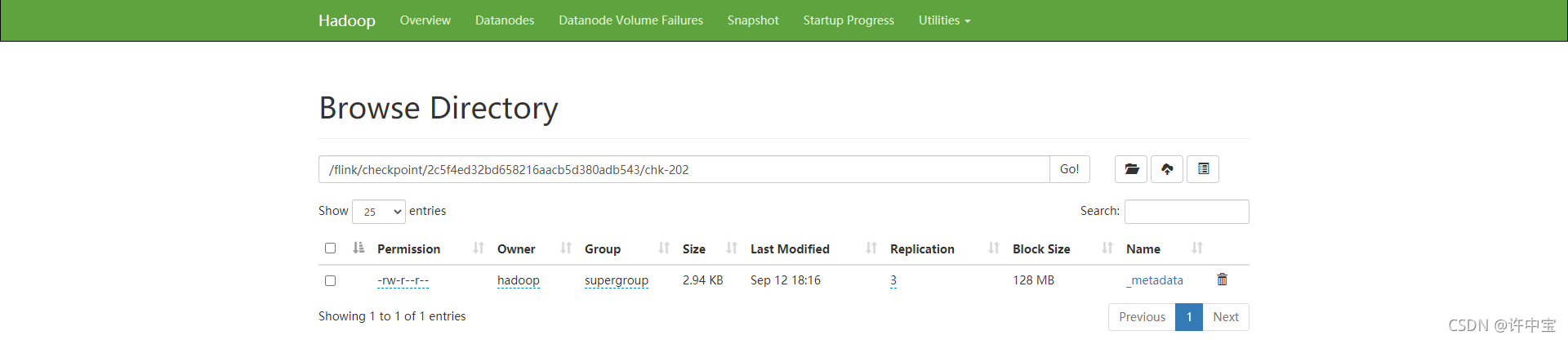
5. 从检查点恢复任务
-s:指定检查点文件
bin/flink run -t yarn-per-job \
-s hdfs://hadoop101:8020/flink/checkpoint/2c5f4ed32bd658216aacb5d380adb543/chk-202/_metadata \
-c com.xbz.bigdata.study.flink.state.KeyStateTest \
/opt/module/flink-1.13.2/myjobs/flink-study-1.0.0.jar
- 继续输入一个单词,验证计算结果是否是从5开始的?
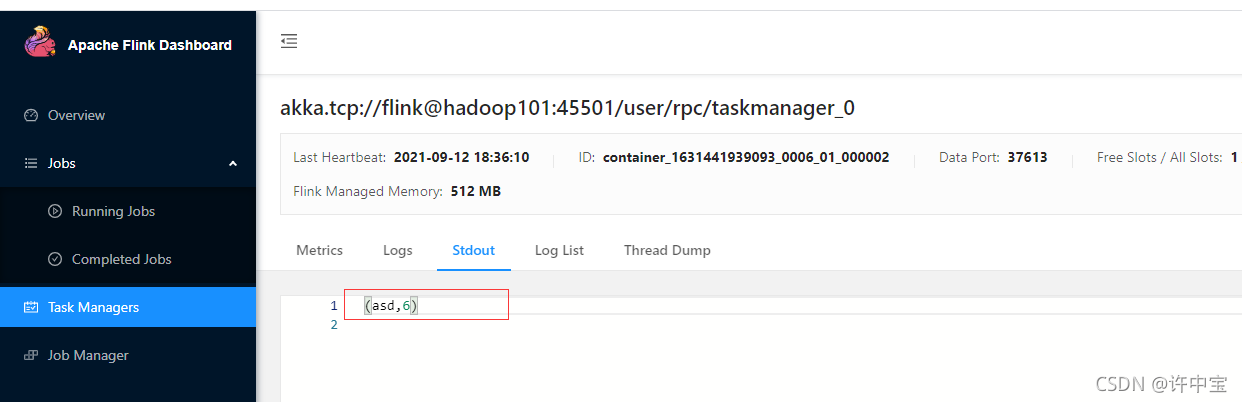
状态恢复成功!
从保存点恢复
7. 首先savepoint,当前jobid=36f3ad2725eeba680742a8442350b24d
解释:因为我们的job是在per-job模式下启动,所以在savepoint指令中需要通过-t yarn-per-job -Dyarn.application.id=application_1631441939093_0006才能执行savepoint,启动application_1631441939093_000是yarn集群的应用ID
bin/flink savepoint \
-t yarn-per-job \
-Dyarn.application.id=application_1631441939093_0006 \
36f3ad2725eeba680742a8442350b24d \
hdfs://hadoop101:8020/flink/savepoint/
此时hdfs中出现了一个文件夹
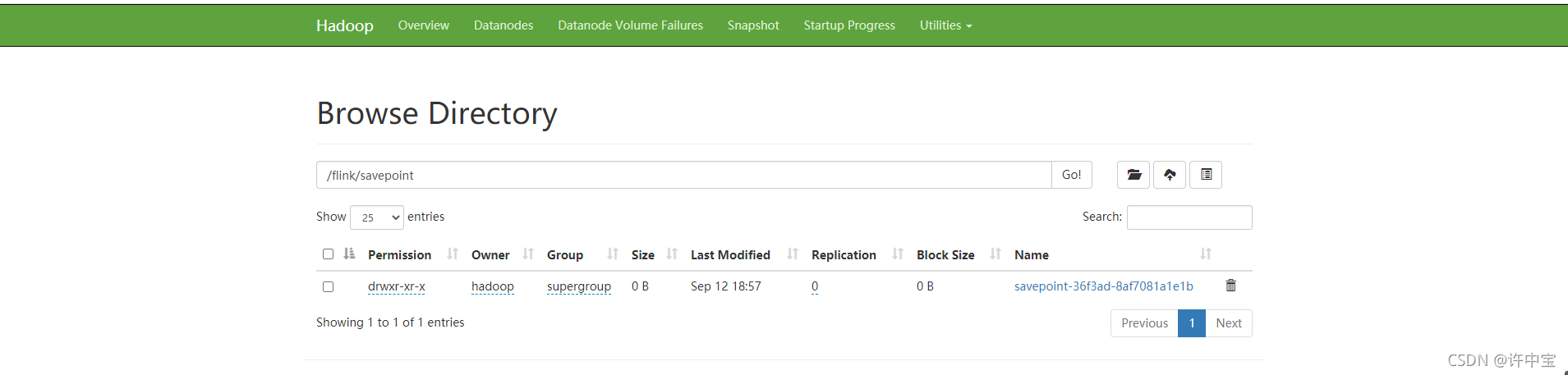
- 从保存点恢复
bin/flink run -t yarn-per-job \
-s hdfs://hadoop101:8020/flink/savepoint/savepoint-36f3ad-8af7081a1e1b/_metadata \
-c com.xbz.bigdata.study.flink.state.KeyStateTest \
/opt/module/flink-1.13.2/myjobs/flink-study-1.0.0.jar
输入一个单词,测试一下输出是否为7?
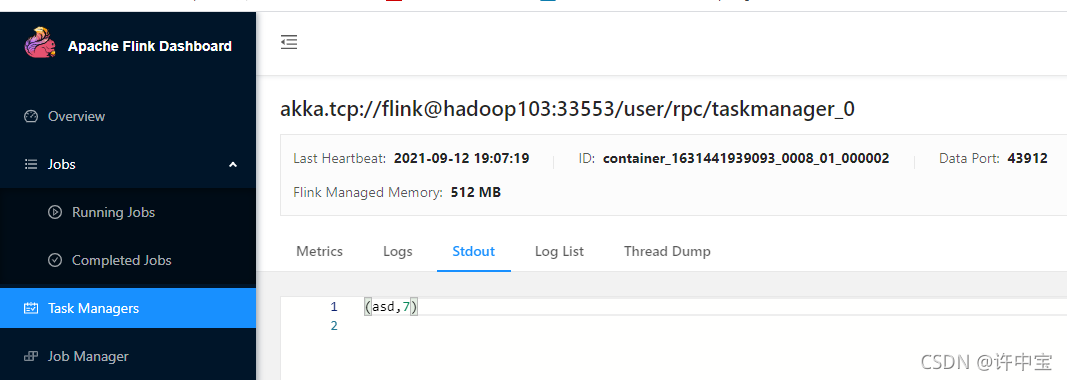
完毕!














 443
443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









