









一、oozie简介
Oozie是一个管理 Apache Hadoop 作业的工作流调度系统。
1、安装:
一是源生的,需要自己编译;(本文暂时不介绍具体的安装步骤,可以参考https://blog.csdn.net/lucylove3943/article/details/80673962)
二是CDH的包来安装,和源生类似;
三是Ambari上安装
2、Oozie的Web页面。

3、支持类型的Hadoop作业:
Oozie与Hadoop生态圈的其他部分集成在一起,支持多种类型的Hadoop作业(如Java map-reduce、流式map-reduce、Pig、Hive、Sqoop和Distcp)以及特定于系统的工作(如Java程序和shell脚本)。
4、主要概念:
4.1、Workflow:
工作流,由我们需要处理的每个工作组成,进行需求的流式处理。(一个具体的任务,例如执行一个mr)
4.2、Coordinator:
协调器,可以理解为工作流的协调器,可以将多个工作流协调成一个工作流来进行处理(例如可以控制workflow每天24点执行)。
4.3、Bundle:
捆,束。将一堆的coordinator进行汇总处理。
简单来说,workflow是对要进行的顺序化工作的抽象,coordinator是对要进行的顺序化的workflow的抽象,bundle是对一堆coordiantor的抽象。层级关系层层包裹。

Oozie的 workflow jobs 是由 actions 组成的 有向无环图(DAG)。

5、Job组成:
一个oozie 的 job 一般由以下文件组成:
1、job.properties :记录了job的属性(hdfs、yarn、workflow、定时任务等基本信息)
2、workflow.xml :使用hPDL 定义任务的流程和分支(定义任务的整体流程)
3、lib目录:用来执行具体的任务(例如需要执行mr任务的jar包)
下面是具体的说明:
1、Job.properties:

2、workflow.xml:
这个文件是定义任务的整体流程的文件,官网wordcount例子如下:

3、Lib目录
在workflow工作流定义的同级目录下,需要有一个lib目录,在lib目录中存在java节点MapReduce使用的jar包。
需要注意的是,oozie并不是使用指定jar包的名称来启动任务的,而是通过制定主类来启动任务的。在lib包中绝对不能存在某个jar包的不同版本,不能够出现多个相同主类。
注意:*********************************************************
下面的6、7、8可简略查看,内容比较详细,可以先看 二、“使用”后再翻过来回看。
6、工作流生命周期
在Oozie中,工作流的状态可能存在如下几种:
| 状态 | 含义说明 |
| PREP | 一个工作流Job第一次创建将处于PREP状态,表示工作流Job已经定义,但是没有运行。 |
| RUNNING | 当一个已经被创建的工作流Job开始执行的时候,就处于RUNNING状态。它不会达到结束状态,只能因为出错而结束,或者被挂起。 |
| SUSPENDED | 一个RUNNING状态的工作流Job会变成SUSPENDED状态,而且它会一直处于该状态,除非这个工作流Job被重新开始执行或者被杀死。 |
| SUCCEEDED | 当一个RUNNING状态的工作流Job到达了end节点,它就变成了SUCCEEDED最终完成状态。 |
| KILLED | 当一个工作流Job处于被创建后的状态,或者处于RUNNING、SUSPENDED状态时,被杀死,则工作流Job的状态变为KILLED状态。 |
| FAILED | 当一个工作流Job不可预期的错误失败而终止,就会变成FAILED状态。 |
上述各种状态存在相应的转移(工作流程因为某些事件,可能从一个状态跳转到另一个状态),其中合法的状态转移有如下几种,如下表所示:
| 转移前状态 | 转移后状态集合 |
| 未启动 | PREP |
| PREP | RUNNING、KILLED |
| RUNNING | SUSPENDED、SUCCEEDED、KILLED、FAILED |
| SUSPENDED | RUNNING、KILLED |
明确上述给出的状态转移空间以后,可以根据实际需要更加灵活地来控制工作流Job的运行。
7、控制流节点(相当于抽象顺序,不包含具体内容)
工作流程定义中,控制工作流的开始和结束,以及工作流Job的执行路径的节点,它定义了流程的开始(start节点)和结束(end节点或kill节点),同时提供了一种控制流程执行路径的机制(decision决策节点、fork分支节点、join会签节点)。通过上面提到的各种节点,我们大概应该能够知道它们在工作流中起着怎样的作用。下面,我们看一下不同节点的语法格式:
- start节点
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<start to="[NODE-NAME]" />
...
</workflow-app>
上面start元素的to属性,指向第一个将要执行的工作流节点。
- end节点
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<end name="[NODE-NAME]" />
...
</workflow-app>
达到该节点,工作流Job会变成SUCCEEDED状态,表示成功完成。需要注意的是,一个工作流定义必须只能有一个end节点。
- kill节点
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<kill name="[NODE-NAME]">
<message>[MESSAGE-TO-LOG]</message>
</kill>
...
</workflow-app>
kill元素的name属性,是要杀死的工作流节点的名称,message元素指定了工作流节点被杀死的备注信息。达到该节点,工作流Job会变成状态KILLED。
- decision节点
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<decision name="[NODE-NAME]">
<switch>
<case to="[NODE_NAME]">[PREDICATE]</case>
...
<case to="[NODE_NAME]">[PREDICATE]</case>
<default to="[NODE_NAME]" />
</switch>
</decision>
...
</workflow-app>
decision节点通过预定义一组条件,当工作流Job执行到该节点时,会根据其中的条件进行判断选择,满足条件的路径将被执行。decision节点通过switch…case语法来进行路径选择,只要有满足条件的判断,就会执行对应的路径,如果没有可以配置default元素指向的节点。
- fork节点和join节点
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<fork name="[FORK-NODE-NAME]">
<path start="[NODE-NAME]" />
...
<path start="[NODE-NAME]" />
</fork>
...
<join name="[JOIN-NODE-NAME]" to="[NODE-NAME]" />
...
</workflow-app>
for元素下面会有多个path元素,指定了可以并发执行的多个执行路径。fork中多个并发执行路径会在join节点的位置会合,只有所有的路径都到达后,才会继续执行join节点。
8、动作节点(Action Nodes)
工作流程定义中,能够触发一个计算任务(Computation Task)或者处理任务(Processing Task)执行的节点。
一个动作执行成功会转到ok节点;如果失败转向error节点。
- Map-Reduce动作
map-reduce动作会在工作流Job中启动一个MapReduce Job任务运行,我们可以详细配置这个MapReduce Job。另外,可以通过map-reduce元素的子元素来配置一些其他的任务,如streaming、pipes、file、archive等等。
下面给出包含这些内容的语法格式说明:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<action name="[NODE-NAME]">
<map-reduce>
<job-tracker>[JOB-TRACKER]</job-tracker>
<name-node>[NAME-NODE]</name-node>
<prepare>
<delete path="[PATH]" />
...
<mkdir path="[PATH]" />
...
</prepare>
<streaming>
<mapper>[MAPPER-PROCESS]</mapper>
<reducer>[REDUCER-PROCESS]</reducer>
<record-reader>[RECORD-READER-CLASS]</record-reader>
<record-reader-mapping>[NAME=VALUE]</record-reader-mapping>
...
<env>[NAME=VALUE]</env>
...
</streaming>
<!-- Either streaming or pipes can be specified for an action, not both -->
<pipes>
<map>[MAPPER]</map>
<reduce>
[REDUCER]
</reducer>
<inputformat>[INPUTFORMAT]</inputformat>
<partitioner>[PARTITIONER]</partitioner>
<writer>[OUTPUTFORMAT]</writer>
<program>[EXECUTABLE]</program>
</pipes>
<job-xml>[JOB-XML-FILE]</job-xml>
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
...
</configuration>
<file>[FILE-PATH]</file>
...
<archive>[FILE-PATH]</archive>
...
</map-reduce>
<ok to="[NODE-NAME]" />
<error to="[NODE-NAME]" />
</action>
...</workflow-app>
- Hive动作
Hive主要是基于类似SQL的HQL语言的,它能够方便地操作HDFS中数据,实现对海量数据的分析工作。HIve动作的语法格式如下所示:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.2">
...
<action name="[NODE-NAME]">
<hive xmlns="uri:oozie:hive-action:0.2">
<job-tracker>[JOB-TRACKER]</job-tracker>
<name-node>[NAME-NODE]</name-node>
<prepare>
<delete path="[PATH]" />
...
<mkdir path="[PATH]" />
...
</prepare>
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
...
</configuration>
<script>[HIVE-SCRIPT]</script>
<param>[PARAM-VALUE]</param>
...
</hive>
<ok to="[NODE-NAME]" />
<error to="[NODE-NAME]" />
</action>
...</workflow-app>
- Sqoop动作
Sqoop是一个能够在Hadoop和结构化存储系统之间进行数据的导入导出的工具,Sqoop动作的语法格式如下:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.2">
...
<action name="[NODE-NAME]">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>[JOB-TRACKER]</job-tracker>
<name-node>[NAME-NODE]</name-node>
<prepare>
<delete path="[PATH]" />
...
<mkdir path="[PATH]" />
...
</prepare>
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
...
</configuration>
<command>[SQOOP-COMMAND]</command>
<file>[FILE-PATH]</file>
...
</sqoop>
<ok to="[NODE-NAME]" />
<error to="[NODE-NAME]" />
</action>
...</workflow-app>
- Pig动作
pig动作可以启动运行pig脚本实现的Job,在工作流定义中配置的语法格式说明如下:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.2">
...
<action name="[NODE-NAME]">
<pig>
<job-tracker>[JOB-TRACKER]</job-tracker>
<name-node>[NAME-NODE]</name-node>
<prepare>
<delete path="[PATH]" />
...
<mkdir path="[PATH]" />
...
</prepare>
<job-xml>[JOB-XML-FILE]</job-xml>
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
...
</configuration>
<script>[PIG-SCRIPT]</script>
<param>[PARAM-VALUE]</param>
...
<param>[PARAM-VALUE]</param>
<argument>[ARGUMENT-VALUE]</argument>
...
<argument>[ARGUMENT-VALUE]</argument>
<file>[FILE-PATH]</file>
...
<archive>[FILE-PATH]</archive>
...
</pig>
<ok to="[NODE-NAME]" />
<error to="[NODE-NAME]" />
</action>
...</workflow-app>
- Fs动作
Fs动作主要是基于HDFS的一些基本操作,如删除路径、创建路径、移动文件、设置文件全乡等等。
语法格式:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<action name="[NODE-NAME]">
<fs>
<delete path='[PATH]' />
...
<mkdir path='[PATH]' />
...
<move source='[SOURCE-PATH]' target='[TARGET-PATH]' />
...
<chmod path='[PATH]' permissions='[PERMISSIONS]' dir-files='false' />
...
<touchz path='[PATH]' />
</fs>
<ok to="[NODE-NAME]" />
<error to="[NODE-NAME]" />
</action>
...</workflow-app>
- SSH动作
该动作主要是通过ssh登录到一台主机,能够执行一组shell命令,它在Oozie schema 0.2中已经被删除。
语法格式:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<action name="[NODE-NAME]">
<ssh>
<host>[USER]@[HOST]</host>
<command>[SHELL]</command>
<args>[ARGUMENTS]</args>
...
<capture-output />
</ssh>
<ok to="[NODE-NAME]" />
<error to="[NODE-NAME]" />
</action>
...</workflow-app>
- Java动作
Java动作,是执行一个具有main入口方法的应用程序,在Oozie工作流定义中,会作为一个MapReduce Job执行,这个Job只有一个Map任务。我们需要指定NameNode、JobTracker的信息,还有配置一个Java应用程序的JVM选项参数(java-opts),以及传给主函数(arg)。
语法格式:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<action name="[NODE-NAME]">
<java>
<job-tracker>[JOB-TRACKER]</job-tracker>
<name-node>[NAME-NODE]</name-node>
<prepare>
<delete path="[PATH]" />
...
<mkdir path="[PATH]" />
...
</prepare>
<job-xml>[JOB-XML]</job-xml>
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
...
</configuration>
<main-class>[MAIN-CLASS]</main-class>
<java-opts>[JAVA-STARTUP-OPTS]</java-opts>
<arg>ARGUMENT</arg>
...
<file>[FILE-PATH]</file>
...
<archive>[FILE-PATH]</archive>
...
<capture-output />
</java>
<ok to="[NODE-NAME]" />
<error to="[NODE-NAME]" />
</action>
...</workflow-app>
- Sub-workflow动作
Sub-workflow动作是一个子流程的动作,主流程执行过程中,遇到子流程节点执行时,会一直等待子流程节点执行完成后,才能继续跳转到下一个要执行的节点。
语法格式:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<action name="[NODE-NAME]">
<sub-workflow>
<app-path>[WF-APPLICATION-PATH]</app-path>
<propagate-configuration />
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
...
</configuration>
</sub-workflow>
<ok to="[NODE-NAME]" />
<error to="[NODE-NAME]" />
</action>
...</workflow-app>
- Shell动作
Shell动作可以执行Shell命令,并通过配置命令所需要的参数。它的语法格式:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.4">
...
<action name="[NODE-NAME]">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>[JOB-TRACKER]</job-tracker>
<name-node>[NAME-NODE]</name-node>
<prepare>
<delete path="[PATH]" />
...
<mkdir path="[PATH]" />
...
</prepare>
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
...
</configuration>
<exec>[SHELL-COMMAND]</exec>
<argument>[ARGUMENT-VALUE]</argument>
<capture-output />
</shell>
<ok to="[NODE-NAME]" />
<error to="[NODE-NAME]" />
</action>
...</workflow-app>
二、使用:
1、Oozie目录:(4.3.1版本)

主要:
bin:执行命令的
conf: 配置目录
lib: oozie的相关包
share: 上传到hadoop中需要配合运行oozie的包(上传到hdfs后oozie这里就不需要了)
examples : 这个examples是接下来要介绍的 oozie提交mr例子所需要的所有内容
- Oozie的使用
一:源生(下面以运行一个MR任务为例)
使用Oozie,就先进行源生安装,比较麻烦,需要配置一些东西,其中主要有基本的hdfs、yarn等地址,而且还有hdfs中conf的映射地址,需要上传到hdfs上的oozie的相关jar包和地址映射。
其中主要就是编写job中的配置,来用oozie规定的规范来编写自己的逻辑。
二:配合Hue使用
使用方便,直接在上面进行操作即可
- 源生运行MR任务为例:
3.1、配置job任务
刚才在oozie目录下,有个exmaples文件夹,已经介绍过了,这就是要运行一个mr任务所需要所有东西,他都由哪些文件组成呢?让我们来看一下:
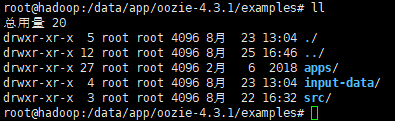
- apps:包含配置oozie任务所需要对应的文件
- Input-data: 里面是wordcount的一个txt文件
- src: mr的java代码
下面主要介绍apps :

图中标注的,即为“一、5 Job组成”中介绍的,三要素:Job.properties、Workflow.xml、Lib
其中:
Job.properties 内容如下:(记录了job的属性(hdfs、yarn地址等基本信息))

workflow.xml 内容如下:
定义了mr的任务的流程


这里面主要是运行mr action的内容。
lib目录:里面是该例子的jar包
3.2、上传到HDFS对应目录下(该目录映射在conf里有配置)
因为oozie可能没有在hdfs运行的主节点上,所以需要把所需的job配置和jar包等上传到hdfs中。
上传jar包、代码、相应的job配置到HDFS对应的目录下,实例如下。

3.3、启动Oozie
在oozie的安装目录下执行
bin/oozied.sh start
3.4、启动前提
运行oozie任务前,需要先启动hadoop,包括hdfs和yarn等。
注意:还需要启动jobhistory
命令:sbin/mr-jobhistory-daemon.sh start historyserver
3.5、启动mr的Job实例
选好oozie的地址,指定jon.properties启动,命令如下:
| bin/oozie job -oozie http://localhost:11000/oozie -config examples/apps/map-reduce/job.properties -run |

执行后,会返回一个job的id。
然后我们去看一下,oozie的web 界面:

我们点开这个Job,可以查看详情、任务配置、DAG图等信息


然后我们看hdfs上,有个目录,里面记录了job id的信息,有相应目录,说明提交已经成功。
然后查看输出任务,应该有相应的目录。

至此,demo流程基本上运行完毕~相信大家会有一个清晰的认识了,最后运行还是推荐在HUE上,比较方便。















 1757
1757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









