






一、mysql的整体架构
-
架构
(1)、server层
sql解析 链接池
(2)、引擎层
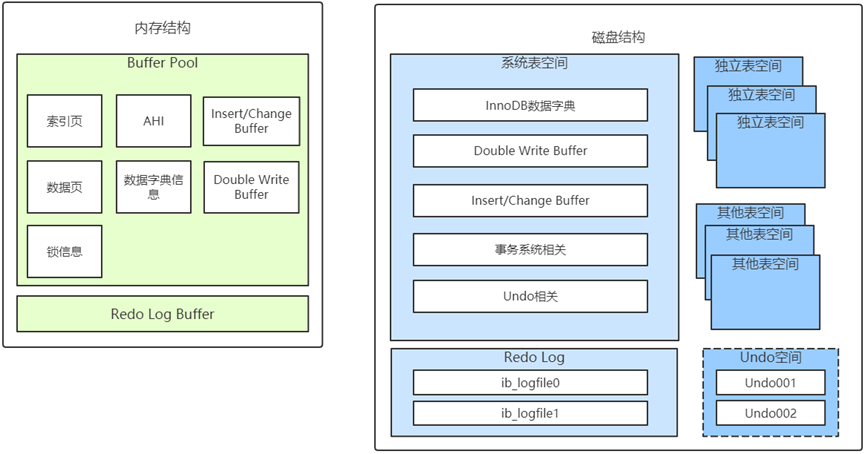
InnoDB 引擎、表 、 Page(16KB) 、连续空间buffer pool ( page 16K 、 chunk 16M)
InnoDB的三大特性: -
双写机制
-
为啥开发Buffer Pool 不用系统自带的page cache
-
自适应Hash索引
-
Change buffer 功能是临时缓冲辅助索引需要的数据更新。
-
、sql中的 聚合 取平均、最大 最小排序 合计 等聚合操作
mysql 的大多数 操作都是在内存中的buffer poo 中的page操作 然后定时刷page 到磁盘
- IO线程模型
Master、IO、 Purge (redo.log)、Page Cleaner(undo)
- 、什么是acid ,是如何保证的、事务的
redo \undo\ mvcc 读未提交 、幻读 、不可重复读、
- 索引分类
一定是有 聚簇索引、数据和索引在一块
二级索引(
它的聚簇索引记录中都包含两个必要的隐藏列(row_id并不是必要的,我们创建的表中有主键或者非NULL的UNIQUE键时都不会包含row_id列):
trx_id:每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务id赋值给trx_id隐藏列。
roll_pointer:每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。

写
二、调优 RBO 和CBO
type 中有类别
精确的 直接hash是system id = 716这种 const eq_ref ref range 和
index 索引覆盖,但需要扫描全部的索引记录时 最后是 全表扫描all
3、sql解析
词法分析 语法法系 语意分析
4、 事务问题
页的通用结构
Fil Header
Page Header
The Infimum and Supremum Records
Page Directory
Fil Trailer
行的结构
每条记录3个隐藏列(rowId,transactionId,rollPointer)
三、sql的执行过程(使用update语句做示例):
1.开启一个事务
2.执行一个更新操作
3.先从磁盘文件加载对应的数据到Buffer Pool
4.将旧值写入到undo日志中(事务的回滚会使用)
5.更新Buffer Pool的值
6.写redo log(保证事务的一致性,已提交的事务必然存在redo log,那怕发生系统宕机,也可以使用redo log恢复磁盘ibd文件数据)
7.返回客户端更新结果
8.提交事务
9.写bin log日志文件(主从同步,数据丢失时恢复数据)
10.返回客户端事务提交成功
问题
1、事务是每个session 有关系么
redo left join explain的关系
sql中的 聚合 取平均、最大 最小排序 合计 等聚合操作















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









