







目录
MYSQL索引
索引的作用
- 索引是一种提高检索效率的数据结构
- 如果没有索引就需要全盘扫描
索引是不是越多越好
- 索引只是提高了检索的效率,但是增删改操作需要维护索引,维护索引需要耗费数据库的资源和磁盘空间。所以要建立能够帮助提高检索效率的索引
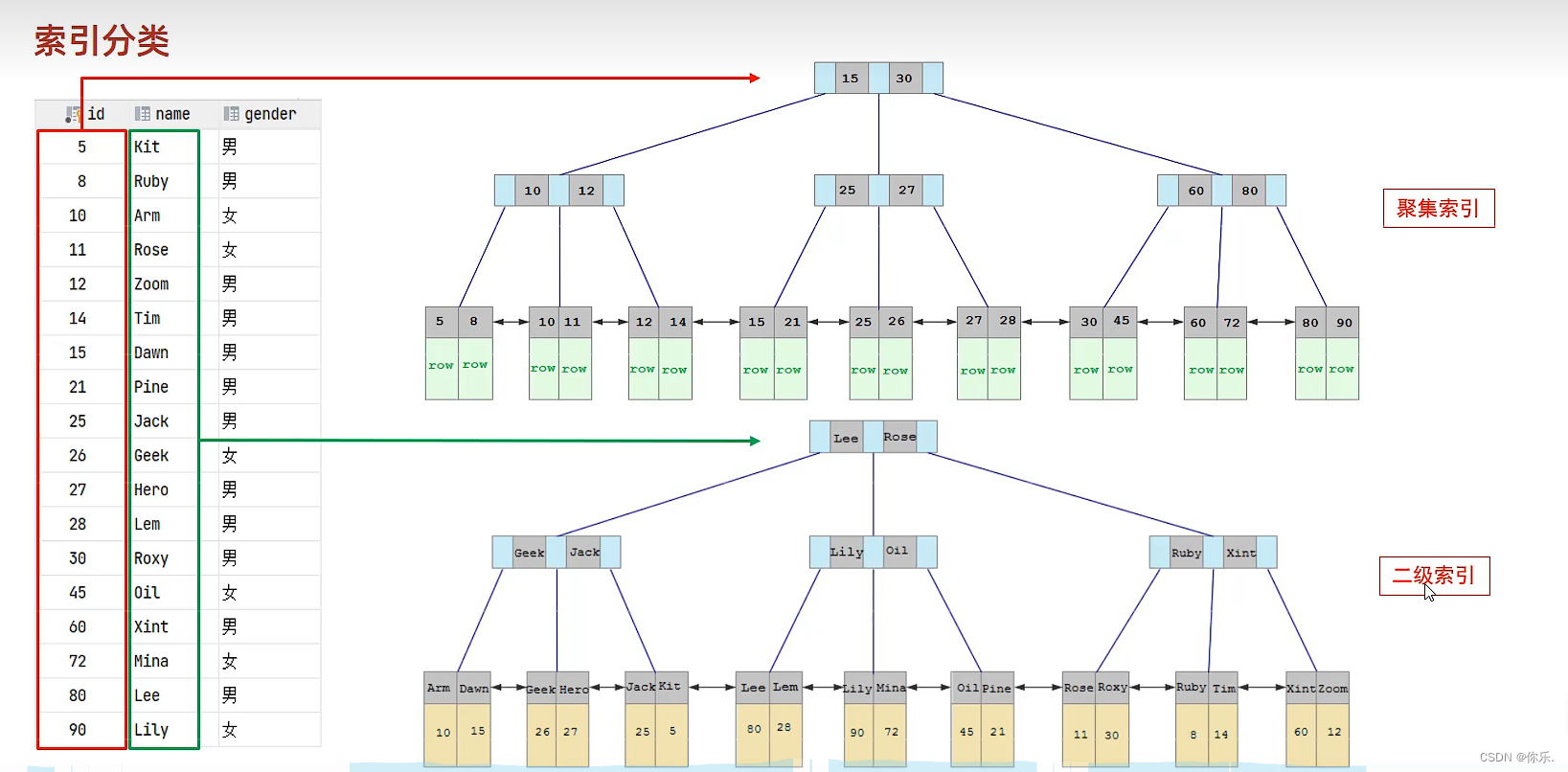
索引的分类
- 主键索引:在创建表时设为主键会自动创建索引,主键索引列值不能重复,不能为null,主键索引只能有一个,但是可以是联合主键索引
- 普通索引:一个索引只包含单个列,一个表可以有多个普通索引
- 唯一索引:唯一索引通常用来避免列值重复,允许有一个null值,一个表可以有多个唯一索引。
- 前缀索引:用来处理字符串比较长的索引,可以选取字符串的一部分前缀作为索引。
- 联合索引:一个索引包含多个列,可以有多个联合索引
#创建主键索引(设置为主键后自动创建主键索引)
create table user(id int(10) primary key,name varchar(20),age INT(3),address varchar(20))
#在建表的时候创建唯一索引
create table user1(id int(10) primary key,name varchar(20),age INT(3),address varchar(20),unique key(age))
#在建表后创建唯一索引
create unique index index_name on user(age)
#在建表的时候创建普通索引
create table user2(id int(10) primary key,name varchar(20),age INT(3),address varchar(20),key(address))
在建表后创建普通索引
create table index index_name on user(address)
#建表时创建联合索引
create table user(id int(10) primary key,name varchar(20),age INT(3),address varchar(20),key(address,age))
#建表后创建联合索引
create index index_name on user(address,age)
#前缀索引的选择性,选择性为1表示列值都唯一
select count(distinct substring(email,1,6))/count(*) from tb_user
#查看索引
show index from table_name
#删除索引
alter table user drop index index_name
drop index index_name on table_name复合索引原则
- 最左前缀原则
- Mysql引擎底层做优化,会动态的调整索引顺序以使用索引
索引底层的数据结构
B+树:‘
- B+树只有叶子节点存储数据
- 非叶子节点存储索引信息和指针
- 叶子节点的数据是排好序的,
- 叶子节点拥有双向链表指针,更有利于范围查询
聚簇索引和非聚簇索引
聚簇索引:数据存储和索引是存放在一起的,叶子节点保存了行数据(必须有,只有一个)
非聚簇索引:数据存储和索引是分开存储的,叶子节点保存了对应的主键值(可以有多个)
explain
explain sql语句可以查看当前sql索引的信息


- id:索引的序列号,id值相同,顺序为从上到下执行,id值不同,越大越先执行
- type:连接的类型,由好到差NULL、system、const、eq_ref、ref、range、index、all。使用主键、唯一索引会出现const 使用非唯一索引会出现ref
- key:实际用到的索引
- key_len:索引最大可能长度
索引覆盖和回表查询
索引覆盖:当前SQL查询的字段在当前索引上都包含了,因此就不需要回表查询,直接返回叶子节点的数据即可
联合索引的生效与失效
索引遵守最左匹配原则,从索引的最左列开始,不跳过索引中的列,如果跳过某一列(后面的索引会失效)
复合索引key(profession,age,status)
如果条件为单个索引并且不满足最左匹配原则,走索引的条件为:select后面为该复合索引的列和主键列




索引失效
- 范围>、<查询右边的索引会失效,使用>=、<=
- like模糊查询如果%在最前面索引会失效,如果在最后面不会
- or:连接的条件前后都要由索引,否则索引失效
- 在索引列上使用函数运算subString等,会索引失效
- 字符串类型或字符类型where后面的条件不加引号
#范围(>、<)查询右边的列索引会失效 只有profession生效
explain select * from tb_user user where profession="软件工程"
#profession和age生效
explain select * from tb_user user where age>44 and profession="软件工程" and status='0'
explain select * from tb_user user where profession="软件工程"
#全部生效
explain select * from tb_user user where age>=10 and profession="软件工程" and status='0'
#不要在索引列上使用函数运算操作,索引会失效
select SUBSTRING(phone,10,11) from tb_user
#字符和字符串类型使用时,不加引号,索引会失效
explain select * from tb_user where phone="17799990000" 使用了索引
explain select * from tb_user where phone=17799990000 没有使用索引
#使用like模糊查询,如果是尾部模糊查询走索引,如果是头部模糊,索引无效
EXPLAIN select * from user where name like "乐%" 生效
EXPLAIN select * from user where name like "%乐%" 不生效
EXPLAIN select * from user where name like "%乐" 不生效
#or连接的条件前后都需要有索引,才会走索引
#or连接的条件
explain select * from tb_user where age=44 or id=1 不走索引,age在复合索引里不满足最左匹配原则
explain select * from tb_user where profession="软件工程" or id=1走索引,profession在复合索引里满足最左匹配原则单列索引和唯一索引的选择
- 当查询的字段比较多时,使用联合索引
- 使用联合索引可以索引覆盖,避免回表查询
联合索引首先通过phone值进行排序存储,如果phone值相同通过name值进行排序存储生成B+树
联合唯一索引的第一列索引不能有重复值,允许有一个null值

设计原则















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









