










前三个命令是搜索字符串的,后三个命令搜索文件名的
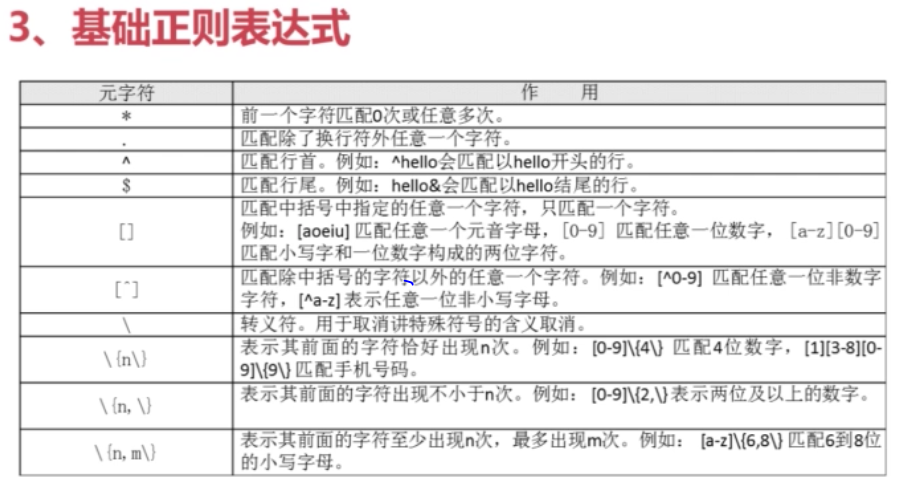

请注意:这里是包含匹配,只要包含有,就可以匹配,所以a*此时可以代表零个a,此时是空,包含匹配,就可以匹配任意字符。
例子:grep “aa*” test.txt




中括号之外的尖括号叫做行首,中括号之内的尖括号叫做取反







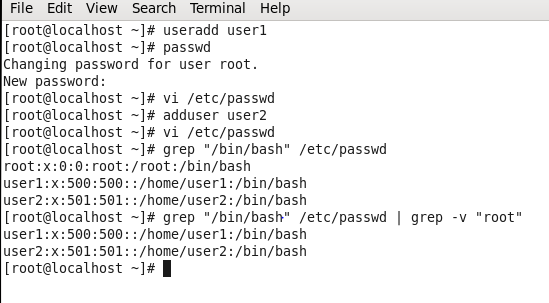
解释:先新建一个用户user1,user2,在/etc/passwd中搜索字符串“/bin/bash”,最后一个命令代表在/etc/passwd中搜索到包含”/bin/bash”的字符串,然后在结果中再搜索不包含“root”的结果
|代表管道符

grep是行提取命令,cut是列提取命令

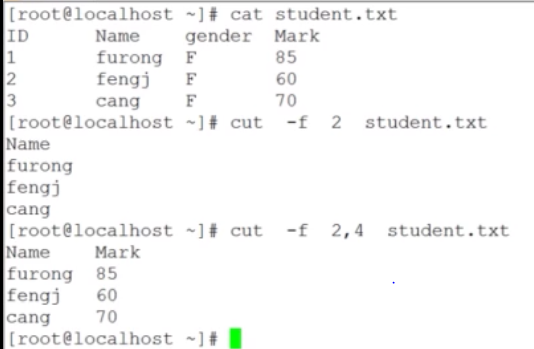
默认使用制表符进行分割

df是查看磁盘分区情况,
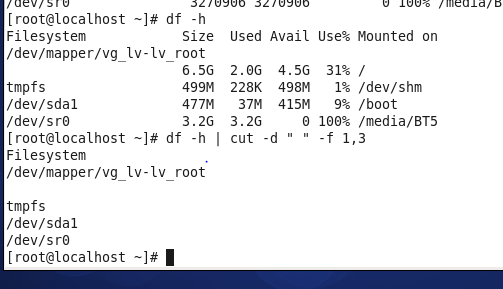
因为其中是以空格分开的,但是第一个后面有好多空格,就没法用此命令,进行获取了






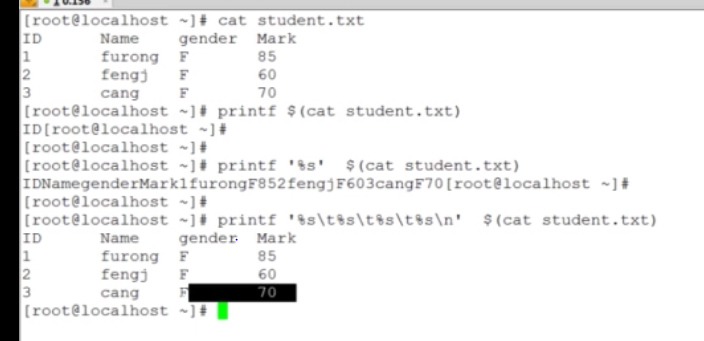


awk只支持printf不支持echo

1
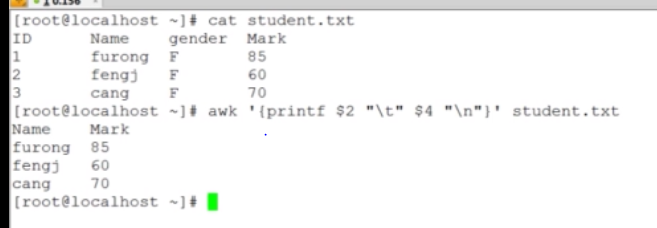
awk执行过程是一行一行的执行,先给文件附上0,然后第一行依次1,2,3,4,然后下一行,1,2,3,4等等等



begin,代表后面执行之前执行的动作第一个花括号代表begin的动作,第二个花括号没有条件所以,都执行


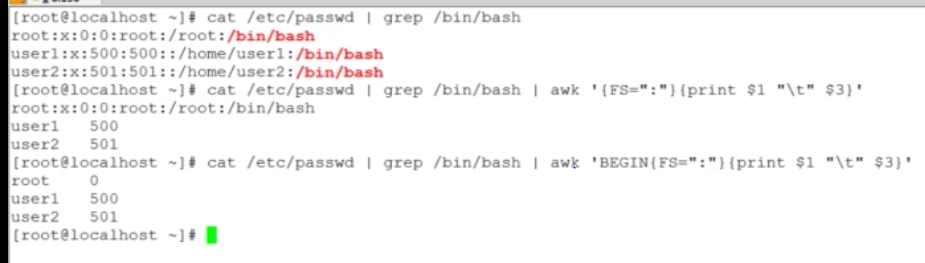
为什么会出现这种情况,一般执行的顺序是:先把/etc/passwd的结果全部赋值给$1,然后再执行FS=”:”已经晚了,第二个是执行所有动作之前先FS=”:”

例子
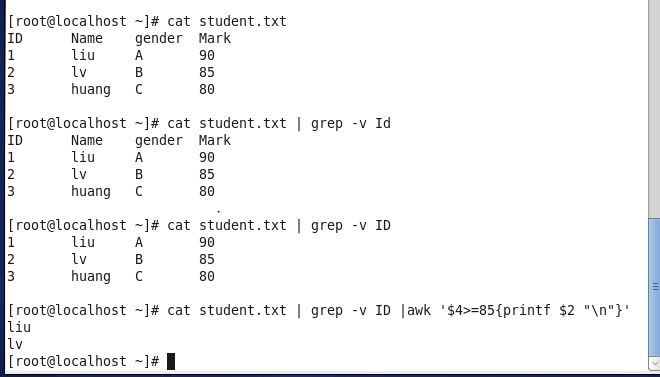

sed目的:替换字符串





此处没有加选项-i,因此只是用于输出显示,并不真正删除文件



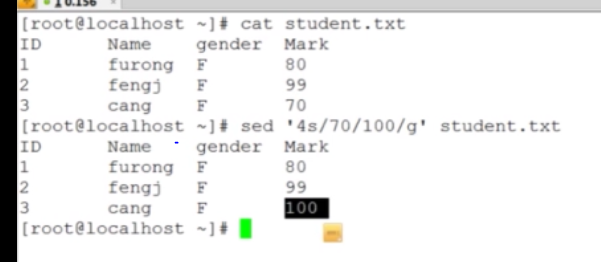
不加g代表只替换一个,加个g代表代替多个
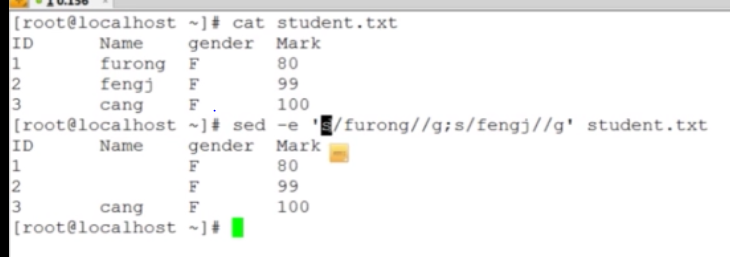


【】代表可选



字符包括空格,选项为空时,三个结果都有















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









