










01、JAVA基础
02、Java的collection接口继承关系


03、jdk1.7 用的是哪种垃圾回收机制 1.8用的是啥
jdk1.6 用的是 UseParallelGC, ParallelGCThreads=4 jdk1.8
$ java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=134217728
-XX:MaxHeapSize=2147483648
-XX:+PrintCommandLineFlags
-XX:+UseCompressedClassPointers
-XX:+UseCompressedOops
-XX:+UseParallelGC
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
UseParallelGC 即 Parallel Scavenge + Serial Old, 再查看详细信息
java -XX:+PrintGCDetails -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
Heap
PSYoungGen total 38400K, used 1331K [0x0000000795580000, 0x0000000798000000, 0x00000007c0000000)
eden space 33280K, 4% used [0x0000000795580000,0x00000007956cce48,0x0000000797600000)
from space 5120K, 0% used [0x0000000797b00000,0x0000000797b00000,0x0000000798000000)
to space 5120K, 0% used [0x0000000797600000,0x0000000797600000,0x0000000797b00000)
ParOldGen total 87552K, used 0K [0x0000000740000000, 0x0000000745580000, 0x0000000795580000)
object space 87552K, 0% used [0x0000000740000000,0x0000000740000000,0x0000000745580000)
Metaspace used 2233K, capacity 4480K, committed 4480K, reserved 1056768K
class space used 243K, capacity 384K, committed 384K, reserved 1048576K
04、List和Array的区别,添加和删除元素的时间复杂度怎样
-
因为Array是基于索引(index)的数据结构,它使用索引在数组中搜索和读取数据是很快的。Array获取数据的时间复杂度是O(1),但是要删除数据却是开销很大的,因为这需要重排数组中的所有数据。
-
相对于ArrayList,LinkedList插入是更快的。因为LinkedList不像ArrayList一样,不需要改变数组的大小,也不需要在数组装满的时候要将所有的数据重新装入一个新的数组,这是ArrayList最坏的一种情况,时间复杂度是O(n),而LinkedList中插入或删除的时间复杂度仅为O(1)。ArrayList在插入数据时还需要更新索引(除了插入数组的尾部)。
-
类似于插入数据,删除数据时,LinkedList也优于ArrayList。
-
LinkedList需要更多的内存,因为ArrayList的每个索引的位置是实际的数据,而LinkedList中的每个节点中存储的是实际的数据和前后节点的位置。
5) Array和List都属于顺序表。Array、ArrayList是一段连续的存储结构
05、红黑树添加元素和获取元素的时间复杂度
插入一个元素到红黑树的时间为 O(log(N))*,其中 *N 为当前红黑树的元素个数,因此,采用插入方式构建元素个数为N的红黑树的时间复杂度为:
log(1) + log(2) + log(N-1) = log((N-1)!) = Nlog(N)
那么采用迭代器遍历一棵红黑树的时间复杂度是多少呢?是 O(N) 。也就是说非递归遍历一棵红黑树的时间复杂度和遍历数组的时间复杂度是一样的
原文链接:https://blog.csdn.net/gongyiling3468/article/details/47804223
06、CMS垃圾收集器
[
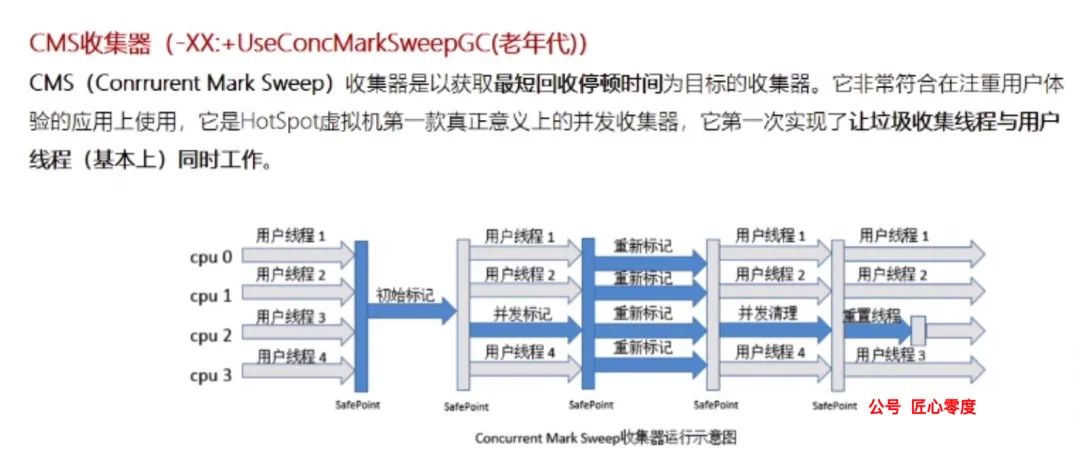
[

[

07、线程池原理,增长策略,拒绝策略哪几种,四种线程池分别有什么优缺点,有什么坑,线程池使用该怎么选择
-
线程池原理:复用Thead线程,减少创建和回收的CPU、内存资源消耗,过多任务加入等待队列或拒绝
-
增长策略:当前线程数 < 核心线程 : 直接开启新线程执行任务 当前线程数 > 核心线程 : 加入等待队列 队列已满& 当前线程数 < 最大线程 : 开启新线程 队列已满& 当前线程数 > 最大线程 : 执行拒绝策略
-
拒绝策略
-
CallerRunsPolicy:只要线程池没有被关闭,那么由提交任务的线程自己来执行这个任务
-
AbortPolicy:不管怎样,直接抛出 RejectedExecutionException 异常, 这个是默认的策略, 如果我们构造线程池的时候不传相应的 handler 的话,那就会指定使用这个
-
DiscardPolicy:不做任何处理,直接忽略掉这个任务
-
DiscardOldestPolicy:这个相对霸道一点,如果线程池没有被关闭的话, 把队列队头的任务(也就是等待了最长时间的)直接扔掉,然后提交这个任务到等待队列中
-
-
线程池对比
-
FixedThreadPool是一个典型且优秀的线程池,它具有线程池提高程序效率和节省创建线程时所耗的开销的优点。但在线程池空闲时,即线程池中没有可运行任务时,它不会释放工作线程,还会占用一定的系统资源。
-
CachedThreadPool的特点就是在线程池空闲时,即线程池中没有可运行任务时,它会释放工作线程,从而释放工作线程所占用的资源。但是,但当出现新任务时,又要创建一新的工作线程,又要一定的系统开销。并且,在使用CachedThreadPool时,一定要注意控制任务的数量,否则,由于大量线程同时运行,很有会造成系统瘫痪
-
08、锁粗化、锁消除
-
锁粗化(程序员控制) 通常情况下,为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽可能短,但是大某些情况下,一个程序对同一个锁不间断、高频地请求、同步与释放,会消耗掉一定的系统资源,因为锁的轻求、同步与释放本身会带来性能损耗,这样高频的锁请求就反而不利于系统性能的优化了,虽然单次同步操作的时间可能很短。
锁粗化就是告诉我们任何事情都有个度,有些情况下我们反而希望把很多次锁的请求合并成一个请求,以降低短时间内大量锁请求、同步、释放带来的性能损耗。
一种极端的情况如下:
public void doSomethingMethod(){
synchronized(lock){
//do some thing
}
//这是还有一些代码,做其它不需要同步的工作,但能很快执行完毕
synchronized(lock){
//do other thing
}
}
上面的代码是有两块需要同步操作的,但在这两块需要同步操作的代码之间,需要做一些其它的工作,而这些工作只会花费很少的时间,那么我们就可以把这些工作代码放入锁内,将两个同步代码块合并成一个,以降低多次锁请求、同步、释放带来的系统性能消耗,合并后的代码如下:
public void doSomethingMethod(){
//进行锁粗化:整合成一次锁请求、同步、释放
synchronized(lock){
//do some thing
//做其它不需要同步但能很快执行完的工作
//do other thing
}
}
注意:这样做是有前提的,就是中间不需要同步的代码能够很快速地完成,如果不需要同步的代码需要花很长时间,就会导致同步块的执行需要花费很长的时间,这样做也就不合理了。
-
锁消除 锁消除是发生在编译器级别的一种锁优化方式。有时候我们写的代码完全不需要加锁,却执行了加锁操作。虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行削除。锁削除的主要判定依据来源于逃逸分析的数据支持,如果判断到一段代码中,在堆上的所有数据都不会逃逸出去被其他线程访问到,那就可以把它们当作栈上数据对待,认为它们是线程私有的,同步加锁自然就无须进行。
锁消除前提是java必须运行在server模式(server模式会比client模式作更多的优化),同时必须开启逃逸分析:
-server -XX:+DoEscapeAnalysis -XX:+EliminateLocks
其中+DoEscapeAnalysis表示开启逃逸分析,+EliminateLocks表示锁消除。
09、异步thrift原理
服务方起草接口标准,负责实现,RPC框架生成服务端和客户端代理,服务端代理自启动,客户端代理绑定调用方,调用方按照接口标准,调用客户端代理,等价于RPC远程调用服务方实现
[

定义一个Thrift Service
//1. IDL编写的接口
service AddService {
int add(1:int n1, 2:int n2)
}
Thrift Service方法会提供两种类型的实现:
-
Iface
-
AsyncIface
//2. thrift.exe生成接口的客户端代理 - 异步实现
class AddService{
static class AsyncClient {
void add(int n1, int n2, AsyncMethodCallback callback) {
...
}
}
//3. 接口的服务端实现
class AddServiceImpl implements AddService.Iface {
int add(int n1, int n2)
return n1 + n2;
}
}
//4. 服务端监听
TNonblockingServerSocket socket = new TNonblockingServerSocket(9090);
TServer server = new TNonblockingServer(socket, AddServiceImpl);
server.start();
外部的调用过程就是,先获得一个CallBack,然后调用start方法。
//5. 客户端请求
TNonblockingTransport socket = new TNonblockingSocket("localhost", 9090);
AddService.AsyncClient client = new AddService.AsyncClient(socket);
client.add(1,2,new AsynCallback(this){
void onComplete() {
...
}
void onError(Exception exception) {
...
}
}
});
异步使用原则如果使用了AsynIface实现Service,需要注意几点:
-
不能直接在方法内处理req,req需要和handler(callback)封装交给另外的线程进行处理(暂且把这些线程叫做worker线程)
-
worker线程只做计算逻辑,也就是根据req的要求进行操作,在操作req结束以后获得的resp或者error,不能直接调用handler(callback)的方法(因为callback中的方法是一个网络IO的操作,有可能会block当前线程,如果网络IO操作是一个异步操作的话就不会block当前线程)
10、讲几个jvm优化的案例
11、堆外内存泄漏怎么排查
异常堆栈 [

top信息

一定时间过后,java 进程内存增长到接近 90%,服务器报警。此时 old 区内存在 50%左右,由于未达到 CMS GC 的阈值,因此不会触发 CMS GC,而导致服务器内存溢出崩溃。
-
堆外内存计算方式
-
广义堆外内存为:进程内存 - (Young 区占用 + Old 区占用),可通过直接内存大小参数:
-神器:MaxDirectMemorySize设置, JVM申请直接内存时,会判断是否超过可申请的直接内存阈值,如果超过则会调用System.gc()触发GC,如果 GC 后内存还是不足,则抛出OutOfMemoryError异常 -
狭义堆外内存为:
java.nio.DirectByteBuffer创建的时候分配的内存
-
-
查看堆内存命令
jstat -gc 1000 : 每秒输出堆内存实际大小信息 jstat -gcutil 1000 : 每秒输出堆内存百分比信息
-
jvisual VM可视化监控内存实时情况, 通过dump文件可以找到对象的引用根节点。
-
jmeter压测;
-
为了分析堆外内存到底是谁占用了,不得不安装
google-perftools工具进行分析,它的原理是在java应用程序运行时,当调用malloc时换用它的libtcmalloc.so,这样就能做一些统计了
1
JAVA核心面试题库(1000+题)

2
JAVA常见面试题库(3000+题)

3
Java各知识点综合面试题(5000+题)
这套题库里面中包含了以下很多个模块:并发编程,多线程,集合框架,设计模式,数据库,性能优化,RabbitMQ消息中间件,ActiveMQ消息中间件,Dubbo,JVM,Kafka,MongoDB,MyBatis,MySQL,Netty,Nginx,Redis,Tomcat,Zookeeper,Spring,SpringBoot,SpringCloud,SpringMVC,.......


4
互联网一线大厂面试题库(300+题)
这套题库里面中包含了以下很多个公司:百度篇,京东篇,腾讯篇,头条篇,美团篇,华为篇,滴滴篇,........


5
程序员必备书单
其中很多书籍都是非常不错的,值得大家研读(这里仅作为学习之用,分享给大家)
















 114
114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









