






一、项目中引入相关依赖
<!--springboot 操作jdbc的启动依赖包-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<!--springboot druid数据源启动依赖包-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.5</version>
</dependency>
<!--mysql数据库驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
说明:由于springboot已经做了部分依赖的版本控制,所以这里的mysql数据库驱动包可以不指定包版本,springboot 2.6.0版本默认指定的mysql驱动包版本为8.0 ,如果想覆盖springboot默认的依赖,可以在自定义的pom.xml中指定需要的版本号(利用的是maven最近依赖原则)


二、配置数据库连接属性
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
username: root
password: 123456
url: jdbc:mysql://localhost:3306/test
type: com.alibaba.druid.pool.DruidDataSource # 指定druid数据源说明:由于spring-boot-starter-data-jdbc 中默认使用的是Hikari数据源,所以使用druid数据源需要配置spring.datasource.type的类型

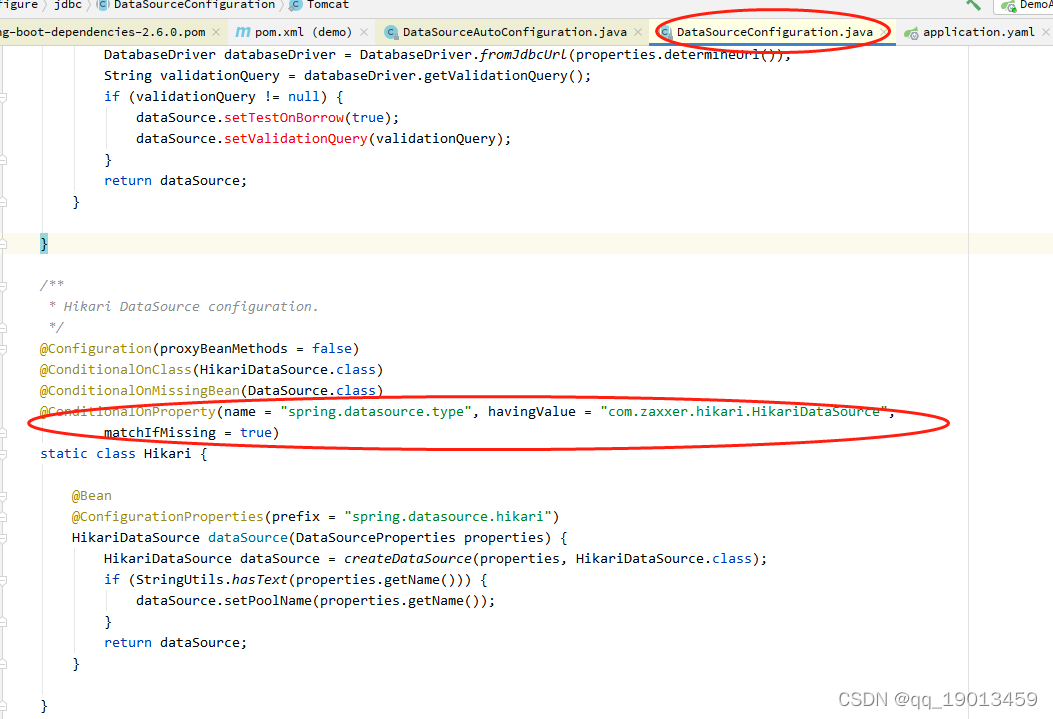
三、自定义druid配置文件
package com.example.demo.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
/**
* Druid数据源配置
*/
@Configuration
public class DruidConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
// 指定配置前缀为spring.datasource后,配置文件中不需要加上druid
public DataSource druidDataSource(){
return new DruidDataSource();
}
/**
* 后台管理servlet
* @return
*/
@Bean
public ServletRegistrationBean statViewServlet() {
ServletRegistrationBean servletRegistrationBean =
new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
//设置初始化参数参数
Map<String, String> initParameters = new HashMap<>();
//配置登录用户名和密码
initParameters.put("loginUsername","admin");
initParameters.put("loginPassword", "123456");
servletRegistrationBean.setInitParameters(initParameters);
return servletRegistrationBean;
}
/**
* 配置web监控Filter
*/
@Bean
public FilterRegistrationBean webViewFilter(){
FilterRegistrationBean<WebStatFilter> filterFilterRegistrationBean =
new FilterRegistrationBean<>();
filterFilterRegistrationBean.setFilter(new WebStatFilter());
//设置初始化参数参数
Map<String, String> initParameters = new HashMap<>();
//排除不需要过滤的地址
initParameters.put("exclusions",".js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*");
filterFilterRegistrationBean.setInitParameters(initParameters);
//过滤所有请求
filterFilterRegistrationBean.setUrlPatterns(Arrays.asList("/*"));
return filterFilterRegistrationBean;
}
}
说明:
1. druidDataSource()手动注入DruidDataSource对象,指定配置文件前缀 spring.datasource
注:可以使用默认的druid的数据源对象 ,默认指定的配置前缀为 spring.datasource.druid


2.statViewServlet()方法是开启了druid的后台管理系统,其中后台管理的servlet,使用的是springboot集成原生servlet的方式,使用ServletRegistrationBean向容器中注入StatViewServlet(还有一种方式是使用@WebServlet)
注:还可以直接在配置文件中配置stat-view-servlet属性,配置StatViewServlet
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
username: root
password: 123456
url: jdbc:mysql://localhost:3306/test
type: com.alibaba.druid.pool.DruidDataSource
filters: stat,wall
druid:
stat-view-servlet:
enabled: true
login-username: admin
login-password: 123456
直接配置原理:


3.webViewFilter()方法使用FilterRegistrationBean向容器中注入WebStatFilter(还有一种方式是使用@WebFilter),开启的是Web应用、URI监控、Session监控

注:还可以直接在配置文件中配置web-stat-filter属性,配置WebStatFilter
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
username: root
password: 123456
url: jdbc:mysql://localhost:3306/test
type: com.alibaba.druid.pool.DruidDataSource
filters: stat,wall
druid:
web-stat-filter:
enabled: true
直接配置原理:


四、配置文件中指定druid配置
spring:
datasource:
# 数据源基本配置
username: root
password: 123456
url: jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf-8
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
#数据源其他配置
#初始化时建立物理连接的个数
initial-size: 5
#最小连接池数量
min-idle: 5
#最大连接池数量 maxIdle已经不再使用
max-active: 20
#获取连接时最大等待时间,单位毫秒
max-wait: 60000
#申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
test-while-idle: true
#既作为检测的间隔时间又作为testWhileIdel执行的依据
time-between-eviction-runs-millis: 60000
#销毁线程时检测当前连接的最后活动时间和当前时间差大于该值时,关闭当前连接
min-evictable-idle-time-millis: 30000
#用来检测连接是否有效的sql 必须是一个查询语句
#mysql中为 select 'x'
#oracle中为 select 1 from dual
validation-query: select 'x'
#申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-on-borrow: false
#归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-on-return: false
# 是否缓存preparedStatement
pool-prepared-statements: true
#配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
#配置监拉统计挡成的filters. stat: 监控统计、Log4j:日志记录、waLL: 防御sqL注入
filters: stat,wall
max-pool-prepared-statement-per-connection-size: 20
use-global-data-source-stat: true
connect-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000说明:这里的filters不指定stat的话,druid无法监控sql语句
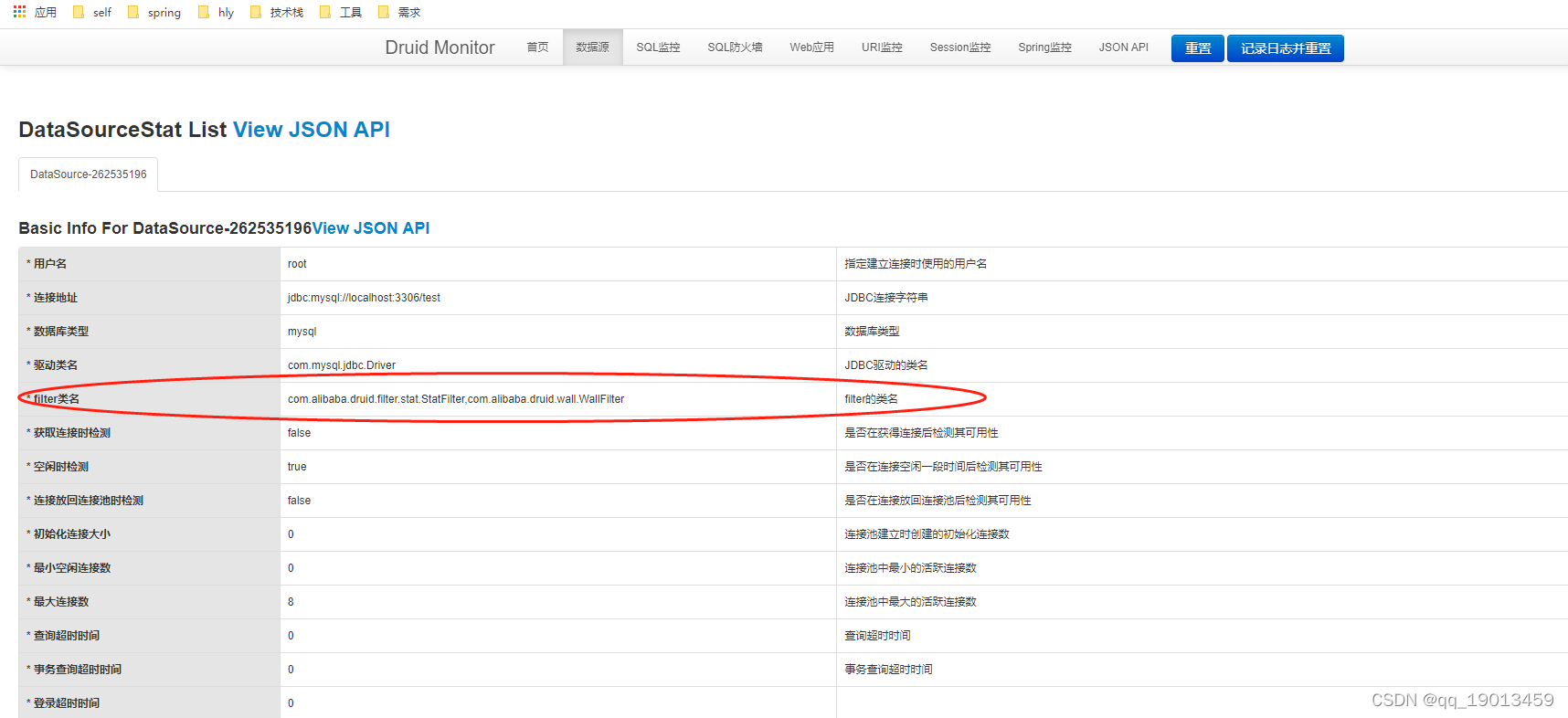
五、验证
发送http://localhost:8082/druid/login.html请求,进入登录页面,用之前配置的用户名密码登录进系统,然后发送查询数据请求http://localhost:8082/data/testData

得到监控数据















 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









