







重要说明:文章教程仅供参考学习,请勿用于非法用途,否则后果自负。
目录
1、问题描述
注意点:搜狗微信在用户未登录的情况下,默认只显示10页的数据,最多只显示100条数据。
该网站具有反爬措施,目前的主要的反爬措施是:访问频繁会弹验证码。如果访问频繁:
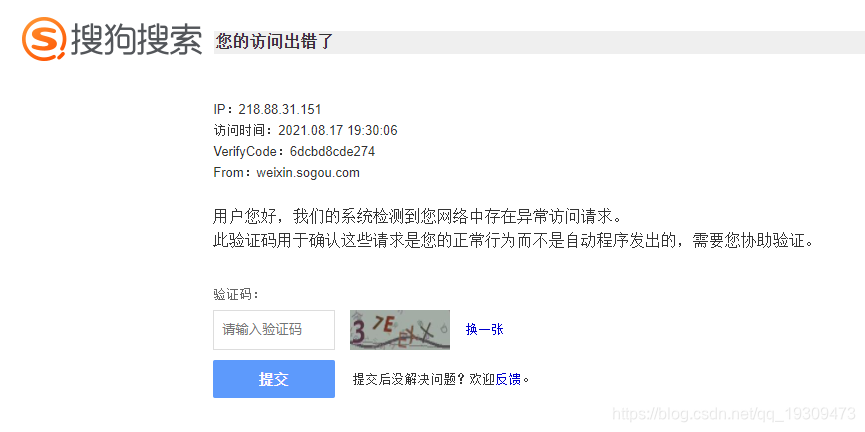
2、解决思路
在搜狗微信中,最主要的反爬Cookie参数是SNUID和SUV,其中最重要的反爬参数是SNUID,这个参数具有时效性,根据我的实际测试情况
重要说明:文章教程仅供参考学习,请勿用于非法用途,否则后果自负。
目录
注意点:搜狗微信在用户未登录的情况下,默认只显示10页的数据,最多只显示100条数据。
该网站具有反爬措施,目前的主要的反爬措施是:访问频繁会弹验证码。如果访问频繁:
在搜狗微信中,最主要的反爬Cookie参数是SNUID和SUV,其中最重要的反爬参数是SNUID,这个参数具有时效性,根据我的实际测试情况
 747
1279
747
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文

























