







HashMap构成
HashMap结合了数组和链表的特性,使得查询与数据插入和删除速度都最快。
HashMap首先是一个Entry类型的数组,Entry是一个单向的链表结构,每一个Entry实体包括一对key、value值,
Entry如下:
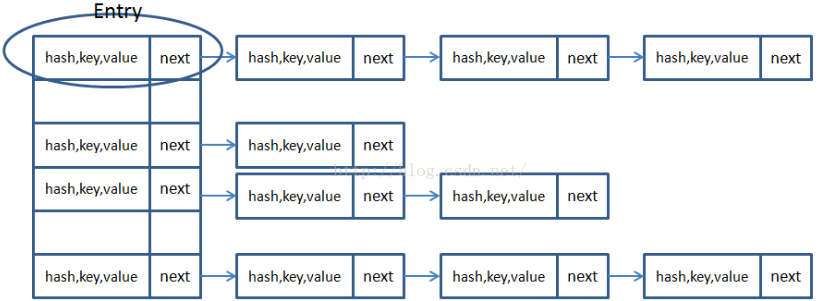
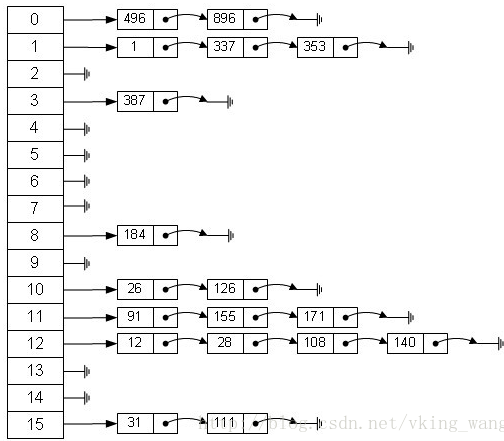
HashMap结构如下:
put方法
put方法分为key为非null和null的情况:
- 值非为
null的情况:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍历链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
- 值为
null的情况:
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
可以看出,在进行put的时候,首先根据key的hash值计算其index值,计算方式一般为取模:
index = hash(key.HashCode()) % length-1
length为Entry数组的长度,并且在Java的HashMap中一般对key进行两次哈希运算,以免hash值重复。
在index位置找到Entry对应的元素之后,验证对应该key的hash值是否存在,以及hash值相等时其key值是否相等(如果hash值相等而key值不相等,就出现了hash冲突,后面解释解决hash冲突的两种方法:分离链表法和开放定址法)。
get方法
get方法就比较简单了,找到key对应的index,在index位置取出Entry链,挨个比较hash值以及key的值。
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
哈希冲突
put操作时如果hash相等而key不相等,一般会有4种办法解决。
- 分离链表法
在已存在的冲突的key值上(hash值相等而key却不等),形成一个单链表,将put进来的冲突的key-value放在链表尾部。当链表长度大于8时,将其转换为红黑树。 - 开放定址法:采用线性探测(从相同hash值开始,继续寻找下一个可用的槽位)hashMap是数组,长度虽然可以扩大,但用线性探测法去查询槽位查不到时怎么办?因此hashMap采用了分离链表法。
- 再哈希法:使用其他函数再次计算哈希值
- 建立公共溢出区:将哈希表分为基本表和溢出表,发生冲突时,将冲突的元素放入溢出表。
resize的实现
初始化数组或者扩容为2倍。hashmap实例里的元素个数大于threshold时执行resize(threshold=桶数量*负载因子),扩容为2倍时,原下标的数据(一个链表上的数据)有一般概率留在原地,一般概率上升到高位位置。
下图作说明:

推荐阅读
HashMap源码分析(JDK1.8)- 你该知道的都在这里了
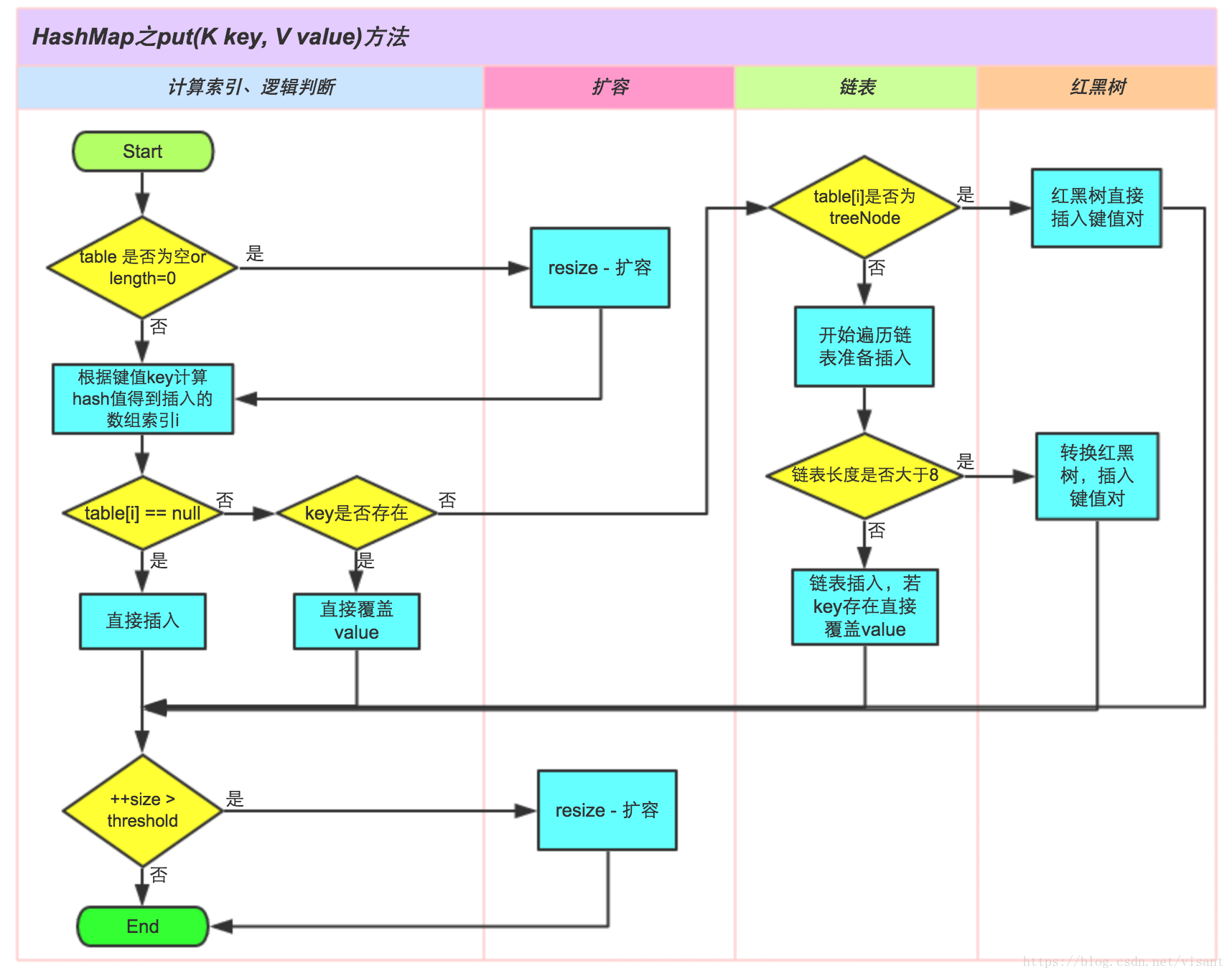
一个比较好的流程图















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









