







 本文介绍了在业务开发中如何利用poi-tl库来生成包含动态表格的Word文档,特别是涉及表格单元格的合并。通过对比freemarker,作者选择了poi-tl,因为它允许直接使用Word模板,简化了格式调整。文中详细阐述了引入相关依赖、创建模板、以及在Java代码中实现单元格合并的步骤,并提供了具体的代码示例。
本文介绍了在业务开发中如何利用poi-tl库来生成包含动态表格的Word文档,特别是涉及表格单元格的合并。通过对比freemarker,作者选择了poi-tl,因为它允许直接使用Word模板,简化了格式调整。文中详细阐述了引入相关依赖、创建模板、以及在Java代码中实现单元格合并的步骤,并提供了具体的代码示例。
一、背景
在业务开发过程中,遇到有需要生成包含表格的word文档,且一部分表格需要动态生成,且需要根据数据来合并单元格,最后呈现的方式如下图:
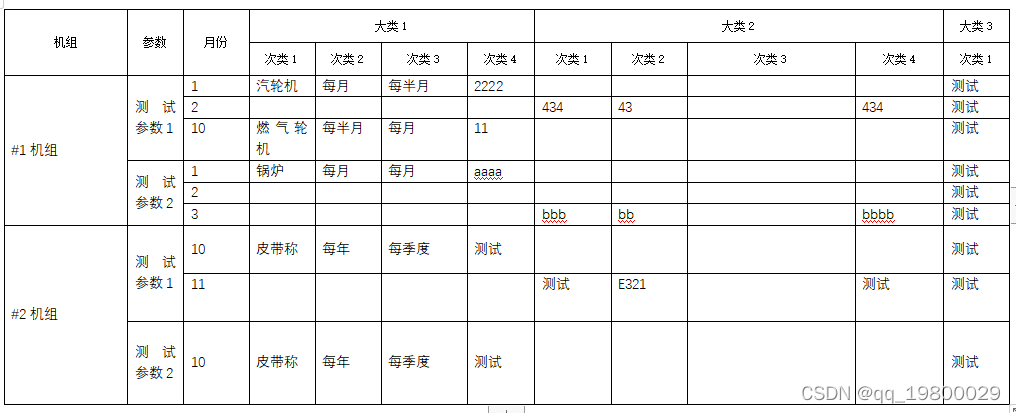
一开始想到的解决方案是通过freemarker来生成,但是需要转xml生成模板,过程比较复杂,因此,在查阅一些资料后,最终选择了poi-tl来实现。相比于freemarker,poi-tl导出word的好处在于可以直接使用word模板,比较直观,且比较好调整格式。
二、实现
1、引入jar包
<!-- word导出 -->
<dependency>
<groupId>com.deepoove</groupId>
<artifactId>poi-tl</artifactId>
<version>1.12.2</version>
</dependency>
<!-- 画图表 -->
<!-- 主要是word自带的图表插入生成之后前端预览不了,故而采用jfreechart画图表转图片插入的形式 -->
<dependency>
<groupId>org.jfree</groupId>
<artifactId>jfreechart</artifactId>
<version>1.5.4</version>
</dependency>2、构造word模板
1)简单包含属性的表格模板
| 姓名 | {{name}} | 年龄 | {{age}} |
| 身份证号 | {{idCardNo}} | 家庭住址 | {{addr}} |
| 联系电话 | {{tel}} | 学历 | {{education}} |
| 是否党员 | {{isPartyMember}} | 毕业院校 | {{school}} |
| 紧急联系人 | {{contactPer}} | 紧急联系方式 | {{contactTel}} |
| 邮箱 | {{email}} |
2)需要动态循环list生成行的表格模板
| {{userList}} 姓名 | 性别 | 年龄 |
| [name] | [sex] | [age] |
3)需要动态循环list生成列的表格模板
| {{userList}} 属性 | 值 |
| 属性1 | [value1] |
| 属性2 | [value2] |
4)需要动态合并单元格的表格模板
| {{userList}}班级 | 小组 | 姓名 | 学号 |
合并单元格操作需要在代码实现
3、代码实现合并单元格
public void export(HttpServletResponse response, Req params) throws IOException {
String templatePath = "/template/test.docx";
//数据源
Map<String, Object> dataMap = new HashMap<>();
// 定义导出数据策略
Configure config = Configure.builder()
.useSpringEL()
.bind("list1", new LoopRowTableRenderPolicy()) //行循环策略
.bind("list2", new LoopColumnTableRenderPolicy()) //列循环策略
.bind("tableList",new ReportDataPolicy()) //自定义合并单元格策略
.build();
InputStream is = null;
OutputStream out = null;
try {
ClassPathResource classPathResource = new ClassPathResource(templatePath);
is = classPathResource.getInputStream();
File sourceFile = File.createTempFile(String.valueOf(System.currentTimeMillis()), ".docx");
FileUtils.copyInputStreamToFile(is, sourceFile);
XWPFTemplate template = XWPFTemplate.compile(sourceFile, config).render(dataMap);
//加水印
DocxUtil.setWordWaterMark(template.getXWPFDocument(), dataMap.get("auditStatus").toString(), DocxUtil.DEFAULT_FONT_COLOR);
//文件名
String fileName = "测试报告.docx";
// 使用 UTF-8 编码
String encodedFileName = URLEncoder.encode(fileName, "UTF-8").replaceAll("\\+", "%20");
// =================生成word到设置浏览默认下载地址=================
// 设置强制下载不打开
response.setContentType("application/force-download");
// 设置文件名
response.addHeader("Content-Disposition", "attachment;filename=\"" + encodedFileName + "\"");
out = response.getOutputStream();
template.write(out);
out.flush();
template.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (is != null) {
is.close();
}
if (out != null) {
out.close();
}
}
}合并单元格策略类
package com.szst.business.policy;
import com.alibaba.fastjson.JSON;
import com.deepoove.poi.data.RowRenderData;
import com.deepoove.poi.data.Rows;
import com.deepoove.poi.policy.DynamicTableRenderPolicy;
import com.deepoove.poi.policy.TableRenderPolicy;
import com.deepoove.poi.util.TableTools;
import com.szst.business.domain.BsReportData;
import org.apache.poi.xwpf.usermodel.*;
import org.springframework.util.CollectionUtils;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* @Description
* @Author admin
* @date 2021-11-25
*/
public class ReportDataPolicy extends DynamicTableRenderPolicy {
// 填充数据所在行数
int listsStartRow = 1;
@Override
public void render(XWPFTable table, Object data) throws Exception {
if (null == data) {
return;
}
List<BsReportData> list = JSON.parseArray(JSON.toJSONString(data), BsReportData.class);
if (!CollectionUtils.isEmpty(list)) {
table.removeRow(listsStartRow);
List<RowRenderData> dataList = new ArrayList<>();
for (BsReportData tmp : list) {
RowRenderData renderData = Rows.of(
tmp.getEmissionProcess(),
tmp.getFuelName(),
tmp.getIndexName(),
tmp.getIndexUnit(),
tmp.getTotalYearValue() == null ? "" : tmp.getTotalYearValue().toString()
).create();
dataList.add(renderData);
}
// 循环插入行
for (int i = dataList.size() - 1; i >= 0; i--) {
XWPFTableRow insertNewTableRow = table.insertNewTableRow(listsStartRow);
for (int j = 0; j < 5; j++) {
insertNewTableRow.createCell();
}
// 渲染一行数据
TableRenderPolicy.Helper.renderRow(insertNewTableRow, dataList.get(i));
}
//根据排放过程分组
Map<String, List<BsReportData>> processMap = list.stream().collect(Collectors.groupingBy(tmp -> tmp.getEmissionProcess()));
//根据排放过程+燃料名称分组
Map<String, List<BsReportData>> fuelMap = processMap.values().stream().flatMap(tmp -> tmp.stream()).collect(Collectors.groupingBy(tmp -> tmp.getEmissionProcess() + tmp.getFuelName()));
//获取key值组成新的list
List<String> processList = processMap.keySet().stream().collect(Collectors.toList());
// 获取key值组成新的list
List<String> fuelList = fuelMap.keySet().stream().collect(Collectors.toList());
// 处理合并
int mergeColumn = 0;
for (int i = 0; i < dataList.size(); i++) {
// 获取要合并的名称那一列数据 mergeColumn代表要合并的列,从0开始
String processName = dataList.get(i).getCells().get(mergeColumn).getParagraphs().get(0).getContents().get(0).toString();
for (int j = 0; j < processList.size(); j++) {
String process = String.valueOf(processList.get(j));
int listSize = Integer.parseInt(String.valueOf(processMap.get(processName).size()));
// 若匹配上 就直接合并
if (process.equals(processName) && listSize > 1) {
TableTools.mergeCellsVertically(table, 0, i + 1, i + listSize);
processList.remove(j);
break;
}
}
//处理第二列燃料合并
Object v1 = dataList.get(i).getCells().get(1).getParagraphs().get(0).getContents().get(0).toString();
String paramType = processName + "-" + v1;
for (int j = 0; j < fuelList.size(); j++) {
String key = fuelList.get(j);
List<BsReportData> tmpList = fuelMap.get(key);
String paramName = tmpList.get(0).getEmissionProcess() + "-" + tmpList.get(0).getFuelName();
if (paramType.equals(paramName) && tmpList.size() > 1) {
// 合并第1列的第i+1行到第i+unitSize行的单元格
TableTools.mergeCellsVertically(table, 1, i + 1, i + tmpList.size());
fuelList.remove(j);
break;
}
}
//处理垂直居中
for (int y = 0; y < 5; y++) {
XWPFTableCell cell = table.getRow(i + 1).getCell(y);
//垂直居中
cell.setVerticalAlignment(XWPFTableCell.XWPFVertAlign.CENTER);
//设置水平居中
// 获取单元格中的所有段落
List<XWPFParagraph> paragraphs = cell.getParagraphs();
// 遍历每个段落并设置对齐方式
for (XWPFParagraph paragraph : paragraphs) {
paragraph.setAlignment(ParagraphAlignment.CENTER);
}
}
}
}
}
}
生成水印工具类
package cn.green.carbon.module.assets.util;
import com.microsoft.schemas.vml.*;
import org.apache.poi.xwpf.model.XWPFHeaderFooterPolicy;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFHeader;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
/**
* @author admin
* @date 2024-12-31
*/
public class DocxUtil {
// 默认字体颜色
public final static String DEFAULT_FONT_COLOR = "#d8d8d8";
/**
* word文字水印(调用poi封装的createWatermark方法)
*
* @param doc XWPFDocument对象
* @param markStr 水印文字
*/
public static void setWordWaterMark(XWPFDocument doc, String markStr, String fontColor) {
XWPFParagraph paragraph = doc.createParagraph();
XWPFHeaderFooterPolicy headerFooterPolicy = doc.getHeaderFooterPolicy();
if (headerFooterPolicy == null) {
headerFooterPolicy = doc.createHeaderFooterPolicy();
}
//创建默认水印 - 填充颜色为黑色且不旋转
headerFooterPolicy.createWatermark(markStr);
// 获取默认页眉
// 注意:createWatermark 方法还会设置 FIRST 和 EVEN 页眉
// 但此代码不会更新那些其他页眉
XWPFHeader header = headerFooterPolicy.getHeader(XWPFHeaderFooterPolicy.DEFAULT);
paragraph = header.getParagraphArray(0);
// 获取 com.microsoft.schemas.vml.CTShape,其中填充颜色和旋转已设置
paragraph.getCTP().newCursor();
org.apache.xmlbeans.XmlObject[] xmlobjects = paragraph.getCTP().getRArray(0).getPictArray(0).selectChildren(
new javax.xml.namespace.QName("urn:schemas-microsoft-com:vml", "shape"));
if (xmlobjects.length > 0) {
CTShape ctshape = (CTShape) xmlobjects[0];
ctshape.setFillcolor(fontColor);
ctshape.setStyle(ctshape.getStyle() + ";rotation:315");
}
}
}

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









