







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
🚀 快速阅读
- 高效推理:Mini-InternVL 通过动态分辨率输入策略和像素洗牌操作,显著减少视觉标记数量,提升处理效率。
- 跨领域适应:基于知识蒸馏和转移学习技术,Mini-InternVL 能够快速适应不同领域的任务需求。
- 轻量级设计:Mini-InternVL 在保持较小模型参数量的同时,实现了与大型模型相近的性能,适合资源受限的环境。
正文(附运行示例)
Mini-InternVL 是什么
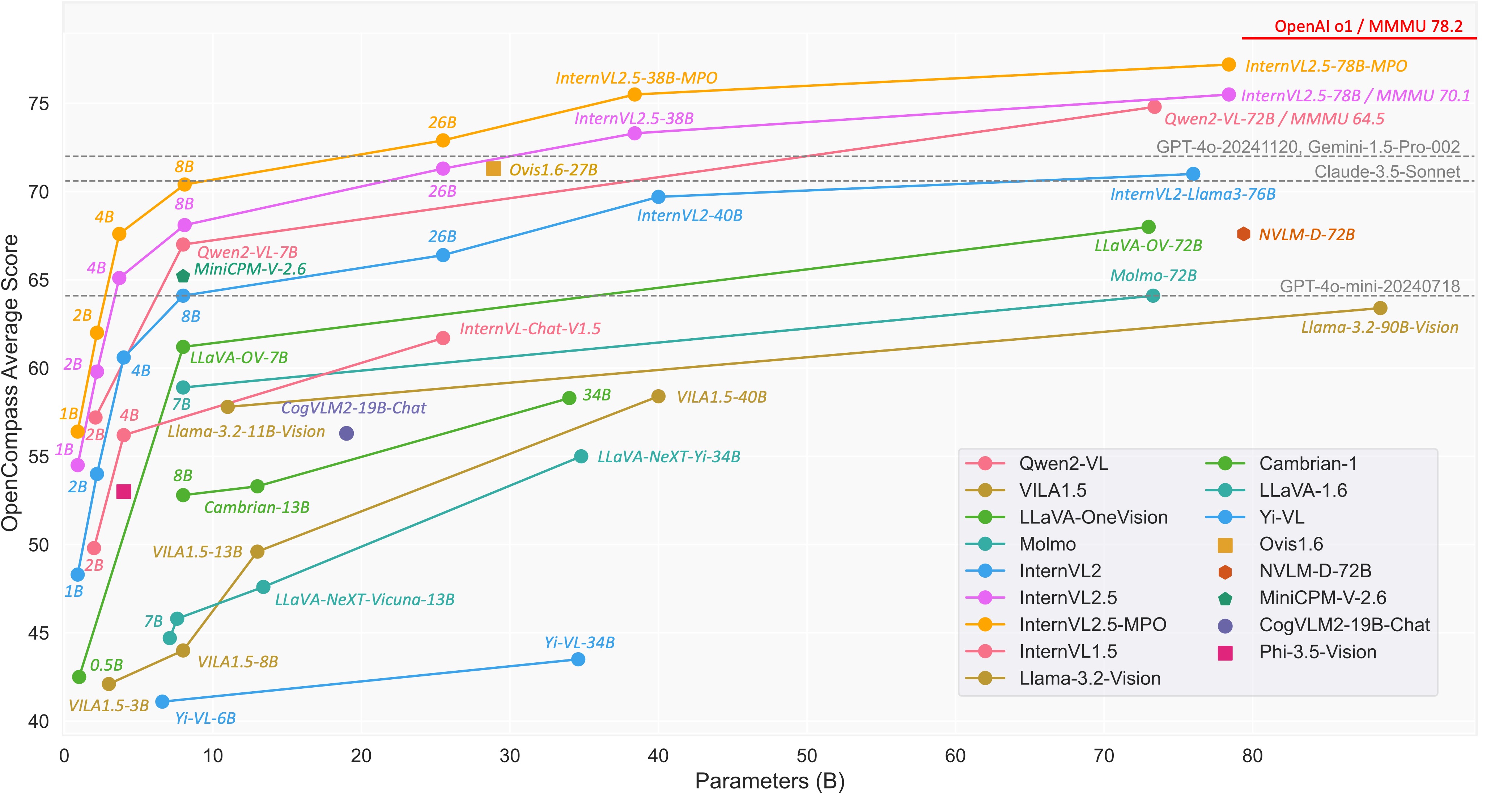
Mini-InternVL 是上海AI实验室与清华大学、南京大学等机构联合推出的轻量级多模态大型语言模型系列。它包含 1B、2B 和 4B 三个参数版本,能够在较小的参数量下实现较高的性能。其中,Mini-InternVL-4B 仅用 5% 的参数量就达到了 InternVL2-76B 约九成的性能。
Mini-InternVL 使用 InternViT-300M 作为视觉编码器,并结合不同的预训练语言模型,通过动态分辨率输入策略和像素洗牌操作来减少视觉标记数量,从而提高处理效率。该模型在多个多模态基准测试中表现出色,并且能够通过简单的转移学习框架适应特定领域的下游任务。
Mini-InternVL 的主要功能
- 多模态理解与推理:在给定图像和文本输入的情况下,理解和推理其中的语义关系。
- 跨领域适应性:基于知识蒸馏和转移学习技术,适应不同的领域和任务。
- 轻量级与高效性:Mini-InternVL 在保持较小模型参数量的同时,实现与大型模型相近的性能,适合在资源受限的环境中运行。
- 视觉指令调优:具备根据视觉指令进行调优的能力,更好地理解和执行用户基于图像的指令。
- 动态分辨率输入:支持动态分辨率输入策略,根据图像的长宽比将其分割成不同大小的瓦片,并进行相应的处理。
Mini-InternVL 的技术原理
- 视觉编码器(InternViT-300M):作为模型的核心部分,视觉编码器负责将输入图像转换为模型能理解的特征表示。InternViT-300M 是轻量级的视觉模型,基于知识蒸馏从更强大的 InternViT-6B 模型中继承丰富的视觉知识。
- 知识蒸馏:将大型教师模型的知识转移到小型学生模型中,让学生模型能继承教师模型的性能。
- MLP 投影器:将视觉编码器输出的特征向量投影到一个适合语言模型处理的空间中,使得视觉信息和文本信息能有效地融合和交互。
- 预训练语言模型(LLMs):Mini-InternVL 结合不同的预训练语言模型,如 Qwen2-0.5B、InternLM2-1.8B 和 Phi-3mini。
- 动态分辨率输入策略:根据图像的长宽比将其分割成 448×448 大小的瓦片,将瓦片组合成固定序列,最终生成一个 2688×896 分辨率的图像表示。
- 像素洗牌操作:将图像的分辨率降低到原来的四分之一,减少视觉标记的数量。
如何运行 Mini-InternVL
1. 安装依赖
首先,确保你已经安装了必要的依赖库:
pip install torch transformers
2. 加载模型
使用 HuggingFace 提供的预训练模型进行推理:
import torch
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained(
'OpenGVLab/InternVL2_5-8B',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(
'OpenGVLab/InternVL2_5-8B', trust_remote_code=True, use_fast=False)
3. 图像处理
使用动态分辨率输入策略处理图像:
from PIL import Image
image = Image.open('path_to_image.jpg').convert('RGB')
pixel_values = load_image(image, max_num=12).to(torch.bfloat16).cuda()
4. 进行推理
进行多模态对话推理:
question = '<image>\nPlease describe the image in detail.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
资源
- GitHub 仓库:https://github.com/OpenGVLab/InternVL
- HuggingFace 仓库:https://huggingface.co/collections/OpenGVLab/internvl-adaptation
- arXiv 技术论文:https://arxiv.org/pdf/2410.16261
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









