







 本文探讨了浮点数数据类型在编程中的表现,特别是关于其精度问题、科学计数法表示、IEEE-754标准以及浮点数加减法中交换律的不适用,解释了为何看似简单的算式可能导致计算误差。
本文探讨了浮点数数据类型在编程中的表现,特别是关于其精度问题、科学计数法表示、IEEE-754标准以及浮点数加减法中交换律的不适用,解释了为何看似简单的算式可能导致计算误差。
“95% of the folks out there are completely clueless about floatingpoint.”
– James Gosling, 1998-02-28
介绍
FLoating point是我们常用的一种数据类型,但是关于它的表达形式以及运算方式,我们真的理解清楚了吗?
请看下面的代码示例
#include <iostream>
int main()
{
float a = 0.0001;
float b = 10000000;
float c = 10000000.0001;
float d = a + c - b;
float e = c - b + a;
std::cout<<" a + c -b = "<<d<<std::endl;
std::cout<<" c - b + a = "<<e<<std::endl;
}
针对上面的代码,我们期待的结果是什么?d和e是一样的吗?
答案如下:

这个当然可以归咎于浮点数的精度问题,但是值得注意的是,这个过程中并没有出现overflow。(数字的表达范围在float数字的范围以内)。那什么导致了计算的误差呢?
浮点数介绍
参考加州大学CS61C课程介绍一下FLoating point。
首先,小数基于二进制可以通过类似于10进制数字的方式表达。但是,对应的问题是,表达的范围和精度都很受限。特别大的数和特别小的数通过有限的bits数都很难表达。

因此,我们想到了科学计数法,并引入了float数据类型的表达方式,我们的小数点的位置不是固定的,有别于int类型的数据。

引入了下列的float表达形式。基于32bit,我们可以表达有符号的,非常大范围的小数。8bit用于表达指数,剩余的用于表达底数。此外,针对enponent,它也应该是有符号的,但是,我们希望直接通过exponent的大小来判断数字的大小,所以,我们选择了包含bias的数字表达方式。

下面的slides介绍了浮点数的具体表达形式和计算案例。所有数字按照二进制的方式计算。


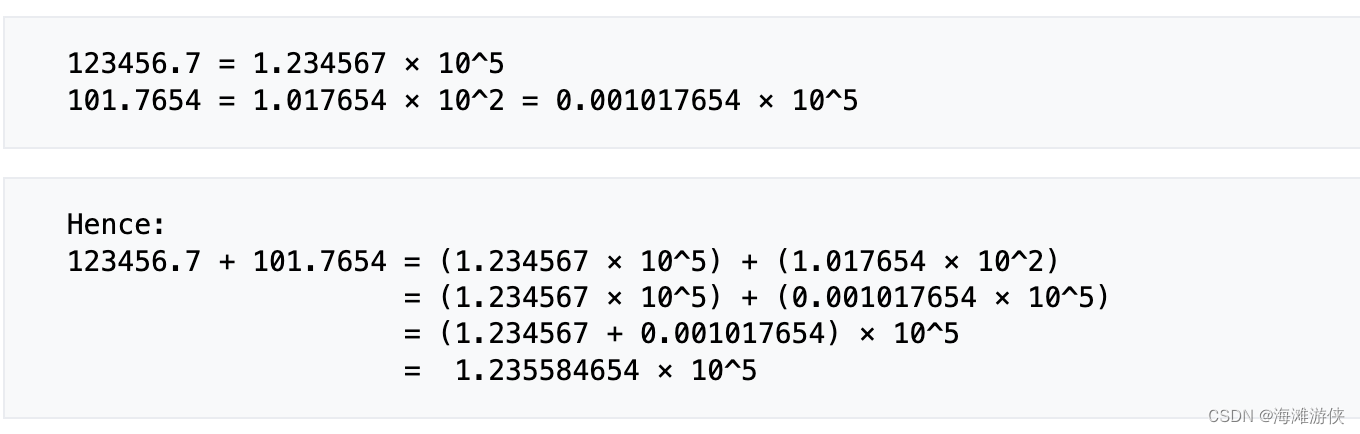
浮点数的加减法不符合交换律。

因为,浮点数在进行加减法时,要进行exponent大小的统一,基于此,进行底数的加减。所以,针对指数较小的数,为了保证指数的对齐,需要进行底数数字的右移,从而造成精度的损失。
参考资料:
https://en.wikipedia.org/wiki/Floating-point_arithmetic
IEEE-754 Floating Point Converter
Home | CS 61C Fall 2023https://en.wikipedia.org/wiki/Floating-point_arithmetic


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









