






提到大模型,Transformer是最核心的创新点,讲解Transformer的博文不少,但是,我还是想从个人视角,基于Attention is all you need这篇论文,讲解Transformer。
摘要
作者提到,针对sequence transduction的任务,CNN和RNN还是主要的模型组成部分,而目前性能最好的方案添加了attention机制。 作者进一步提出了transoformer,一个完全基于注意力机制的由编码器,解码器组成的单一网络。
证明这一网络架构优越性的就是它在WMT 2014 English-to-French translation (英法翻译)任务中,刷新了最好成绩。
读完abstract,我的认知是,这篇论文不是提出了attention机制,而是证明不依赖CNN,RNN,基于attention机制构造网络,单枪匹马,可以取得令人震惊的效果。
介绍
RNN,LSTM是机器翻译领域常用的网络结构,但是RNN无法有效的支持并行化,这让它处理长序列的句子非常有挑战。此前,attention机制在RNN网络中充当着辅助的角色,但是,本文证明,它可以“独档一面”。
背景
针对RNN的序列计算量太大的问题,一些工作尝试通过CNN解决,但是随着序列长度的增加,还是遇到序列距离较远,计算量大,相互关系的学习能力受限。但是,在transformer中,计算量被降低为常数。
In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions,
然后,作者引出self-attention的介绍
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.
接着再强调一下transformer有多牛。
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequencealigned RNNs or convolution. In the following sections, we w
这里其实有点奇怪,难道在作者心中,self-attetnion的重要性远高于multi-head attention?
Model architecture
关于模型结构的介绍,作者强调transformer依旧遵循encoder-decoder的设计框架,将输入序列进行映射成连续序列,然后再解码生成新的序列,并且还会基于此前生成的符号,作为生成下一输出的额外输入。
model is auto-regressive [10], consuming the previously generated symbols as additional input when generating the next.
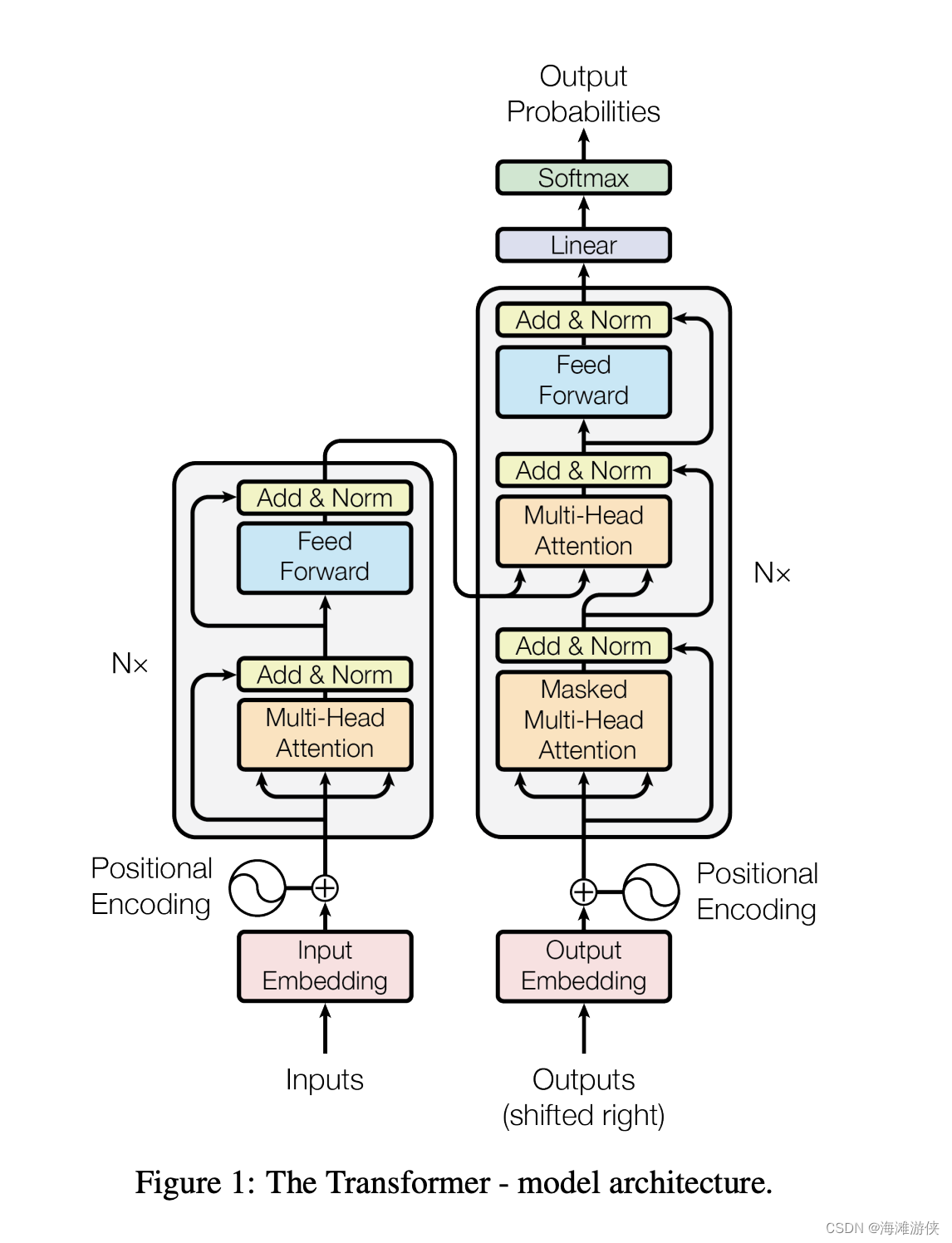
Transformer由若干个自注意力层和全连接层组成。
在这张图中,通过input embedding,词转换为向量,
解码器和编码器
编码器由6个相同的层组成,每个层包含2个子层,其中,第一层使用了多头注意力机制,第二个是全连接层 (fully connected feed-forward network), 此外,进过残差链接后,layernrom被使用。
batch norm: 将特定特征在mini batch中的均值和方差调整为0。 而layernorm是吧每一个样本调整为均值为0,方差为1。
在解码器中,可以看到相比于编码器,多了一个Masked-multi-head attention模块,它的作用在于隐藏未来信息,并对于编码器输出进行多头注意力操作。
scaled-dot-product attention
关于这个注意力机制的解释,最好的就是这个公式,针对每一个query,通过和Key进行点乘,得到每一个value的权重,再和value相乘,最后的输出是多个value的混合,混合中每个value的比例取决于query和Key的相似度。
当然,上述的过程中没有softmax以及dk的介绍,但这对应的也都是公式化的变换。总之,该过程,实际上只使用了两次矩阵乘法。
其中,这里作者之所以称这种方法为scaled。就是因为它除以了dk。
此外,为了保证t时刻的query只和此前时刻的key建立联系,我们使用了mask来屏蔽t时刻之后的key。
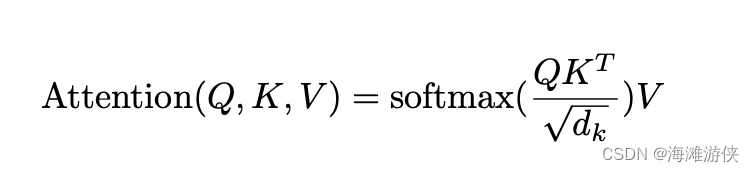
TODO: add image
Mulit-head attention
值得注意的是,上述流程其实没有很多可以学习的参数,因此参考卷积层多个通道,这里设计了多头注意力机制,通过进行QKV的线性映射,我们可以在更丰富的向量空间进行参数学习。
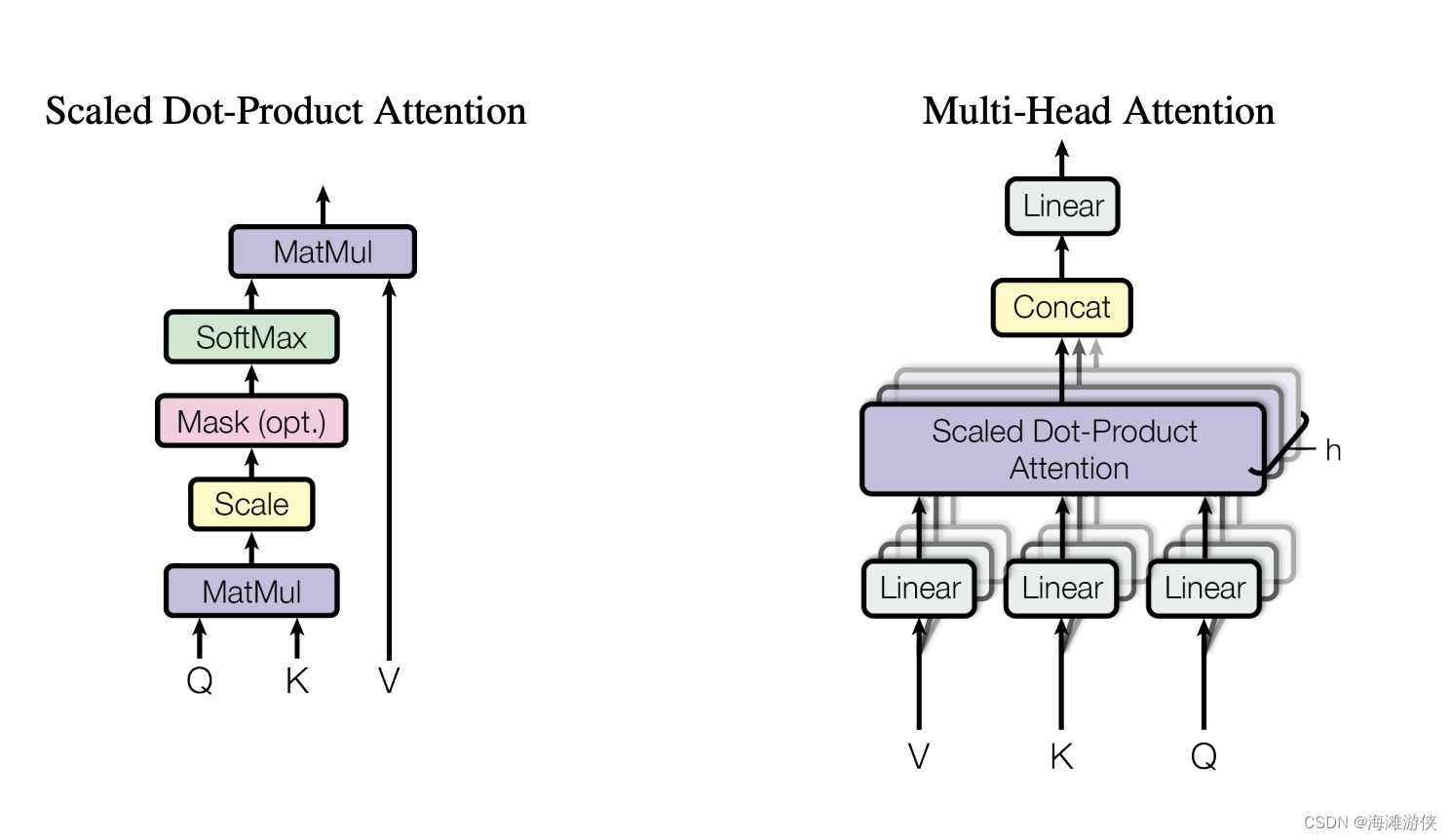
在transoformer中,包含了三个多头注意力模块,分别位于编码器,解码器,以及编码器和解码器的连接处。
其中编码器和解码器的注意力模块中,QKV一致。而在编码器和解码器的连接处,key和value来自编码器,query来自解码器的输入。它的目的就是有效获取编码器中的输出。
RNN和transoformer的处理时序信息的方式。
positional encoding
为了保证网络把输入的相对位置关系,我们需要将位置信息输入网络。通过不同频率的sin和cos信息,我们进行位置编码。
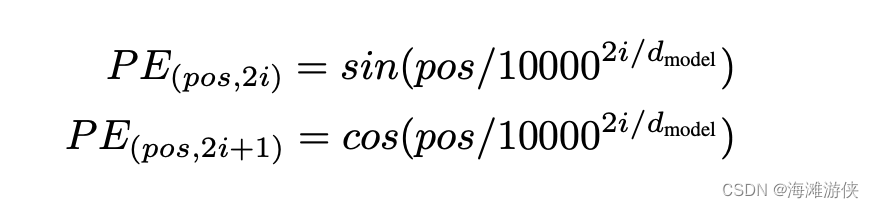
为什么使用自注意力机制?
作者提到使用自注意力机制的三个原因。一是自注意力机制每一层的计算复杂度较小,二是自注意力机制有利于序列操作的并行化。三是,长序列中元素相互关系连接的路径较短。而学习长序列的相互依赖关系是这类问题的关键。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









