







不会keras,slim,TFlearn…自己写了一些函数,当然这样的好处是能更清晰的看出网络结构
目前测试在cifar10上训练的准确率最高等达到93%,稳定在90%左右把(电脑渣,跑不动)
我的实现中用全局平均池化代替第一层全连接层,第二三层全连接用1x1卷积来代替
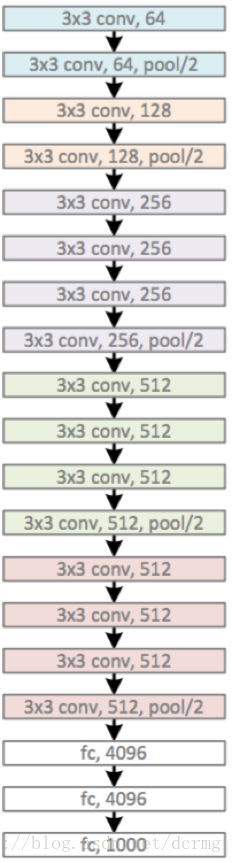
原本VGG16存在参数太多的问题,我做了一些调整,当然也加上了一些其他的尝试
首先是卷积层的通道数,考虑到cifar10数据集不太复杂,所以卷积的数量做了一定的调整
大致上来说减半了
整个网络参数集中在三个巨大的全连接层,这里我舍弃掉了全连接层
第一层全连接层用全局平均池化代替
第二层和第三层全连接层用kernel=1x1的卷积代替
使用了BatchNormalizarion,ExponentialDecay,Exponentia来加快收敛和提高准确率
学习率上还使用了Warmup,在开始两个epoch学习率线性上升,随后指数衰减
使用Dropout和L2_Regularizer来防止过拟合
每一组卷积后面添加SENet模块
训练的时候对数据进行随机剪裁,随机亮度调整,随机翻转,随机对比度饱和度和标准化
并且将图片resize为128x128训练网络(32x32的话后面几个卷积层特征图都变成1x1了)
当然为了方便定义网络后打印出结构(便于查错),在函数上有那么一点复杂
首先是一些函数方面,我自己按照我的习惯重写了一下
原始VGG16的结构:
我的网络结构:(程序本身的输出结果):
Net Structure Info:
[Layer 1 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 64, 64, 3)
[Layer 2 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 64, 64, 64)
[Layer 3 Info:] SENet,tensor=(?, 64, 64, 64)
[Layer 4 Info:] MaxPool2d ksize=3 strides=2,tensor=(?, 64, 64, 64)
[Layer 5 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 32, 32, 64)
[Layer 6 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 32, 32, 64)
[Layer 7 Info:] SENet,tensor=(?, 32, 32, 64)
[Layer 8 Info:] MaxPool2d ksize=3 strides=2,tensor=(?, 32, 32, 64)
[Layer 9 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 16, 16, 64)
[Layer 10 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 16, 16, 128)
[Layer 11 Info:] SENet,tensor=(?, 16, 16, 128)
[Layer 12 Info:] MaxPool2d ksize=3 strides=2,tensor=(?, 16, 16, 128)
[Layer 13 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 8, 8, 128)
[Layer 14 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 8, 8, 128)
[Layer 15 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 8, 8, 128)
[Layer 16 Info:] SENet,tensor=(?, 8, 8, 128)
[Layer 17 Info:] MaxPool2d ksize=3 strides=2,tensor=(?, 8, 8, 128)
[Layer 18 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 4, 4, 128)
[Layer 19 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 4, 4, 256)
[Layer 20 Info:] Conv2d kernel_size=3 strides=1,tensor=(?, 4, 4, 256)
[Layer 21 Info:] SENet,tensor=(?, 4, 4, 512)
[Layer 22 Info:] MaxPool2d ksize=3 strides=2,tensor=(?, 4, 4, 512)
[Layer 23 Info:] GlobalAvgPool2d,tensor=(?, 2, 2, 512)
[Layer 24 Info:] FullyConnection dim:256,tensor=(?, 1, 1, 512)
[Layer 25 Info:] FullyConnection dim:10,tensor=(?, 1, 1, 256)
[OUTPUT] tensor=(?, 10)
由于是十分类,所以最终输出为10.
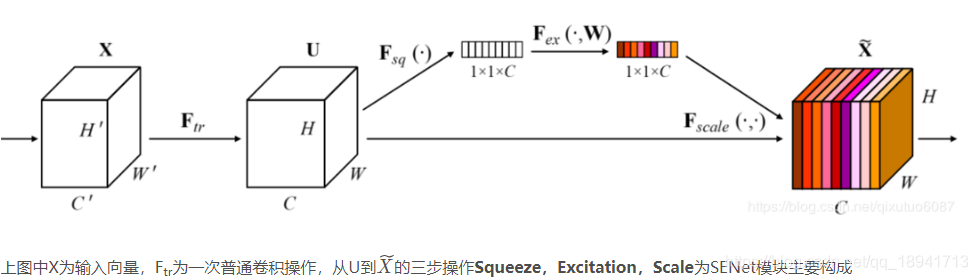
SENet模块的结构:
代码方面封装为class,结构看起来比较好
网络初始化的一些参数:
class CNN():
def __init__(self,drop_rate,is_training,regularizer=None,average_class=None,SE_rate=16,show_struct=False):
self.drop_rate=drop_rate #丢弃的概率
self.regularizer=regularizer #正则化
self.layer_index=1 #网络结构相关变量
self.is_training=is_training #dropout bn在训练和测试上有区别
self.SE_rate=16 #SE在Excitation的时候通道数的缩小比例
if average_class is None: #滑动平均类
self.ema=None
else:
self.ema=average_class.average
self.name_list=[] #结构名字
self.show_struct=show_struct #是否打印结构
网络参数初始化方面,小网络测试上xavier表现很好,tensorflow也有相关API调用
把几个函数搬运过来了
def Xavier(self): #Xavier初始化方式
return tf.contrib.layers.xavier_initializer()
def Relu(self,tensor):
return tf.nn.relu(tensor)
def Dropout(self,tensor):
return tf.layers.dropout(tensor,rate=self.drop_rate,training=self.is_training)
def Sigmoid(self,tensor):
return tf.nn.sigmoid(tensor)
然后是卷积 池化 BN GAP几个函数(略长)
def BatchNorm(self,tensor,upd=False):
name="Layer%d_BatchNorm"%self.layer_index
self.layer_index+=1
if upd:self.name_list.append("BatchNorm,input size="+str(tensor.shape))
with tf.variable_scope(name,reuse=tf.AUTO_REUSE):
return tf.layers.batch_normalization(tensor,training=self.is_training)
def Conv2d(self,tensor,output_channel,ksize,strides,norm=None,activation=tf.nn.relu,padding="VALID",upd=True):
#Conv-BN-Rrlu
name="Layer%d_Conv2d"%self.layer_index
self.layer_index+=1
if upd:self.name_list.append("Conv2d kernel_size=%d strides=%d,input size="%(ksize,strides)+str(tensor.shape))
with tf.variable_scope(name,reuse=tf.AUTO_REUSE):
input_channel=tensor.shape.as_list()[-1]
kernel=tf.get_variable("kernel",[ksize,ksize,input_channel,output_channel],initializer=self.Xavier())
bias=tf.get_variable("bias",[output_channel],initializer=tf.constant_initializer(0.01))
if self.ema is not None and is_training is False:
kernel=self.ema(kernel)
bias=self.ema(bias)
if self.regularizer:
tf.add_to_collection("losses",self.regularizer(kernel))
conv2d=tf.nn.conv2d(tensor,kernel,strides=[1,strides,strides,1],padding=padding)
bias_add=tf.nn.bias_add(conv2d,bias)
if norm is not None:
bias_add=norm(bias_add)
if activation is not None:
bias_add=activation(bias_add)
return bias_add
def MaxPool2d(self,tensor,ksize,strides,padding="VALID",upd=True):
name="Layer%d_MaxPool2d"%self.layer_index
self.layer_index+=1
if upd:self.name_list.append("MaxPool2d kernel_size=%d strides=%d,input size="%(ksize,strides)+str(tensor.shape))
with tf.variable_scope(name,reuse=tf.AUTO_REUSE):
return tf.nn.max_pool(tensor,ksize=[1,ksize,ksize,1],strides=[1,strides,strides,1],padding=padding)
def AvgPool2d(self,tensor,ksize,strides,padding="VALID",upd=True):
name="Layer%d_AvgPool2d"%self.layer_index
self.layer_index+=1
if upd:self.name_list.append("AvgPool2d kernel_size=%d strides=%d,input size="%(ksize,strides)+str(tensor.shape))
with tf.variable_scope(name,reuse=tf.AUTO_REUSE):
return tf.nn.avg_pool(tensor,ksize=[1,ksize,ksize,1],strides=[1,strides,strides,1],padding=padding)
def GlobalAvgPool2d(self,tensor,upd=True): #全局平均池化
name="Layer%d_GlobalAvgPool2d"%self.layer_index
self.layer_index+=1
if upd:self.name_list.append("GlobalAvgPool2d,input size="+str(tensor.shape))
with tf.variable_scope(name,reuse=tf.AUTO_REUSE):
shape=tensor.shape.as_list()
return tf.nn.avg_pool(tensor,ksize=[1,shape[1],shape[2],1],strides=[1,1,1,1],padding="VALID")
def FC_Conv(self,tensor,output_channel,upd=True): #1x1卷积代替全连接层
name="Layer%d_FC_Conv2d"%self.layer_index
self.layer_index+=1
if upd:self.name_list.append("FullyConnection dim:%d,input size="%output_channel+str(tensor.shape))
with tf.variable_scope(name,reuse=tf.AUTO_REUSE):
return self.Conv2d(tensor,output_channel=output_channel,ksize=1,strides=1,upd=False)
def PrintStructure(self):#打印网络结构
print("Net Structure Info:")
for i in range(len(self.name_list)):
print("[Layer%3d Info:] "%(i+1)+self.name_list[i])
print("[OUTPUT] tensor="+str(self.Forward.shape))
接下来是SENet模块
def SENet(self,tensor,upd=True): #Sequeeze and Excitation 子网络模块
name="Layer%d_SENet"%self.layer_index
self.layer_index+=1
if upd:self.name_list.append("SENet,input size="+str(tensor.shape))
input_channel=tensor.shape.as_list()[-1]
Squeese=self.GlobalAvgPool2d(tensor,upd=False)
Excitation=self.FC_Conv(Squeese,input_channel/self.SE_rate,upd=False)
BN=self.BatchNorm(Excitation,upd=False)
Relu=self.Relu(BN)
Excitation=self.FC_Conv(Relu,input_channel,upd=False)
BN=self.BatchNorm(Excitation,upd=False)
Sigmoid=self.Sigmoid(BN)
return Sigmoid*tensor
然后是VGG16,按照结构写起来是很流畅的
def VGG16(self,tensor):
Conv2d=self.Conv2d(tensor,output_channel=64,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
Conv2d=self.Conv2d(Relu,output_channel=64,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
SE=self.SENet(Relu)
Pool2d=self.MaxPool2d(SE,ksize=3,strides=2,padding="SAME")
Conv2d=self.Conv2d(Pool2d,output_channel=64,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
Conv2d=self.Conv2d(Relu,output_channel=64,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
SE=self.SENet(Relu)
Pool2d=self.MaxPool2d(SE,ksize=3,strides=2,padding="SAME")
Conv2d=self.Conv2d(Pool2d,output_channel=128,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
Conv2d=self.Conv2d(Relu,output_channel=128,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
SE=self.SENet(Relu)
Pool2d=self.MaxPool2d(SE,ksize=3,strides=2,padding="SAME")
Conv2d=self.Conv2d(Pool2d,output_channel=128,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
Conv2d=self.Conv2d(Relu,output_channel=128,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
Conv2d=self.Conv2d(Relu,output_channel=128,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
SE=self.SENet(Relu)
Pool2d=self.MaxPool2d(SE,ksize=3,strides=2,padding="SAME")
Conv2d=self.Conv2d(Pool2d,output_channel=256,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
Conv2d=self.Conv2d(Relu,output_channel=256,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
Conv2d=self.Conv2d(Relu,output_channel=512,ksize=3,strides=1,padding="SAME")
BN=self.BatchNorm(Conv2d)
Relu=self.Relu(BN)
SE=self.SENet(Relu)
Pool2d=self.MaxPool2d(SE,ksize=3,strides=2,padding="SAME")
GAP=self.GlobalAvgPool2d(Pool2d)
FC=self.FC_Conv(GAP,256)
BN=self.BatchNorm(FC)
Relu=self.Relu(BN)
Dropout=self.Dropout(Relu)
FC=self.FC_Conv(Dropout,10)
self.Forward=tf.reshape(FC,[-1,10])
self.PrintStructure()
return self.Forward
然后就是学习率,优化器,正则化,前向预测,准确率等一些用于训练和评估的代码
x=tf.placeholder(tf.float32,[None,64,64,3])
y=tf.placeholder(tf.float32,[None,10])
is_training=tf.placeholder(tf.bool)
train_epoches=85
batch_size=60
batch_num=int(cifar10.train.num_examples/batch_size)
#预热的指数衰减学习率
global_step=tf.Variable(0,trainable=False)
warmup_step=batch_num*2
learning_rate_base=0.02
learning_rate_decay=0.95
learning_rate_step=batch_num
learning_rate=exponential_decay_with_warmup(warmup_step,learning_rate_base,global_step,learning_rate_step,learning_rate_decay)
#正则化和前向预测
regularizer=tf.contrib.layers.l2_regularizer(0.006)
forward=CNN(drop_rate=0.3,is_training=is_training,show_struct=True,SE_rate=32).VGG16(x)
#滑动平均
moving_average_decay=0.999
ema=tf.train.ExponentialMovingAverage(moving_average_decay,global_step)
ema_op=ema.apply(tf.trainable_variables())
prediction=tf.nn.softmax(forward)
correct_prediction=tf.equal(tf.argmax(prediction,1),tf.argmax(y,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#损失函数和优化器
momentum=0.9
cross_entropy=tf.losses.softmax_cross_entropy(onehot_labels=y,logits=forward,label_smoothing=0.1)
l2_regularizer_loss=tf.add_n(tf.get_collection("losses"))
loss_function=cross_entropy+l2_regularizer_loss
update_ops=tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
optimizer=tf.train.MomentumOptimizer(learning_rate,momentum).minimize(loss_function,global_step=global_step)
#模型可持久化
if not os.path.exists(trained_model_path):
os.makedirs(trained_model_path)
saver=tf.train.Saver(tf.global_variables())
接下来训练网络
#开始进行训练
#trained_model_path='D:\\log\\cifar-10-batches-py\\trained_model_path_VGG16'
acc_SE_list=[0.0]
loss_SE_list=[0.0]
acc=0.0
loss=0.0
step=0
start_time=time.time()
gpu_options = tf.GPUOptions(allow_growth=True)
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) as sess:
sess.run(tf.global_variables_initializer())
trained_model_state=tf.train.get_checkpoint_state(trained_model_path)
if trained_model_state and trained_model_state.model_checkpoint_path:
saver.restore(sess,trained_model_state.model_checkpoint_path)
print("training start!")
for epoch in range(0,train_epoches):
for batch in range(batch_num):
xs,ys=cifar10.train.next_batch(batch_size)
sess.run([optimizer,ema_op],feed_dict={x:xs,y:ys,is_training:True})
if (step+1)%100==0:
xs,ys=cifar10.test.next_batch(batch_size)
loss,acc=sess.run([loss_function,accuracy],feed_dict={x:xs,y:ys,is_training:False})
decay=min(0.9,(1+step)/(10+step))
acc_SE_list.append(decay*acc_SE_list[-1]+(1-decay)*acc)
loss_SE_list.append(decay*loss_SE_list[-1]+(1-decay)*loss)
step+=1
print("Epoch:%d Speed:%.2f seconds per epoch -> Accuracy:%.3f Loss:%.3f"%(epoch+1,(time.time()-start_time)/(1+epoch),acc,loss))
print("learning rate:%.7f "%(sess.run(learning_rate)))
saver.save(sess,os.path.join(trained_model_path,"trained_model_%d"%(epoch+1)))
print("model_%d saved"%(epoch+1))
print("training finished after %.2f seconds"%(time.time()-start_time))
由于batch_size很小,导致准确率波动比较大,准确率并不是很稳定
统计acc和loss变化的数组时采用滑动平均的方法,这样绘制出的曲线比较的光滑
以准确率来衡量网络的性能
,SE_AlexNet能达到86%准确率
而SE_VGG16达到了93.3%的准确率(测试集相差不多,这次没有过拟合问题)
当然因为上述原因并不能稳住,而且由于采用滑动平均,所以曲线里面也看不出来

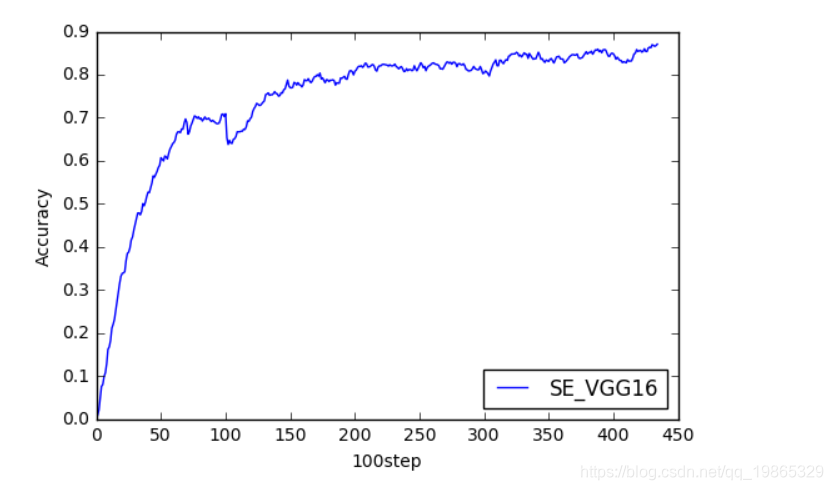
平均看起来后期也在逼近90%,等有空多跑几个epoch试一试
VGG16/VGG19验证了在一定范围内加深网络深度能提高网络的性能
当然更深的网络存在梯度下降和梯度爆炸等问题很难进行训练
后面也就诞生了Inception->ResNet->DenseNet->CliqueNet等一堆网络
其他网络有时间再来搞一搞














 2954
2954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









